#Carregando pacote
library(readr)
#Importando os dados
base = read_csv2("Base acidentes.csv")23 Testes de Qui-quadrado
A seguir vamos discutir três testes: teste de aderência, teste de homogeneidade e independência.
23.1 Testes de aderência
O objetivo dos testes de aderência é testar a adequabilidade de um modelo probabilístico a um conjunto de dados observados.
De forma geral, consideramos uma tabela de distribuição de frequências com \(k\) categorias (\(k \geq 2\)). Considere \(p_i\) a probabilidade especificada a categoria \(i\) de acordo com o modelo que desejamos verificar, \(i = 1, \ldots, k\).
As hipóteses associadas ao teste são
\[H_0: p_1 = p_{01}, \ldots, p_k = p_{0k}\] \[\times\] \[H_1: \mbox{Existe pelo menos uma diferente}.\]
Vamos discutir o teste em cima do seguinte problema: um guarda de trânsito desconfia que as probabilidades de acidentes de trânsito no quarto trimestre é maior do que nos anteriores. Ele alega que as probabilidades são de 2/10 para os três primeiros trimestres e 4/10 para o quarto, indicando, segundo ele, que existe o dobro de chance de se ter acidentes no último trimestre do ano.
Suponha que queremos verificar a afirmação do guarda de trânsito. Possuímos 4 categorias (4 trimestres) e de acordo com o modelo a ser testado, estamos interessado em verificar
\[H_0:p_1 = 2/10, p_2 = 2/10, p_3 = 2/10, p_4 = 4/10\] \[\times\] \[H_1: \mbox{Existe pelo menos uma diferente}.\]
Antes de testarmos estas hipóteses, podemos explorar um pouco os dados.
#Visualizando os dados
base# A tibble: 40 × 1
trim_acidentes
<chr>
1 Trim2
2 Trim4
3 Trim4
4 Trim4
5 Trim1
6 Trim4
7 Trim3
8 Trim3
9 Trim4
10 Trim2
# ℹ 30 more rows#Ativando pacote
library(janitor)
#Tabela de contingência
base |>
tabyl(var1 = trim_acidentes) |>
adorn_totals(where = "row") |> #adiciona uma linha com os totais
adorn_pct_formatting() #apresenta os percentuais na escala de 0 a 100 com o símbolo % trim_acidentes n percent
Trim1 7 17.5%
Trim2 8 20.0%
Trim3 7 17.5%
Trim4 18 45.0%
Total 40 100.0%Analisando a tabela acima, percebemos que de fato, parece haver uma maior quantidade de acidentes no último trimestre do ano, como o guarda desconfiava. Será que elas ocorrem com as probabilidades indicadas pelo guarda? Para respondermos este questionamento precisamos testar as hipóteses levantadas.
Para executarmos o teste de aderência, usaremos a função chisq.test do pacote stats.
A seguir, vamos apresentar os principais argumentos da função chisq.test:
- x - uma tabela com as frequências absolutas;
- p - um vetor com as probabilidades do modelo teórico para cada categoria,
- correct - um operador lógico indicando se será aplicado ou não a correção de continuidade (default - TRUE).
#Realizando o teste de aderência
chisq.test(x = table(base$trim_acidentes),
p = c(2/10,2/10,2/10,4/10),
correct = FALSE)
Chi-squared test for given probabilities
data: table(base$trim_acidentes)
X-squared = 0.5, df = 3, p-value = 0.9189A saída do teste contém várias informações: o valor da estatística do teste X-squared, o número de graus de liberdade da estatística de teste df e o p-valor associado as hipóteses especificadas.
Com base em um nível de significância de 5%, não rejeitamos \(H_0\) (p-valor = 0.9189 > 0,05 = \(\alpha\)), ou seja, não encontramos evidências nos dados para desacreditar no modelo do guarda.
23.2 Teste de homogeneidade
Suponha que possuímos \(r\) populações \(S_1, \ldots, S_r\). De cada subpopulação é extraída uma amostra de \(n_i\) elementos, \(i = 1, \ldots, r.\) Em seguida, é registrado a qual categoria da variável \(A\) cada elemento pertence (\(A_1, \ldots, A_c\)). O objetivo deste teste é verificar se a distribuição de probabilidade de \(A\) em cada subpopulação é a mesma.
As hipóteses associadas ao teste são
\[H_0: P_1(A_1) = \ldots = P_r(A_1), \ldots, P_1(A_c) = \ldots = P_r(A_c)\] \[\times\] \[H_1: \mbox{Existe pelo menos uma diferente}.\] em que \(P_i(A_j)\) é a probabilidade de um elemento da subpopulação \(i\) ser classificado na categoria \(A_j\), \(i = 1, \ldots, r\) e \(j = 1, \ldots, c\).
Vamos discutir o teste em cima do seguinte problema: um dono de uma fábrica que empacota cafés possui três máquinas (A, B e C) enchendo os pacotes. Os pacotes podem ser classificados no final como normais ou defeituosos. O dono da fábrica coletou uma amostra de 20 cafés da máquina A, 30 cafés da máquina B e 25 cafés da máquina C. Ele gostaria de saber se as máquinas produzem de forma semelhante. Como responder a este questionamento?
Notem que no nosso problema, cada máquina representa uma população, nesse caso, \(r = 3\) e a variável que está sendo observada é a classificação do café com duas possíveis categorias (normal ou defeituoso) \(c = 2\). Este cenário se aplica ao teste de homogeneidade, pois foi sorteado uma amostra fixada para cada subpopulação e então verificada a qual categoria (defeituoso ou não) cada elemento pertencia. Podemos traduzir o problema nas seguinte hipóteses
Hipótese: \[H_0: P_A(D) = P_B(D) = P_C(D), P_A(ND) = P_B(ND) = P_C(ND)\] \[\times\] \[H_1: \mbox{Existe pelo menos uma diferente}.\] Antes de testarmos estas hipóteses, podemos explorar um pouco os dados.
#Importando os dados
base_def = read_rds("Base defeito.rds")#Visualizando os dados
base_def# A tibble: 75 × 2
maquina defeito
<chr> <chr>
1 A ND
2 A ND
3 A ND
4 A ND
5 A ND
6 A ND
7 A ND
8 A ND
9 A ND
10 A D
# ℹ 65 more rows#Tabela de contingência
#Tabela de contingência
base_def |>
tabyl(var1 = defeito,
var2 = maquina) |>
adorn_percentages(denominator = "col") |> #calcula os % por coluna
adorn_pct_formatting(digits = 2) |> #apresenta os percentuais na escala de 0 a 100 com o símbolo %
adorn_ns() #inclui as frequências absolutas na tabela defeito A B C
D 10.00% (2) 50.00% (15) 8.00% (2)
ND 90.00% (18) 50.00% (15) 92.00% (23)#Ativando pacote
library(ggplot2)
#Gráfico de barras empilhadas
base_def |>
ggplot(mapping = aes(x = maquina,
fill = defeito)) +
geom_bar(position = "fill") +
labs(x = "Máquina",
y = "%",
fill = "Classificação") +
theme_minimal() +
scale_y_continuous(labels = scales::percent_format()) 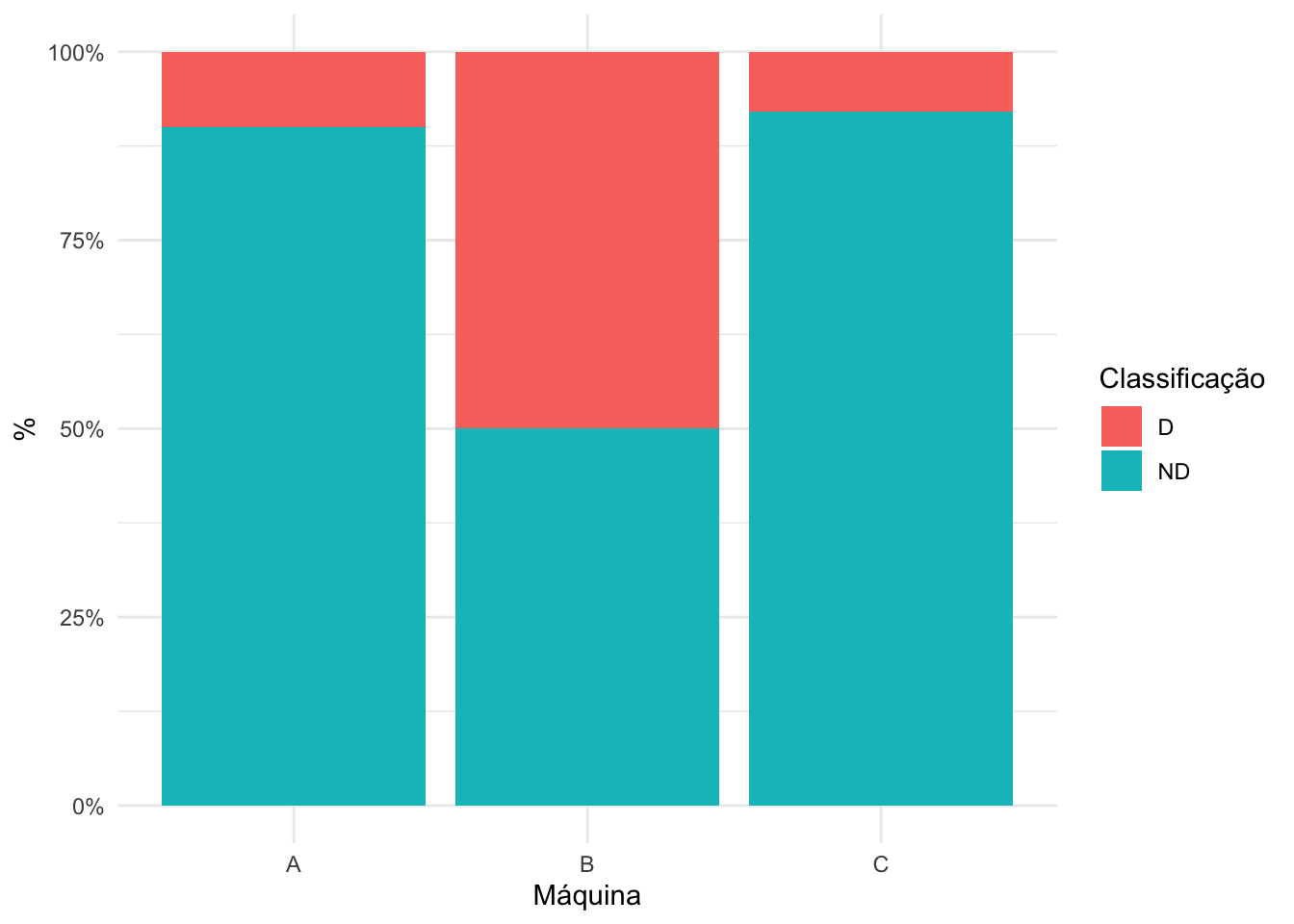
Notem que se analisarmos a tabela de contingência com as frequências absolutas não consegumos comparar bem as frequências observadas já que as subpopulações (máquinas) tem amostras de tamanhos diferentes, o que faz ser necessário trabalharmos com as porcentagens. Quando avaliamos as %, o comportamento das máquinas A e C parecem bastante semelhante, isto é, as proporções de defeituosos nas duas máquinas são parecidas, bem como a proporção de não defeituosos. O mesmo não se pode falar da máquina C, que apresentou proporções das categorias bem diferente das outras máquinas. Porém para respondermos o questionamento feito precisamos testar as hipóteses levantadas.
Para executarmos o teste de homogeneidade, também usaremos a função chisq.test do pacote stats.
A seguir, vamos apresentar os principais argumentos da função chisq.test para o teste de homogeneidade:
- x - uma tabela de contingência (dupla entrada) com as frequências absolutas;
- correct - um operador lógico indicando se será aplicado ou não a correção de continuidade (default - TRUE).
#Realizando o teste de homogeneidade
chisq.test(x = table(base_def$maquina, base_def$defeito),
correct = FALSE)
Pearson's Chi-squared test
data: table(base_def$maquina, base_def$defeito)
X-squared = 16.107, df = 2, p-value = 0.000318A saída do teste contém várias informações: o valor da estatística do teste X-squared, o número de graus de liberdade da estatística de teste df e o p-valor associado as hipóteses especificadas.
Com base em um nível de significância de 5%, rejeitamos \(H_0\) (p-valor = 0.000318 < 0,05 = \(\alpha\)), ou seja, encontramos evidências nos dados para acreditar que a distribuição de defeituosos e não defeituosos não é homogênea, isto é, existe pelo menos uma máquina com distribuição de probabilidade dos itens defeituoso diferente. Avaliando a tabela de contingência, vê-se claramente que a máquina B possui um comportamento diferente das demais.
23.3 Teste de independência
Suponha que selecionamos aleatoriamente \(n\) indivíduos de uma população. Vamos observar a qual categoria de duas variáveis cada indivíduo pertence. Suponha que a variável \(A\) possui \(c\) categorias e \(B\) possui \(r\) categorias. O objetivo deste teste é verificar se \(A\) e \(B\) são independentes.
As hipóteses associadas ao teste são
\[H_0: P(A_i \mbox{ e } B_j) = P(A_i)P(B_j) \qquad\] \[\times\] \[H_1: \mbox{Existe pelo menos uma diferente}.\] em que \(P(A_i)\) é a probabilidade de um elemento da população possuir característica \(A_i\) e \(P(B_j)\) é a probabilidade de um elemento da população possuir característica \(B_j\), \(i = 1, \ldots, c\) e \(j = 1, \ldots, r\).
Vamos discutir o teste em cima do seguinte problema: um pesquisador está interessado em saber se existe relação entre sexo e hábito de fuma. O pesquisador selecinou uma amostra de 70 indivíduos de uma específica cidade. Após isso, ele coletou informações do gênero e hábito de fumar das pessoas Ele gostaria de saber se existe relação entre o gênero e hábito de fumar. Como responder a este questionamento?
Se avaliarmos de forma superficial o problema acima, se assemelha com o problema discutido na secão anterior. Entretanto, temos uma diferença dundamental. Diferença entre os testes de homogeneidade e independência:
Teste de homogeneidade: selecionamos uma amostra de elementos de cada uma das \(r\) subpopulacões e distribuímos os elementos de cada uma dessas amostras segundo \(c\) categorias, ou seja, no início do experimento já está especificado o tamanho da amostra a ser coletado em cada subpopulação.
Teste de independência: distribuímos uma amostra de n elementos de “uma” população segundo as categorias da variável A e as categorias da variável B, ou seja, é coletado uma amostra da população e avaliado duas variáveis.
Notem que no nosso problema, a amostra foi coleta de uma única população (moradores da cidade) e foram observadas as categorias de duas variáveis: (masculino e feminino) gênero e (fumante e não fumante) hábito de fumar. Podemos traduzir o problema nas seguinte hipóteses
Hipótese: \[H_0: P(A_i \mbox{ e } B_j) = P(A_i)P(B_j), i = \{M,F\} \mbox{ e } j = \{F,NF\}\] \[\times\] \[H_1: \mbox{Existe pelo menos uma diferente}.\]
Antes de testarmos estas hipóteses, podemos explorar um pouco os dados.
#Importando os dados
base_fumo = read_table(file = "base fumo.txt")#Visualizando os dados
base_fumo# A tibble: 70 × 2
sexo fumante
<chr> <chr>
1 M F
2 M NF
3 M F
4 M F
5 M F
6 M F
7 M F
8 M F
9 M F
10 M F
# ℹ 60 more rows#Tabela de contingência
#Tabela de contingência
base_fumo |>
tabyl(var1 = fumante,
var2 = sexo) |>
adorn_percentages(denominator = "col") |> #calcula os % por coluna
adorn_pct_formatting(digits = 2) |> #apresenta os percentuais na escala de 0 a 100 com o símbolo %
adorn_ns() #inclui as frequências absolutas na tabela fumante F M
F 43.33% (13) 80.00% (32)
NF 56.67% (17) 20.00% (8)#Ativando pacote
library(ggplot2)
#Gráfico de barras empilhadas
base_fumo |>
ggplot(mapping = aes(x = sexo,
fill = fumante)) +
geom_bar(position = "fill") +
labs(x = "Sexo",
fill = "Fumante",
y = "%") +
theme_minimal() +
scale_y_continuous(labels = scales::percent_format())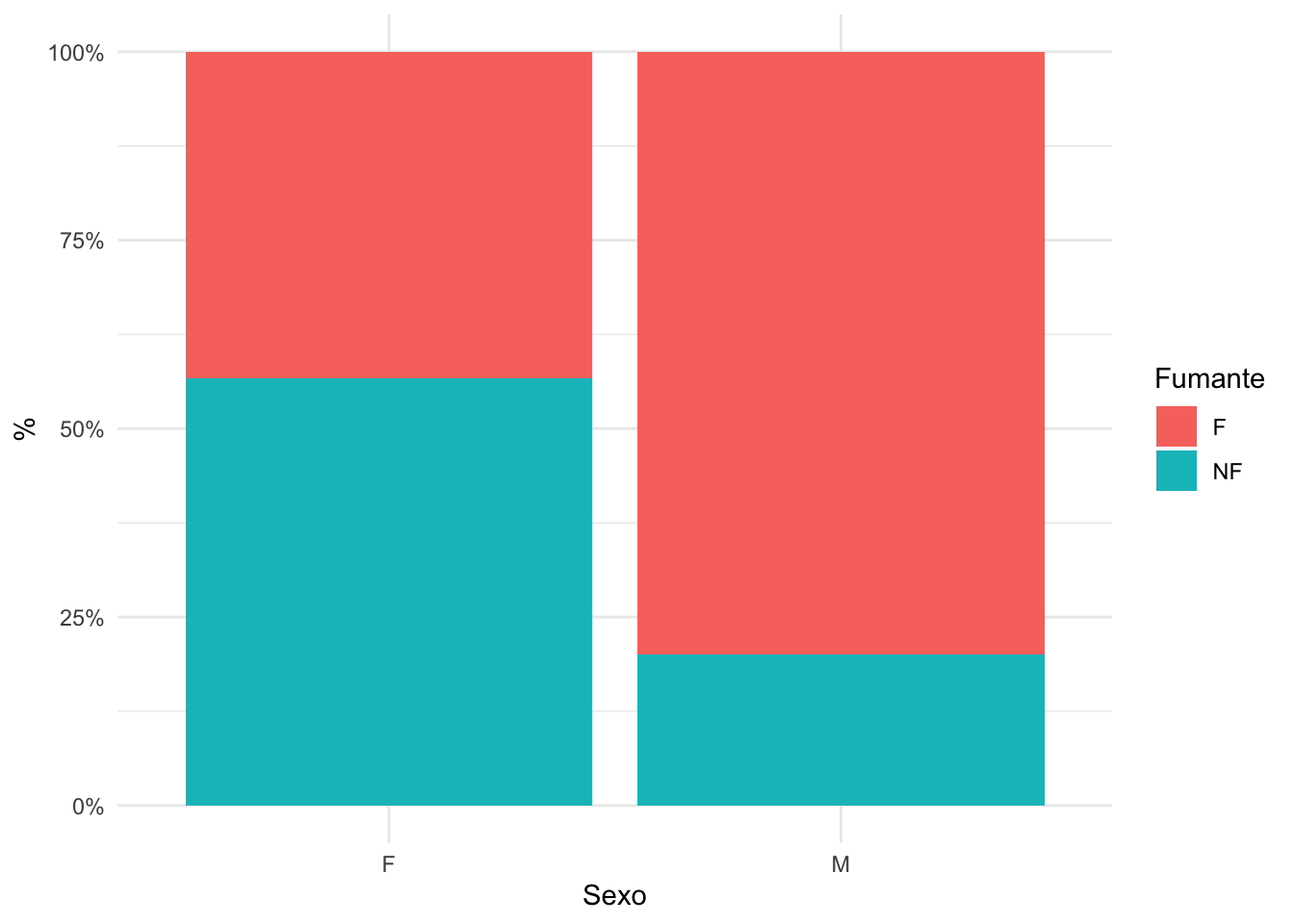
Para executarmos o teste de independência, também usaremos a função
chisq.testdo pacotestats.A seguir, vamos apresentar os principais argumentos da função
chisq.testpara o teste de homogeneidade:- x - uma tabela de contingência (dupla entrada) com as frequências absolutas;
- correct - um operador lógico indicando se será aplicado ou não a correção de continuidade (default - TRUE).
#Realizando o teste de independência
chisq.test(x = table(base_fumo$fumante, base_fumo$sexo),
correct = FALSE)
Pearson's Chi-squared test
data: table(base_fumo$fumante, base_fumo$sexo)
X-squared = 10.039, df = 1, p-value = 0.001533A saída do teste contém várias informações: o valor da estatística do teste X-squared, o número de graus de liberdade da estatística de teste df e o p-valor associado as hipóteses especificadas.
Com base em um nível de significância de 5%, rejeitamos \(H_0\) (p-valor = 0.001533 < 0,05 = \(\alpha\)), ou seja, encontramos evidências nos dados para acreditar que existe dependência entre as variáveis sexo e hábito de fumar.
23.4 Desafio
Resolva os exercícios 3 a 5 usando o arquivo Transportes.xlsx. Foram coletados informações de 80 usuários do App Taxi Rio, 50 do Uber e 30 do 99.
Um supermercado deseja investigar a preferência dos clientes em relação às marcas de pão disponíveis. Existem três marcas avaliadas: A, B e C, sendo que a marca C é produzida pela própria rede de supermercados. Foram registrados 150 compras de pães, onde cada compra corresponde a apenas uma das marcas. Dentre essas compras, 42 foram da marca A, 65 da marca B e 43 da marca C. Utilizando um nível de significância de 5%, é possível concluir se a preferência pelos pães é igual para todas as marcas?
Desejamos verificar se o número de defeitos por aparelho eletrônico possui uma distribuição Poisson com média 1,55. Uma amostra de 100 aparelhos foi observada e os seguintes números de defeitos por aparelhor foram registrados.
Número de defeitos 0 1 2 3 4 5 6 7 Número de aparelhos 25 25 18 13 4 2 2 1 Use em um nível de significância de 5%.
Você diria que existe relação entre App e escolaridade? Use um nível de significância de 5%.
Você diria que existe relação entre App e estado civil? Use um nível de significância de 5%.
Você diria que existe relação entre App e forma de pagamento? Use um nível de significância de 5%.