Nos capítulos anteriores, partimos do pressuposto de que o tamanho da amostra, \(n\), era conhecido e fixo. No entanto, em determinadas situações, pode ser necessário determinar o tamanho ideal da amostra a ser selecionada de uma população. Esse dimensionamento visa alcançar um erro de estimação predefinido, com um nível de confiança específico.
11.1 Determinando o n para estimação de uma média
Suponha que nosso objetivo seja estimar uma média populacional \(\mu,\) utilizando a média amostral \(\bar{X}\), a qual é calculada a partir de uma amostra de tamanho \(n\). Nesse contexto, desejamos determinar o tamanho adequado da amostra \(n\) de forma que
\[P(|\bar{X}-\mu| \leq \epsilon) \geq \gamma,\]
em que \(0 < \gamma < 1\) e \(\epsilon\) é o erro amostral máximo que admitimos. Vamos considerar que ambos os valores são fixados.
No Capíotulo 10 vimos que \(\bar{X} \sim N(\mu, \sigma^2/n)\), logo \(\bar{X} -\mu \sim N(0, \sigma^2/n)\) Deste modo, podemos escrever a equação acima da seguinte forma
Se dividirmos todos os termos por \(\sigma/\sqrt{n}\), temos que \[
P\left(\frac{\epsilon}{\sigma/\sqrt{n}} \leq \frac{\bar{X}-\mu}{\sigma/\sqrt{n}} \leq \frac{\epsilon}{\sigma/\sqrt{n}}\right) = P\left(\frac{\sqrt{n} \epsilon}{\sigma} \leq Z \leq \frac{\sqrt{n}\epsilon}{\sigma}\right) \approx \gamma,
\]
em que \(Z = (\bar{X}-\mu)/(\sigma/\sqrt{n})\). Vimos anteriormente que \(Z \sim N(0,1)\). Como \(\gamma\) é fixado, podemos obter o quantil \(z_{\gamma}\) da \(N(0,1)\), tal que \(P(-z_{\gamma} < Z < z_{\gamma}) = \gamma\), de modo que
\[n = \dfrac{\sigma^2 z^2_{\gamma}}{\epsilon^2}.\] Os termos presentes na equação acima, \(z_{\gamma}\) e \(\epsilon\) são conhecidos, porém a variância populacional \(\sigma^2\), provavelmente será desconhecida. Para estimar \(n\) de forma adequada, é necessário dispor de informações prévias sobre \(\sigma^2\), caso não exista, é possível coletar uma amostra piloto para estimá-la.
Exemplo: Suponha que uma amostra piloto de \(n=10\) extraída de uma população de interesse, forneceu os valores \(\bar{x} = 10\) e \(s^2 = 25\). Suponha que desejamos que a diferença entre a média estimada e a média real não exceda 1,1 unidades, com um nível de confiança de \(95\%\). Qual deveria ser o tamanho de \(n\) para estimarmos a média desta população atendendo as condições especificadas?
#Especificando os termos fixadose =1.1niv.conf = .95sigma2 =25#Obtendo o quantil da distribuição normal padrãoz =qnorm(p = (1-niv.conf)/2,mean =0,sd =1,lower.tail =FALSE)#Calculando o tamanho de nn = (sigma2*z^2)/e^2#Visualizando nn
[1] 79.36898
Precisaríamos entrevistar 80 unidades amostrais desta população. Para avaliarmos o impacto dos componentes envolvidos no cálculo do tamanho da amostra, vamos construir uma função que calcula \(n\) para estimar uma média populacional \(\mu\).
#Criando a função que calcula ntam_amostra =function(e,sigma2, niv.conf){#obtendo z z =qnorm(p = (1-niv.conf)/2,mean =0,sd =1,lower.tail =FALSE)#calculando n n = (sigma2*z^2)/e^2return(n)}#Aplicando a função nos dados fornecidos no exemplotam_amostra(e =1.1,niv.conf = .95,sigma2 =25)
[1] 79.36898
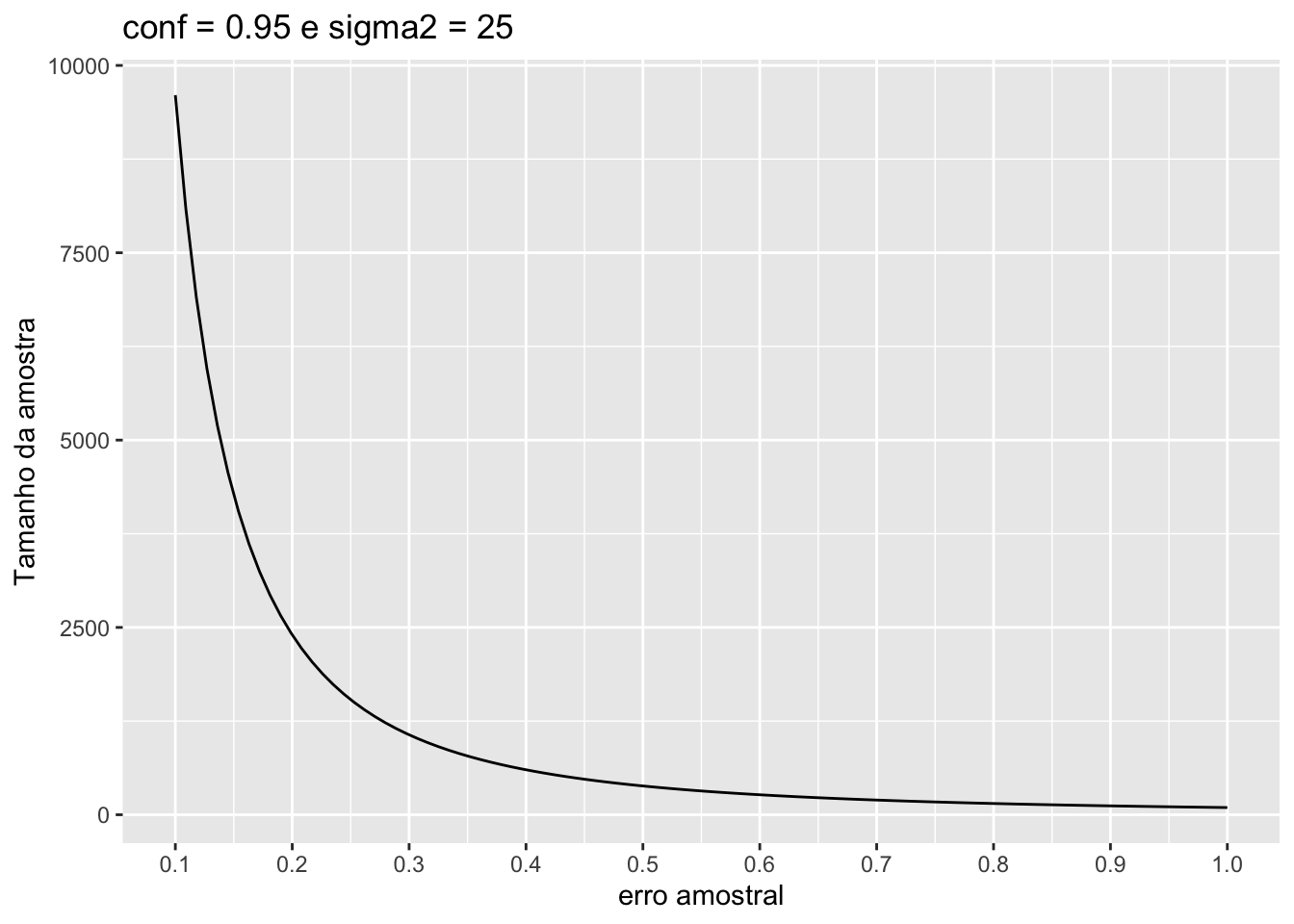
Qual o impacto no cálcuo do \(n\) com a diminuição de \(\epsilon,\) isto é, se desejarmos que o erro amostral (diferença entre o valor estimado e o valor real) seja menor. Para entender um pouco melhor, vamos plotar o gráfico do valor de \(n\) em função dos valores de \(\epsilon\). Avalie o comportamento de \(n\) para \(0.1 < \epsilon < 1\).
#Ativando pacotelibrary(ggplot2)library(tibble)#Plotando a funçãoggplot(data =tibble(x=c(0.1,1)),mapping =aes(x = x)) +stat_function(fun = tam_amostra,args =list(niv.conf =0.95,sigma2 =25)) +labs(y ="Tamanho da amostra",x ="erro amostral",title ="conf = 0.95 e sigma2 = 25") +scale_x_continuous(breaks =seq(from =0, to =1, by = .1))
Percebemos pelo gráfico acima que \(n\) assume valores altos a medida que \(\epsilon \rightarrow 0\). Com a função criada é possível examinarmos o impacto de outras quantidades envolvidas no problema no valor final de \(n\).
11.2 Determinando o n para estimação de uma proporção
Como discutido no Capítulo 10, a proporção é uma média para um caso particular de \(X\), isto é, quando \(X\) representar uma variável definida como \[X = \left \{
\begin{array}{cl} 1, & \mbox{se o indivíduo possui a característica de interesse} \\ 0, & \mbox{caso contrário}. \\
\end{array}
\right.\]
Nesse contexto, \(\sigma^2 = p(1-p)\) e de forma direta, é possível reescrever a fórmula do cálculo do tamanho amostra como
Como \(p\) é a proporção verdadeira de indivíduos que possuem a característica de interesse, \(p\) é desconhecida e é o nosso objeto de interesse. Neste caso podemos adotar duas possibilidades. A primeira seria realizar uma amostra piloto e utilizar \(\hat{p}\) ou pegar alguma informação prévia sobre \(p\). Esta abordagem é conhecida como otimista e deste modo
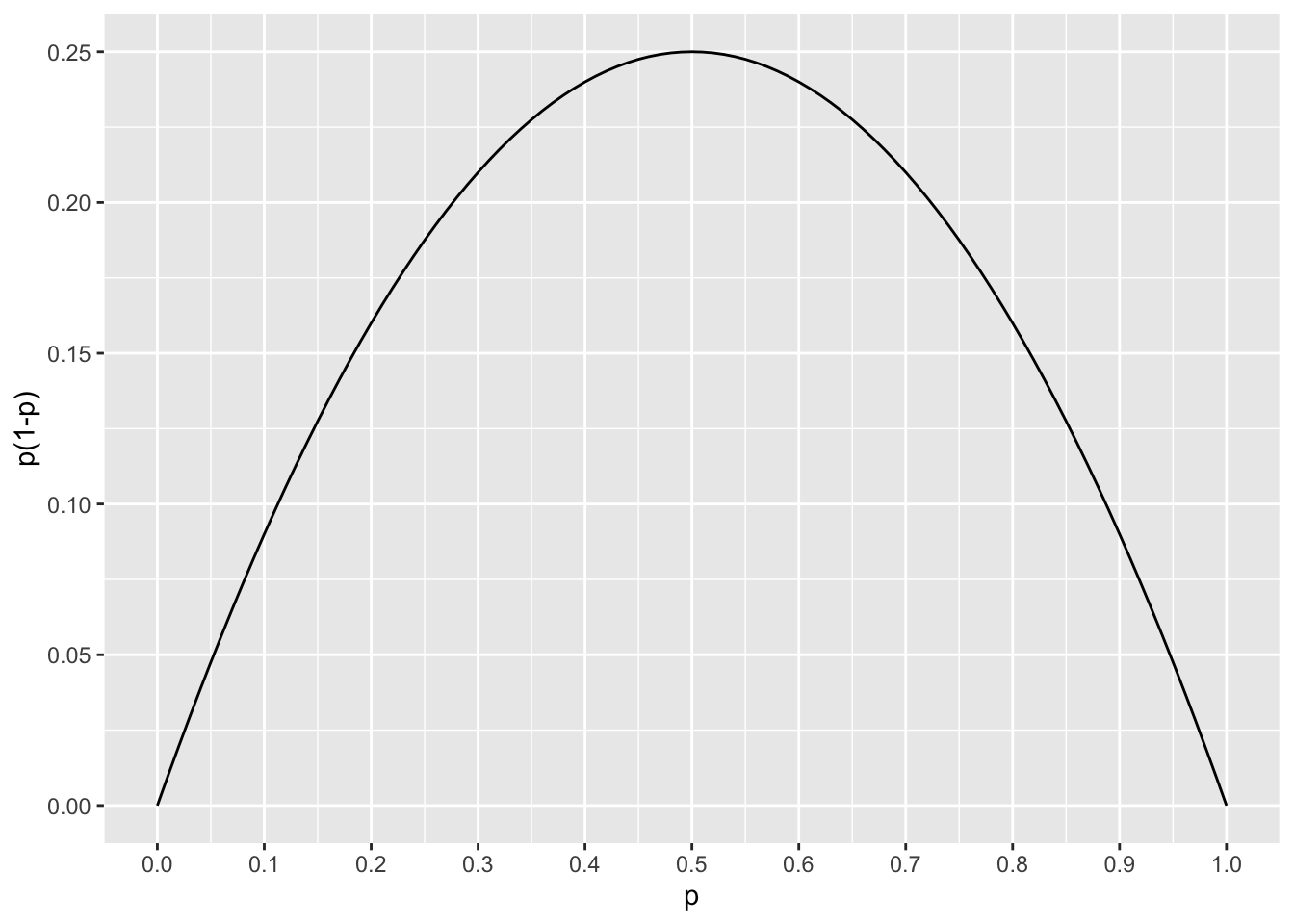
Outra possibilidade é adotar o valor de \(p\) que faz com que a variância \(p(1-p)\) seja a maior possível. Vamos avaliar o comportamento de \(p(1-p)\) em função da variação de \(p\).
#função p(1-p)fp =function(p){ aux = p*(1-p)return(aux)}#Plotando a funçãoggplot(data =tibble(x=c(0,1)),mapping =aes(x = x)) +stat_function(fun = fp) +labs(y ="p(1-p)",x ="p") +scale_x_continuous(breaks =seq(from =0, to =1, by = .1))
Claramente, pela figura acima, percebemos que o maior valor de \(p(1-p)\) ocorre quando \(p=0.5\). Chamamos essa abordagem de conservadora e deste modo \[n = \dfrac{0,5(1-0,5) z^2_{\gamma}}{\epsilon^2} = \dfrac{z^2_{\gamma}}{4\epsilon^2}.\]
Exemplo: Suponha que estamos interessados em estimar a porporção de alunos da UFF interessados em dar continuidade nos estudos após o término da graduação. Desejamos que a proporção estimada não difira da verdadeira proporção em mais de 0,05, com um nível de confiança de 0,95. Quantos alunos devem ser entrevistados?
#Especificando os termos fixadose =0.05niv.conf =0.95#Obtendo o quantil da distribuição normal padrãoz =qnorm(p = (1-niv.conf)/2,mean =0,sd =1,lower.tail =FALSE)#Calculando o tamanho de nn = z^2/(4*e^2)#Visualizando nn
[1] 384.1459
Logo, precisaríamos entrevistar 385 alunos para estimarmos a proporção de alunos da UFF interessados em dar continuidade nos estudos após o término da graduação, de modo que a diferença entre a proporção estimada e a real fosse no máximo de 0,05 com uma confiança de \(95\%\).
11.3 Desafio
Suponha que o ministério da saúde deseja saber a quantos voluntários se deva aplicar uma vacina, de modo que a proporção de indivíduos imunizados na amostra difira de menos de 3% da proporção verdadeira de imunizados na população, com probabilidade 95%. Qual o tamanho da amostra devemos trabalhar?
Avalie o impacto de \(\hat{p}\) no tamanho de \(n\), assumindo que \(\gamma = 98\%\) e o erro amostral é de 0,05 para o çalculo do tamanho da amostra para estimar a proporção num cenário otimista.
Suponha que uma amostra piloto de \(n=25\) extraída dos moradores do Ingá, forneceu os valores \(\bar{x} = 45,7\) anos e \(s = 50\) anos. Suponha que desejamos que a diferença entre a idade média estimada e a idade média real da população não exceda 2 anos, com um nível de confiança de \(98\%\). Qual deveria ser o tamanho de \(n\) para estimarmos a idade média desta população atendendo as condições especificadas?