Nesta seção iniciaremos a discussão do problema de se comparar duas populações. Nosso objetivo é verificar afirmações feitas sob dois parâmetros populacionais.
Vamos discutir o problema de se comparar duas variâncias de populações normais. O intuito de fazermos esta comparação, reflete diretamente na estatística de teste que será usada no teste de comparação de médias.
O dono de uma fábrica, possui duas máquinas empacotando um determinado produto K. O dono da fábrica coletou a informação do peso de 25 pacotes produzidos pela máquina A e 20 pacotes produzidos pela máquina B. O produtor quer saber se as máquinas estão produzindo da mesma forma, ou seja, se as médias dos pesos dos pacotes produzidos pelas máquinas são iguais. Só que para respondermos esta pergunta, precisamos inicialmente verificar se a variância do peso dos pacotes produzidos pelas máquinas são iguais ou diferentes.
Suponha que queremos verificar se as variâncias dos pesos dos pacotes nas duas populações (máquina A e máquina B) são diferentes. Deste modo, estamos interessado em verificar
Para verificarmos as hipóteses acima, utilizaremos um teste de hipóteses que possui um pré-requisito, isto é, o teste assume que as variâncias que serão comparadas são parâmetros de variáveis aleatórias com distribuição normal independentes.
Sob a suposição de igualdade das variâncias, a estatística de teste dada por:
\[W = \frac{S_1^2}{S_2^2} \sim F(n-1,m-1),\] em que \(S_i^2\) é a variância amostral da \(i\)-ésima população, \(i\) = 1,2, \(n\) é o tamanho da população 1 e \(m\) é o tamanho da população 2.
A independência é fácil de ser assumida, uma vez que as máquinas produzem pacotes de café separadamente. Com relação a normalidade, devemos verificar se a variável peso do pacote produzido pela Máquina A possui distribuição normal e também devemos verificar se a variável peso do pacote produzido pela máquina B possui distribuição normal.
Atividade 1: Importem o arquivo Maquinas.txt e armazenem em um objeto chamado base.
#Visualizando o objetobase
# A tibble: 45 × 3
Maquina Peso Defeito
<chr> <dbl> <dbl>
1 A 107. 0
2 B 144. 0
3 A 97.8 1
4 B 137. 0
5 A 101. 0
6 A 94.5 0
7 B 134. 1
8 A 99.9 0
9 A 94.4 0
10 B 141. 1
# ℹ 35 more rows
Vamos utilizar as ferramentas previamente discutidas para checar a normalidade em cada uma das populações.
#Carregando pacotelibrary(ggpubr)
Loading required package: ggplot2
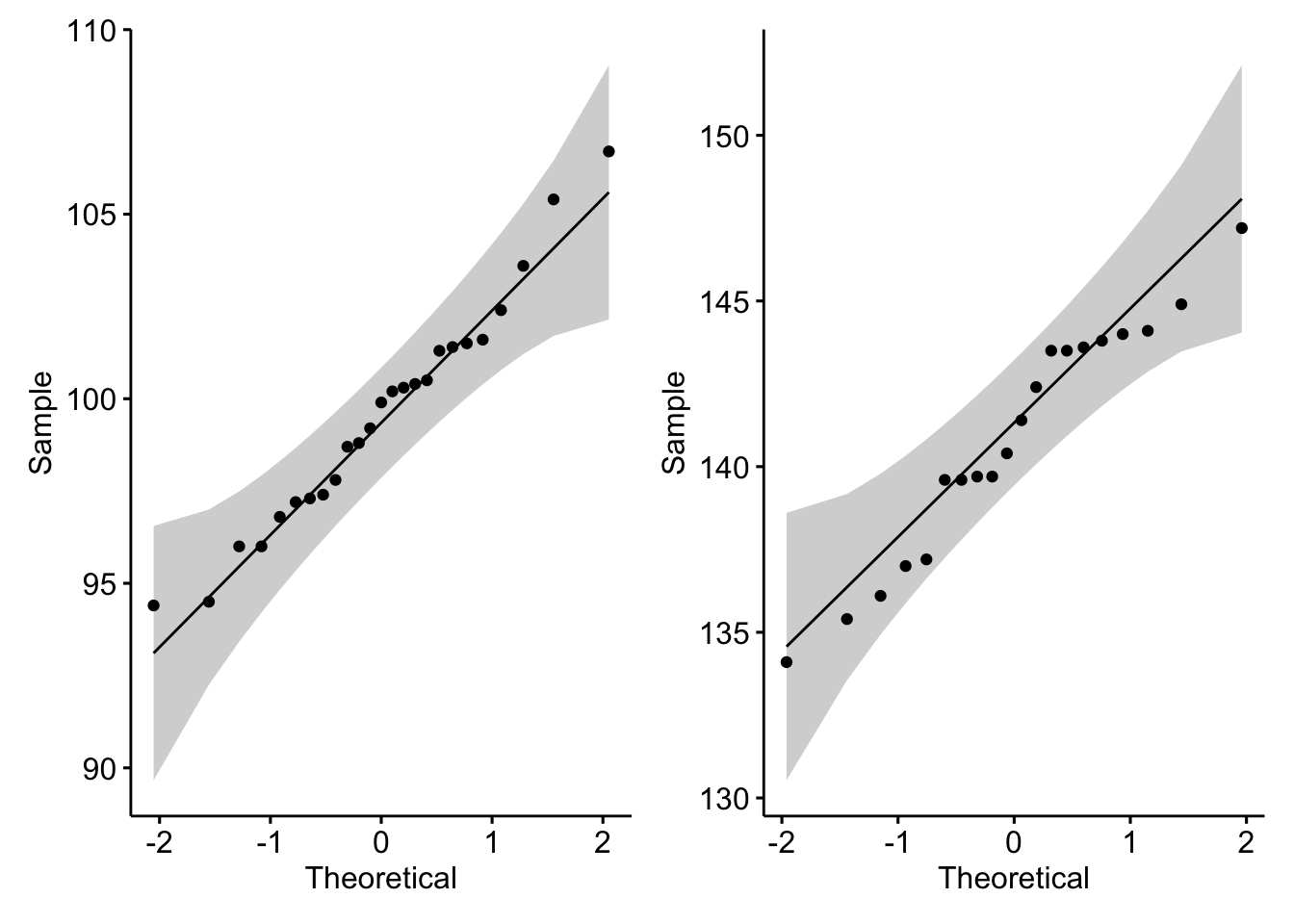
#Criando um tibble somente com as informações da máquina ApesoA = base |>filter(Maquina =="A")#Criando um tibble somente com as informações da máquina BpesoB = base |>filter(Maquina =="B")#Criando um qq-plot com o ggpubr para a população 1qq1 =ggqqplot(pesoA$Peso)#Criando um qq-plot com o ggpubr para a população 2qq2 =ggqqplot(pesoB$Peso)#Carregando pacotelibrary(patchwork)#Plotando os qqplotsqq1 + qq2
#Teste de normalidade para a população 1ks.test(x = pesoA$Peso, "pnorm", mean =mean(pesoA$Peso, na.rm =TRUE), sd =sd(pesoA$Peso, na.rm =TRUE))
Warning in ks.test.default(x = pesoA$Peso, "pnorm", mean = mean(pesoA$Peso, :
ties should not be present for the Kolmogorov-Smirnov test
Asymptotic one-sample Kolmogorov-Smirnov test
data: pesoA$Peso
D = 0.096908, p-value = 0.973
alternative hypothesis: two-sided
#Teste de normalidade para a população 2ks.test(x = pesoB$Peso, "pnorm", mean =mean(pesoB$Peso, na.rm =TRUE), sd =sd(pesoB$Peso, na.rm =TRUE))
Warning in ks.test.default(x = pesoB$Peso, "pnorm", mean = mean(pesoB$Peso, :
ties should not be present for the Kolmogorov-Smirnov test
Asymptotic one-sample Kolmogorov-Smirnov test
data: pesoB$Peso
D = 0.17019, p-value = 0.6085
alternative hypothesis: two-sided
Para verificar, inicialmente plotamos um qq-plot do peso do pacote em cada máquina, com suas respectivas bandas de confiança. Se analisarmos os dois gráficos, eles parecem indicar que a suposição de normalidade da variável peso do pacote em ambas as populações é razoável. Para confirmar esta hipótese, realizamos o teste de Kolmogorov-Smirnov em cada população e com base em um nível de significância (\(\alpha\)) de 5%, como o p-valor = 0,973 (Máquina A) e o p-valor = 0,6085 (Máquina B) é maior do que \(\alpha\), não rejeitamos \(H_0\), ou seja, não existe evidências para desconfiarmos que a amostra não seja proveniente de uma distribuição normal.
Deste modo, podemos partir para o testar a afirmação sobre igualdade das variâncias.
Antes de executarmos o teste de hipóteses, podemos realizar algumas análises descritivas.
# A tibble: 2 × 3
Maquina variancia n
<chr> <dbl> <int>
1 A 9.65 25
2 B 12.7 20
As variâncias parecem iguais?
Para executarmos o teste de comparação de variâncias, usaremos a função VarTest do pacote DescTools.
A seguir, vamos apresentar os principais argumentos da funçãoVarTest:
- x - o vetor com a amostra da população 1;
- y - o vetor com a amostra da população 1;
- ratio - o valor da razão dos dois parâmetros de variância que definem as hipóteses (default = 1);
- alternative - argumento que define se o teste é bilateral ou unilateral a esquerda e a direita (default = bilateral - two.sided).
- conf.level - argumento que define o nível de confiança para o intervalo de confiança da razão das duas variâncias.
#Carregando o pacotelibrary(DescTools)#Realizando o teste de comparação das variânciasVarTest(x = pesoA$Peso, y = pesoB$Peso, alternative ="two.sided", ratio =1, conf.level =0.95)
F test to compare two variances
data: x and y
F = 0.75696, num df = 24, denom df = 19, p-value = 0.5137
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.3086696 1.7751803
sample estimates:
ratio of variances
0.7569569
A saída do teste contém várias informações: o valor da estatística do teste F, o número de graus de liberdade do numerador e do denominador da estatística de teste num df e denom df e o p-valor associado as hipóteses especificadas. Ele deixa explícito qual a hipótese alternativa “true ratio of variances is not equal to 1” que significa “a razão das variâncias é diferente de 1” o que equivale a dizer que as variâncias são diferentes. Fornece também uma estimativa pontual e intervalar para a razão das variâncias.
Note que, a estimativa da razão das variâncias parece inferior a 1 (0,75), indicando que os pesos dos pacotes produzidos pela Máquina B possuem uma variância maior do que aquelas produzidos pela máquina A. Porém, com base em um nível de significância de 5%, não rejeitamos \(H_0\) (p-valor = 0.5137 > 0,05 = \(\alpha\)), ou seja, não encontramos evidências nos dados para acreditar que a variância dos pesos dos pacotes das duas máquinas são diferentes.
20.1 Desafio
Utilize a base Dados socio.txt para responder as perguntas de 1 a 3.
Com base em um nível de significância de 5%, você diria que as variâncias das idades de homens e mulheres são diferentes?
Com base em um nível de significância de 1%, você diria que as variâncias dos pesos de homens e mulheres são iguais?
Com base em um nível de significância de 5%, você diria que a variância da satisfação dos homens é maior do que a variância da satisfação das mulheres?
Crie uma rotina computacional que calcula o intervalo de confiança para a razão de duas variâncias de populações normais.