17Teste de hipóteses para a média de uma população normal com variância desconhecida
Agora vamos discutir o problema de se testar uma afirmação sobre a média de uma população normal com variância desconhecida.
Suponha que desejamos testar se a altura média é superior de 1,67m. Como verificar essa afirmação?
Em um capítulo anterior, apresentamos uma solução para este problema em um cenário particular, assumimos que:
A população tinha distribuição normal.
A variância populacional era conhecida.
Vamos apresentar uma solução para o problema, assumindo que (2) não é verdade e checando se é razoável assumir (1).
Suponha que foi coletada uma amostra de 25 pessoas desta população. Neste momento, vocês estão estudando testes de hipóteses, no qual a hipótese nula é uma hipótese simples (um único valor para o parâmetro) e a hipótese alternativa é composta (vários valores para o parâmetro).
No problema levantado queremos testar as seguintes hipóteses
\(H_0\): a altura média é igual a 1,67 metros (\(\mu\) = 1,67),
\(H_1\): a altura média é superior a 1,67 metros (\(\mu\) > 1,67).
Porém, para executarmos o teste adequado, precisamos inicialmente checar a supoaição de normalidade. Vamos fazer isso por meio de um teste de normalidade. Vamos aqui usar o teste de Shapiro-Wilk.
Atividade 1: Importem o arquivo Medidas.rds e armazenem em um objeto chamado base.
Shapiro-Wilk normality test
data: base$altura
W = 0.97916, p-value = 0.868
Usando um nível de significância de 5%, não rejeitamos \(H_0\), isto é, há evidências de que a altura dos indivíduos possua distribuição normal.
Para verificarmos a afirmação de que a altura média é superior a 1,67m, precisaremos da função t.test.
A seguir, vamos apresentar os principais argumentos da funçãot.test:
- x - o vetor com a amostra;
- mu - o valor do parâmetro que definem as hipóteses (default = 0);
- alternative - argumento que define se o teste é bilateral ou unilateral a esquerda e a direita (default = bilateral - two.sided).
#Realizando o teste de hipótesest.test(x = base$altura,mu =1.67,alternative ="greater")
One Sample t-test
data: base$altura
t = 0.78123, df = 24, p-value = 0.2212
alternative hypothesis: true mean is greater than 1.67
95 percent confidence interval:
1.647628 Inf
sample estimates:
mean of x
1.6888
A saída do teste contém várias informações: o valor da estatística do teste, t, o número de graus de liberdade da estatística de teste, df, e o p-valor associado as hipóteses especificadas, p-value. Ele deixa explícito qual é a hipótese alternativa que está sendo testada “true mean is greater than 1.67” que significa “a verdadeira média é maior que 1.67”. Fornece também um intervalo de confiança unilateral (que não tem muita utilizada a menos que fosse um teste bilateral) e o valor de uma estimativa pontual.
Note que, mesmo com uma estimativa pontual superior a 1,67 (aproximadamente 1,69), com base em um nível de significância de 5%, não rejeitamos \(H_0\), não encontramos evidências para acreditar que a altura média seja superior a 1,67m.
Suponha que desejamos investigar se o peso é inferior a 70 Kg. Realize a análise mais completa possível para investigar essa afirmação.
\(H_0\): o peso médio é igual a 70 kg (\(\mu\) = 70),
\(H_1\): o peso médio é inferior a 70 kg (\(\mu\) < 70).
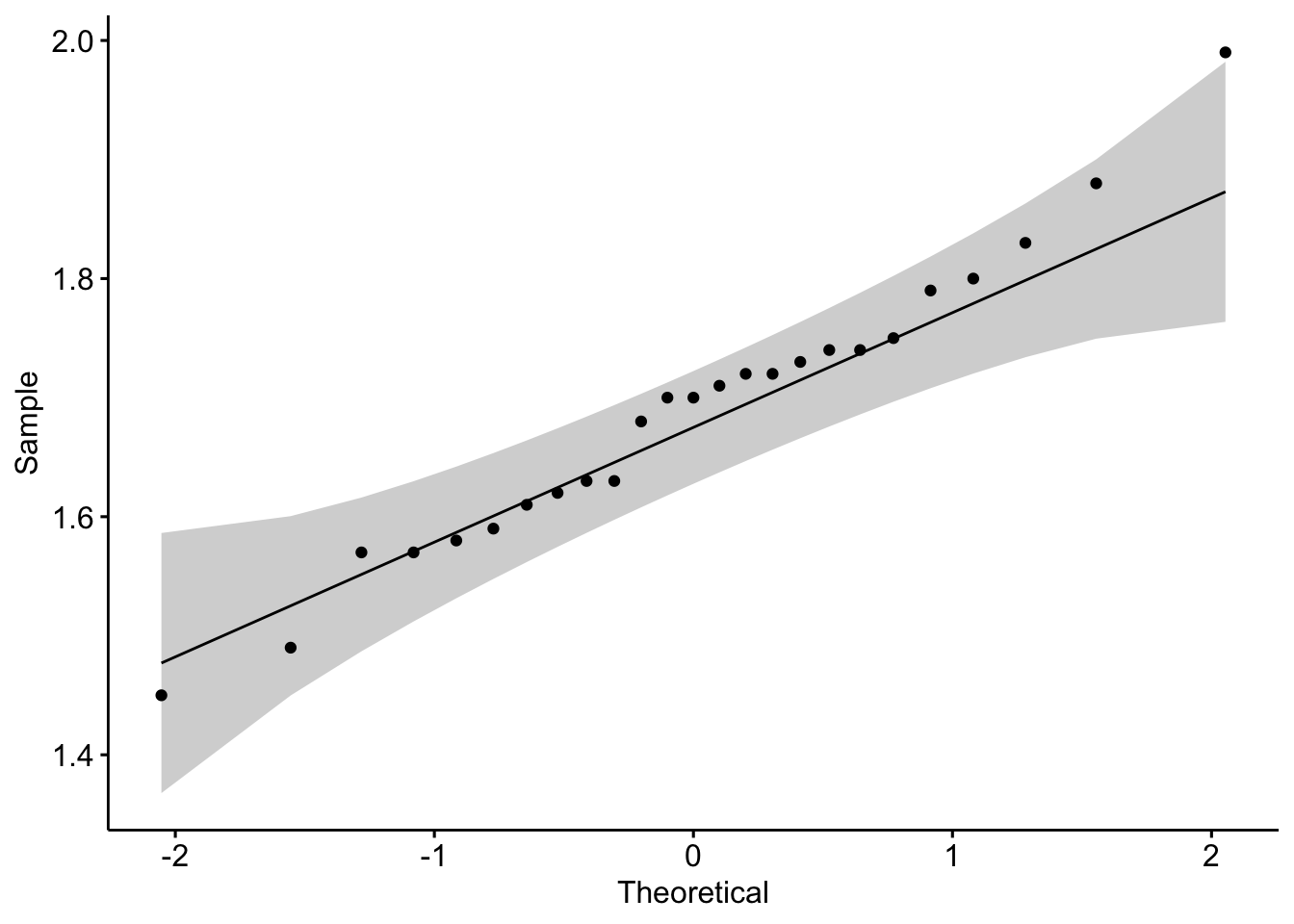
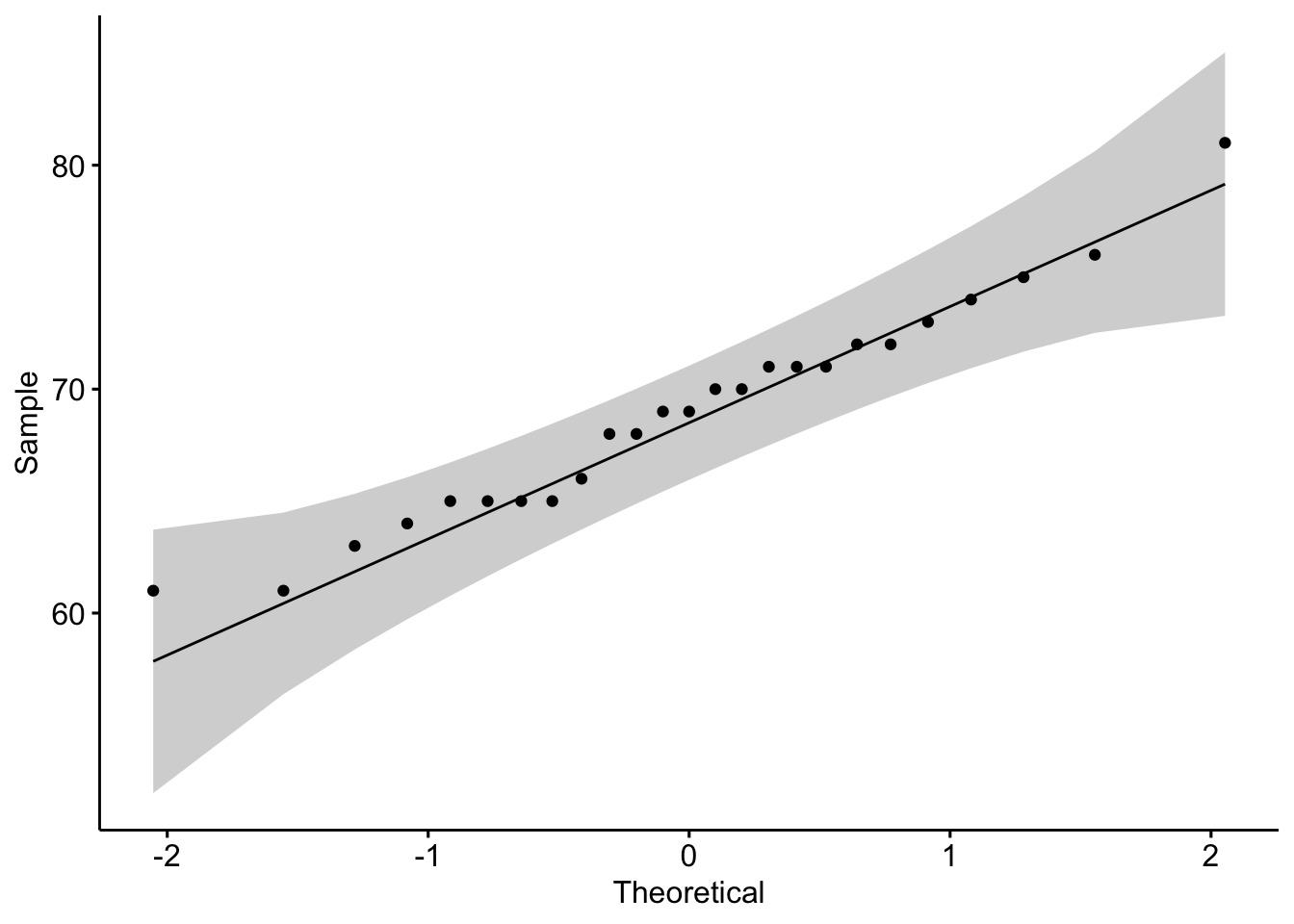
#Ativando o pacotelibrary(ggpubr)#Verificando normalidade dos dadosggqqplot(data = base$peso)
Warning in ks.test.default(x = base$peso, "pnorm", mean = mean(base$peso, :
ties should not be present for the Kolmogorov-Smirnov test
Asymptotic one-sample Kolmogorov-Smirnov test
data: base$peso
D = 0.11494, p-value = 0.8959
alternative hypothesis: two-sided
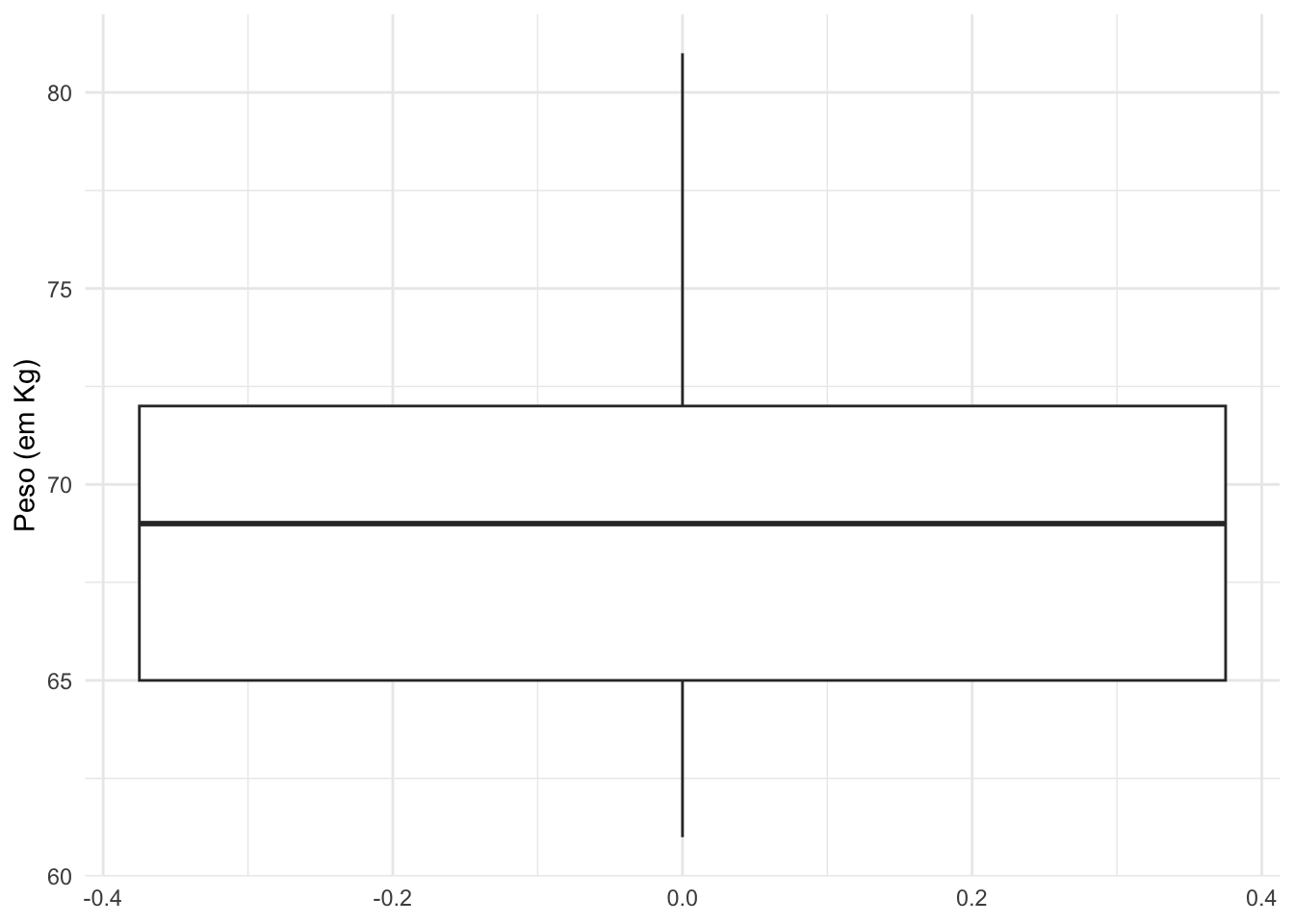
#Avaliando o comportamento dos valores da variável pesoggplot(data = base, mapping =aes(y = peso)) +geom_boxplot() +theme_minimal() +labs(y ="Peso (em Kg)")
#Ativando o pacotelibrary(Publish)
Loading required package: prodlim
#Obtendo uma estimativa pontual e uma intervalarci.mean(x = base$peso,alpha =0.05)
mean CI-95%
69.00 [67.00;71.00]
#Realizando o teste de hipótesest.test(x = base$peso,mu =70,alternative ="less")
One Sample t-test
data: base$peso
t = -1.0296, df = 24, p-value = 0.1567
alternative hypothesis: true mean is less than 70
95 percent confidence interval:
-Inf 70.6617
sample estimates:
mean of x
69
Comentários de cada passo da análise:
Analisando o boxplot, percebemos um comportamento simétrico da variável, com valores oscilando entre 60 Kg e 82 Kg. A mediana observada é inferior a 70 Kg.
O QQ-plot, junto com a banda de confiança, indica que os quantis amostrais não se distanciam muitos dos quantis de uma distribuição normal, indicando que parece razoável assumir normalidade dos dados.
Com base em um nível de significância de 5%, não rejeitamos \(H_0\), assumindo normalidade dos dados, conforme indicava o QQ-plot.
A estimativa pontual nos mostra que o peso médio é de 69 Kg e a região de 67 Kg a 71 Kg possui
probabilidade de conter o verdadeiro valor do peso médio.
Com base em um nível de significância de 5%, não rejeitamos \(H_0\), indicando que não possuímos evidências suficiente para acreditar que a média seja inferiror a 70 Kg.
17.1 Função poder
Como já discutido previamente. A função poder do teste é sempre um objeto de interesse quando estamos analisando um teste de hipóteses. Ela é obtida da seguinte forma:
Para obtermos a função poder, é preciso definir o erro tipo I para especificarmos o valor de \(k\) e conhecer a distribuição de probabilidade da variável aleatória envolvida no problema.
Quando \(\mu = \mu_0\),
\[
T = \frac{\bar{X}-\mu}{S/\sqrt{n}} \sim t_{(n-1)}
\]
Quando \(\mu \neq \mu_0\),
\[
T = \frac{\bar{X}-\mu}{S/\sqrt{n}} \sim t_{\left(\frac{\delta}{s/\sqrt{n}},n-1\right)}
\]
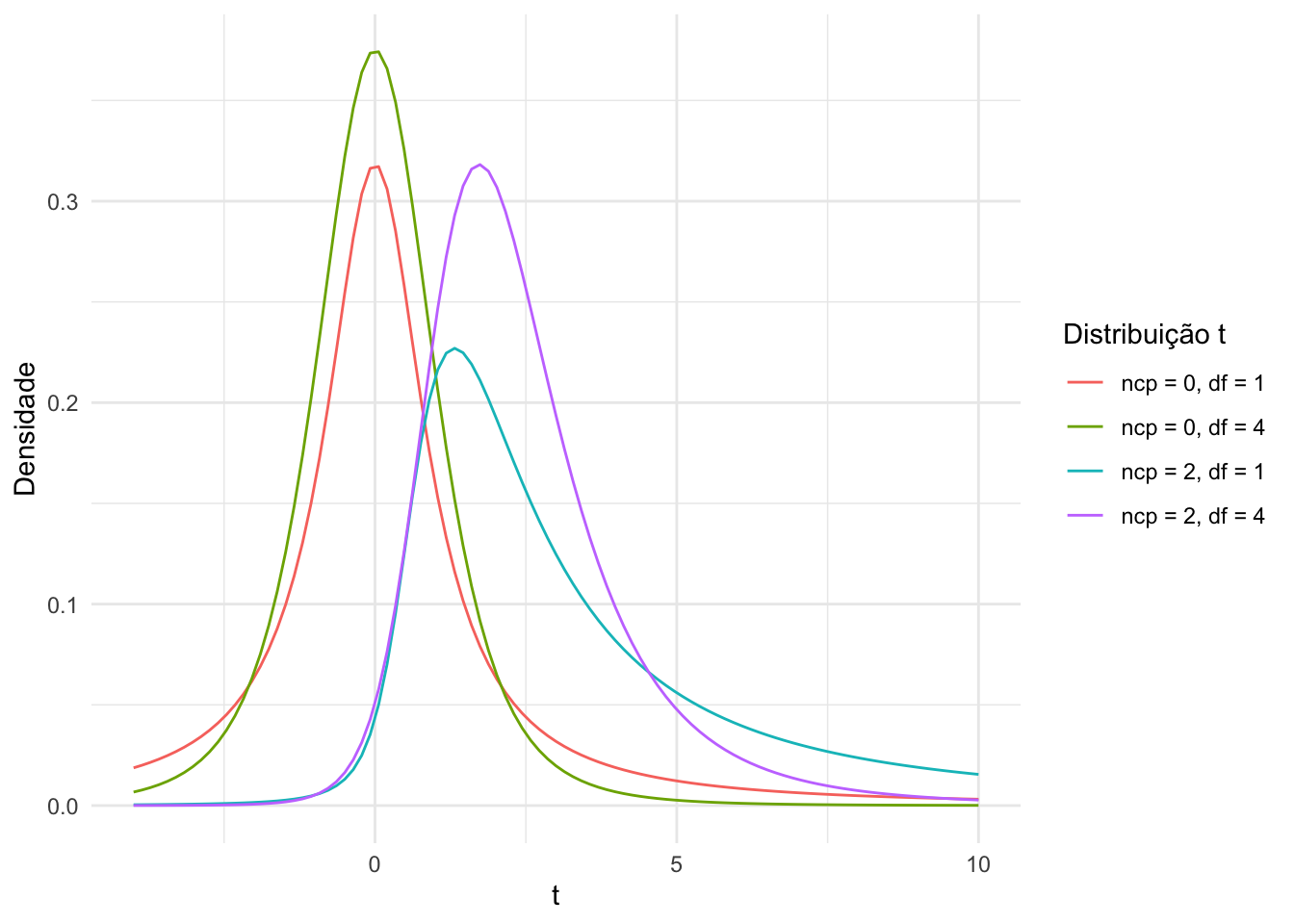
Abaixo comparamos o comportamento de algumas distribuições t-student, incluindo distribuições com parâmetro de não centralidade iguais e diferentes de 0.
Com base nas equações desenvolvidas acima, podemos criar uma rotina computacional (uma função) que receberá como argumentos: tamanho da amostra, nível de significância, valor da média a ser testado\(\mu_0\), o desvio padrão amostral e \(\mu\) - o valor da média na qual será calculado o valor do poder do teste.
#Função que calcula o poder para um teste unilateral a direita para a média de uma população normal com variância desconhecidapoder.tunid =function(mu0,mu,desvio,n,alfa){#Calculando k tcal =qt(p = alfa, df = n-1, lower.tail =FALSE)#Calculando o poder, assumindo que mu é diferente de mu0 poder =pt(q = tcal, df = n-1, ncp = (mu-mu0)/(desvio/sqrt(n)), lower.tail =FALSE)#retornando o poderreturn(poder)}#calculando a função poderpoder.tunid(n =25,alfa =0.01,mu0 =1.67,mu =1.78,desvio =0.12)
[1] 0.9767295
\(\pi(\mu = 1,78) = 0,9767295\), isto é, a probabilidade de afirmarmos que a altura média é superior a 1,67 metros, quando na verdade ela é 1,78 metros é 97,67%.
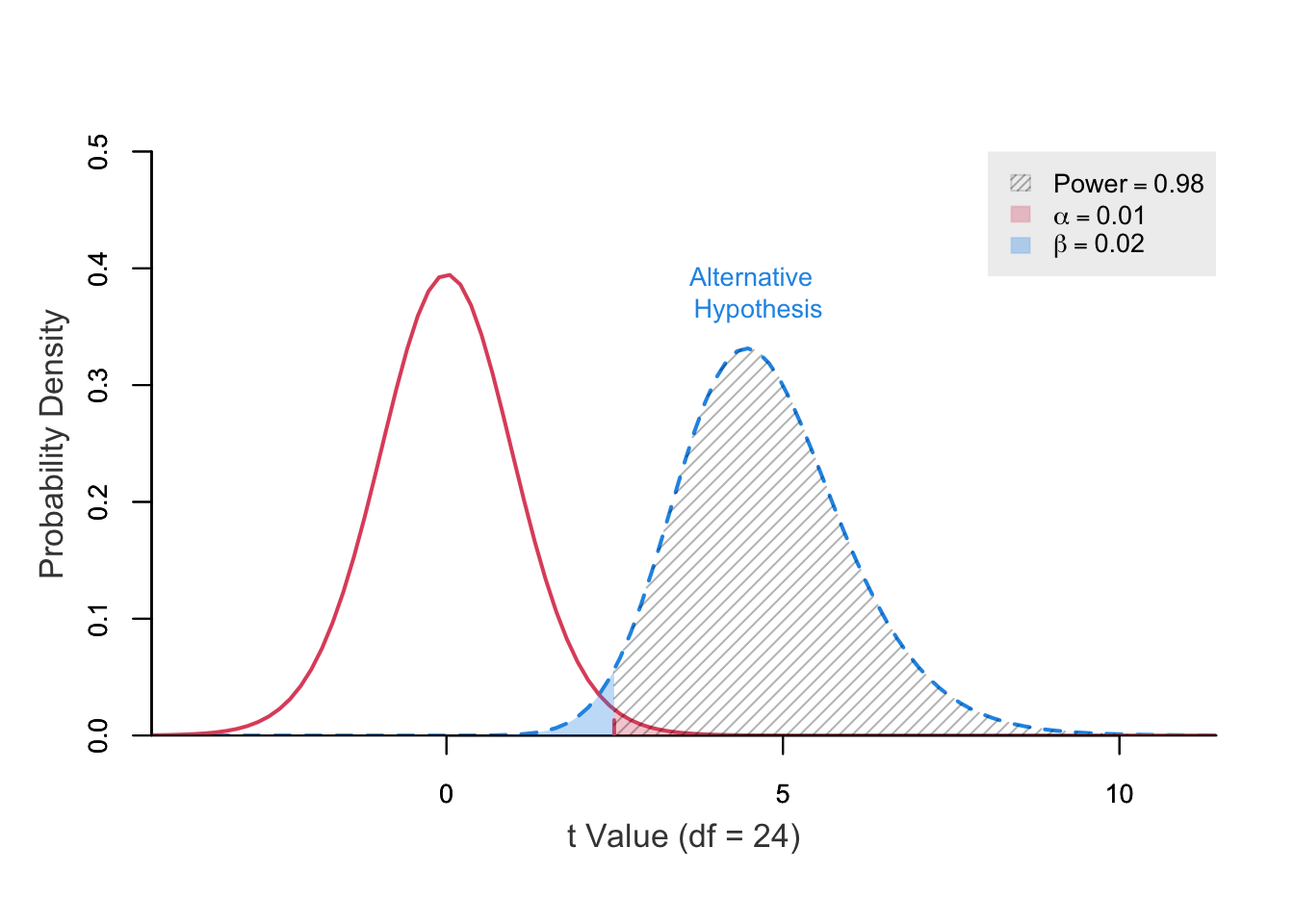
Abaixo, temos em vermelho a distribuição sob \(H_0\). Já a distibuição em azul é sob \(H_1\) (\(\mu\)).
O erro tipo I é a área em vermelho acima de \(k\) na distribuição sob \(H_0\) (0,01), o erro tipo II é a área em azul abaixo de \(k\) na distribuição sob a hipótese alternativa (0,02). Já a área acima de \(k\) na distribuição sob a hipótese alternativa é o poder do teste (área hachurada).
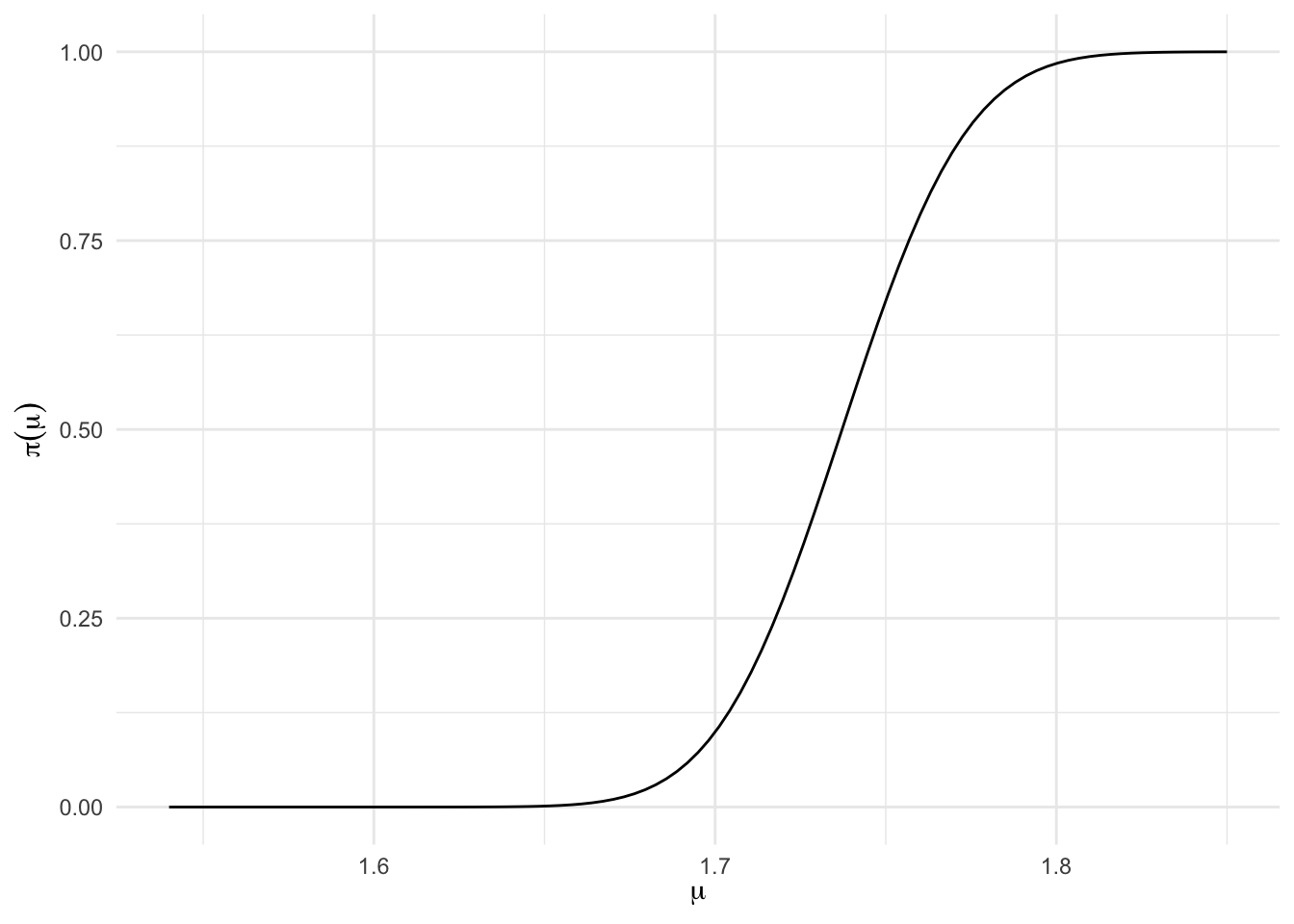
#Plotando a função poder do testeggplot(data =tibble(val =c(1.54,1.85)), mapping =aes(x = val)) +stat_function(fun = poder.tunid,args =list(n =20,alfa =0.01,mu0 =1.67,desvio =0.12)) +xlab(expression(mu)) +ylab(expression(pi(mu))) +theme_minimal()
17.2 Desafio
Teste a hipótese de que o comprimento médio da cintura é diferente de 81 cm. Use \(\alpha = 0,05\).
Teste a hipótese de que a idade média é superior a 45 anos. Use \(\alpha = 0,05\).
Crie uma função que calcula o poder para um teste unilateral a esquerda para a média de uma população normal com variância desconhecida. \(n = 30\), \(\alpha = 0,05\), \(\mu = 95\), \(\mu_0 = 100\) e \(s^2 = 40\). Interprete o resultado obtido.
Plote a função criado no item anterior para valores de \(95 \leq \mu \leq 110\). Para os demais valores necessários, utilizem os mesmos fornecidos na questão.
Crie uma função que calcula o erro tipo II para um teste unilateral a direita para a média de uma população normal com variância desconhecida. \(n = 30\), \(\alpha = 0,05\), \(\mu = 103\), \(\mu_0 = 100\) e \(s^2 = 40\). Interprete o resultado obtido.
Plote a função criado no item anterior para valores de \(95 \leq \mu \leq 110\). Para os demais valores necessários, utilizem os mesmos fornecidos na questão.