Diversos dos procedimentos abordados em aulas anteriores dependem da premissa de que os dados seguem uma distribuição normal. Até agora, temos seguido a prática de simplesmente assumir que essa premissa é válida. No entanto, é preferível empregar alguma técnica estatística que nos permita verificar se essa premissa é razoável ou não.
16.1 Análise exploratória
Inicialmente, vamos fazer uma análise exploratória, isto é, fazer uma inspeção visual que nos ajude a tomar uma decisão.
16.1.1 Histograma
Uma forma de avaliar o comportamento dos dados é construir um histograma e comprar com a curva da distribuição normal.
Suponha que queiramos verificar se os dados da altura são proveniente de uma normal. Inicialmente vamos analisar o comportamento do histograma.
Atividade 1: Importem o arquivo Medidas.rds e armazenem em um objeto chamado base.
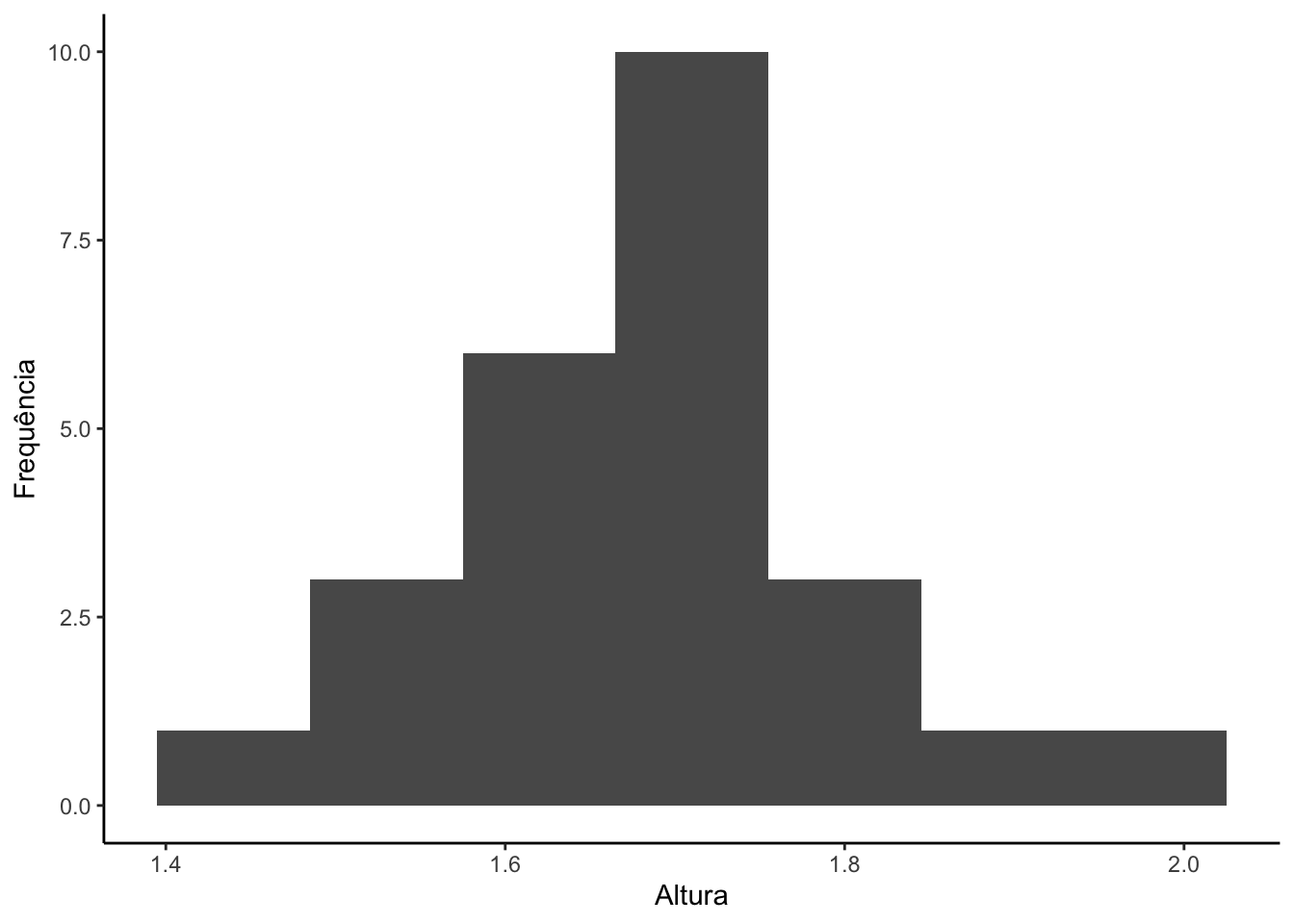
Agora vamos construir o histograma da variável altura.
#Carregando pacotelibrary(ggplot2)#Criando um qq-plot com o ggplot2ggplot(data = base, mapping =aes(x = altura)) +geom_histogram(bins =7) +theme_classic() +labs(y ="Frequência",x ="Altura")
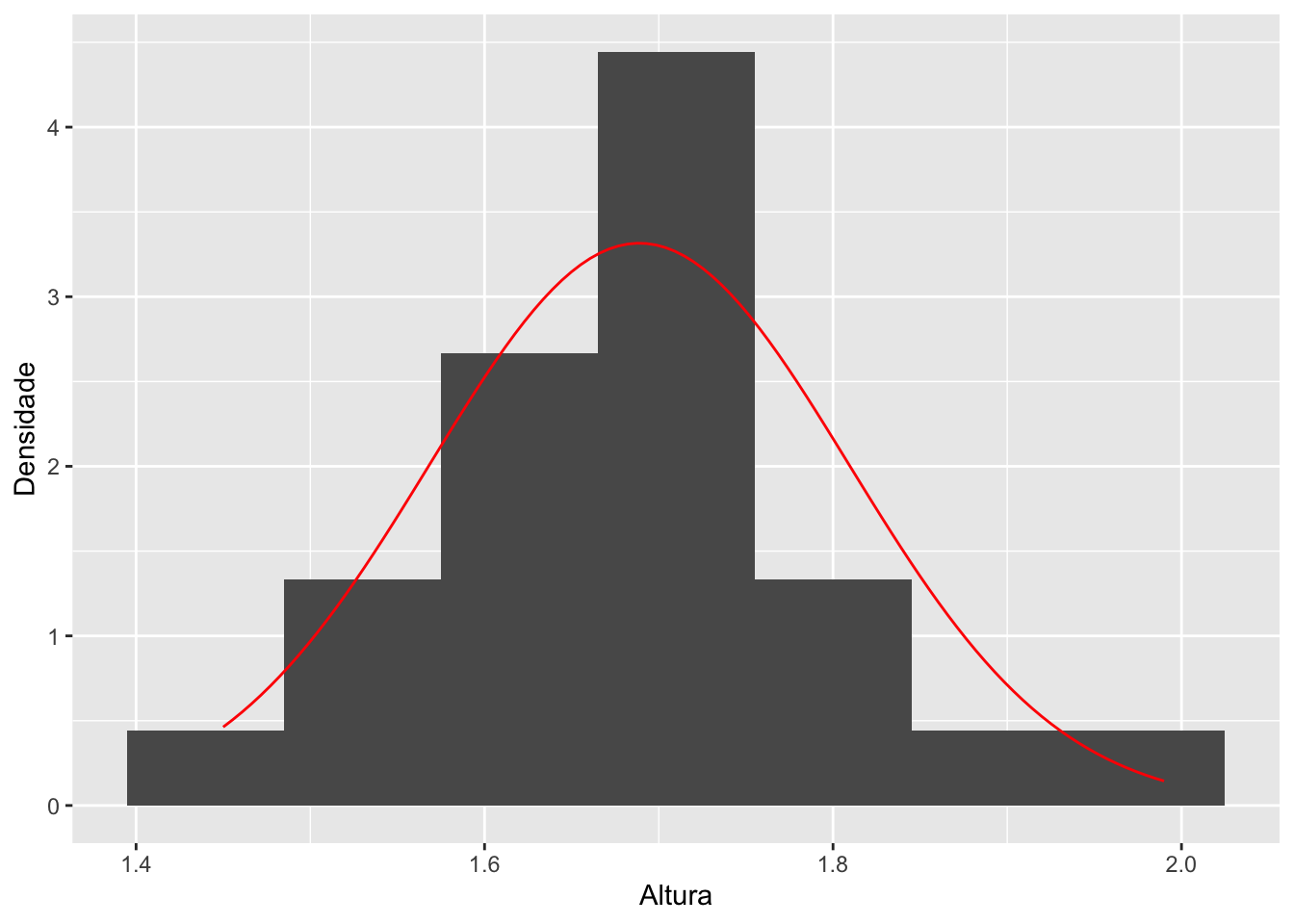
Vamos plotar sobre o histogrma a curva da densidade da normal. Mas para isso, precisamos pensar qual distribuição normal seria a mais razoável de se supor nesse caso. Para definir a distribuição normal, é preciso especificar os parâmetros \(\mu\) e \(\sigma^2\).
Neste caso, usualmente, utilizamos como média e variância da distribuição a estimativa da média e da variância amostral, respectivamente
#Plotando o histograma da amostra com base na densidadeggplot(data = base, mapping =aes(x = altura)) +geom_histogram(mapping =aes(y =after_stat(density)),bins =7) +stat_function(fun = dnorm,args =list(mean =mean(base$altura),sd =sd(base$altura)),colour ="Red") +labs(y ="Densidade",x ="Altura")
Com poucos dados, sempre vai ser ruim fazer essa comparação por meio do histograma. O gráfico qq-plot será preferível.
16.1.2 QQ-plot
Um dos gráfico mais recomendados para análise exploratória para checar normalidade é o gráfico QQ-plot.
O QQ-plot é um gráfico que compara os quantis teóricos de uma distribuição de probabilidade com os quantis amostrais. Quando os quantis amostrais se comportam de forma similar com os quantis teóricos, temos um indicativo de que é razoável supor que a amostra é proveniente da distribuição de probabilidade verificada.
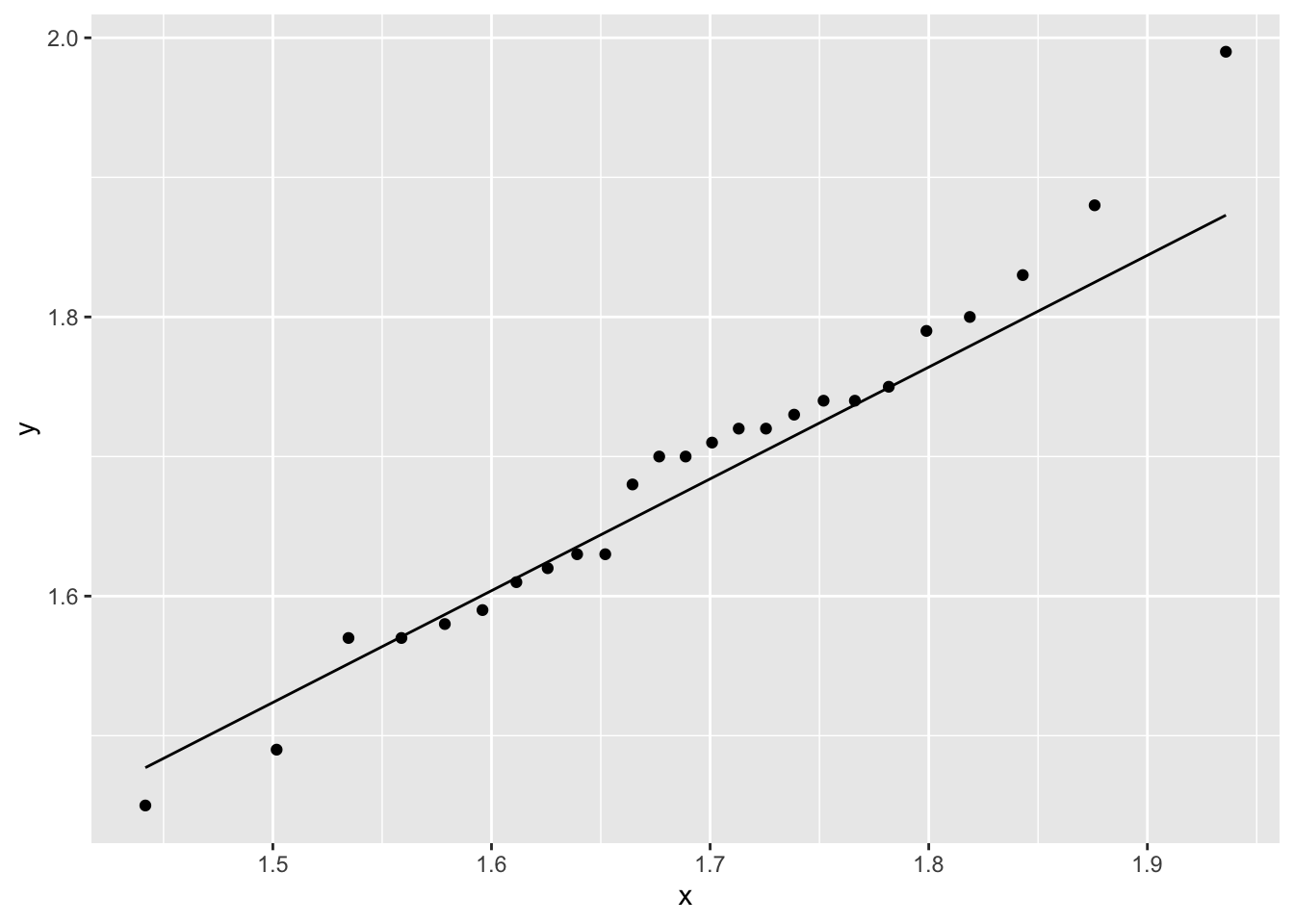
#Criando um qq-plot com o ggplot2ggplot(data = base, mapping =aes(sample = altura)) +stat_qq(distribution = qnorm,dparams =list(mean =mean(base$altura,na.rm =TRUE),sd =sd(base$altura,na.rm =TRUE))) +stat_qq_line(distribution = qnorm,dparams =list(mean =mean(base$altura,na.rm =TRUE),sd =sd(base$altura,na.rm =TRUE)))
A ideia do gráfico é comparar se os pontos se encontram próximos a reta. Percebam que no gráfico criado, informamos no stat_qq qual a distribuição de probabilidade que estamos interessados em comparar os quantis teóricos com os quantis amostrais. E ainda, informamos no stat_qq_line a distribuição com seus respectivos parâmetros, pois se não o fizermos, ele plotara a função para o caso N(0,1).
Avaliando o gráfico, parece não haver grandes desvios entre os quantis (teóricos e amostrais).
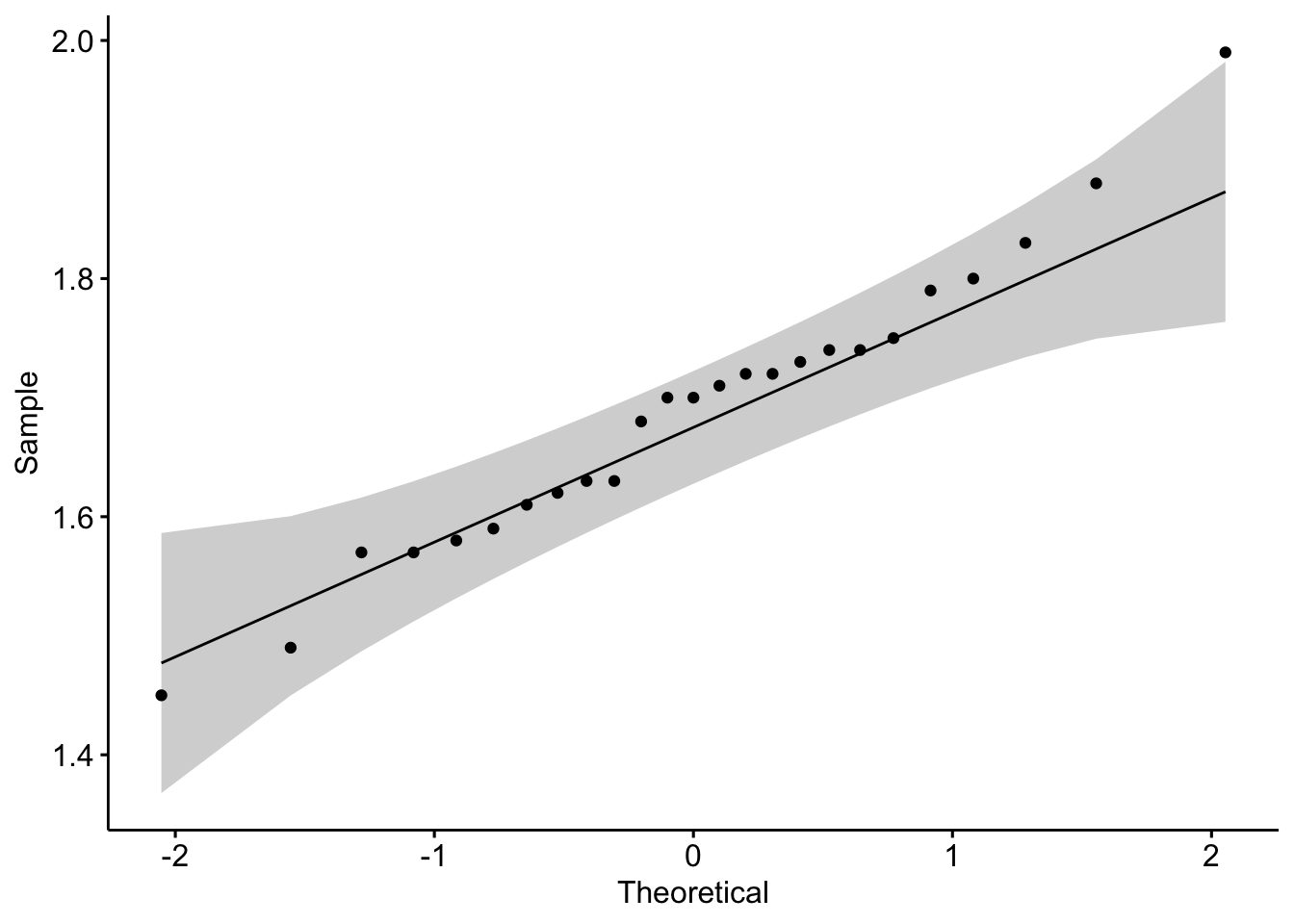
Uma outra forma de obter o mesmo gráfico é usar a função ggqqplot do pacote ggpubr.
#Carregando pacotelibrary(ggpubr)#Criando um qq-plot com o ggpubrggqqplot(data = base$altura)
Esta função plota os quantis teóricos e amostrais, a reta de comparação e uma banda de confiança onde a grande maioria dos pontos deveriam cair. O gráfico parece mais informativo que o anterior. Existe alguma desvantagem? Se você estivesse interessado em verificar graficamente se a amostra é proveniente de uma normal com média 2 e variância 1, você precisaria usar o ggplot2, pois a função ggqqplot usa como valores para a média e a variância da Normal as estimativas obtidas a partir da amostra.
Entretanto, esta é uma análise exploratória. Não podemos fazer afirmações. Para tal, iremos discutir uma outra ferramenta estatística, o teste de hipóteses.
16.2 Testes de Normalidade
O teste de hipóteses é uma regra de decisão que nos permite rejeitar ou não uma hipótese estatística por meio da evidência fornecida pela amostra.
Sendo assim, existem diversos testes de hipóteses (para média, proporção, variância), incluindo testes apropriados para testar a hipótese de normalidade dos dados. Entre as diversas opções existentes na literatura, aqui iremos discutir os testes de Kolmogorov-Smirnov e Shapiro-Wilk.
16.2.1Teste de Kolmogorov-Smirnov
É um teste de aderência a distribuições de probabilidade, incluindo a normal. Com este teste é possível checar a hipótese de que os dados são provenientes de uma determinada distribuição de probabilidade. Este teste baseia-se na função de distribuição empírica, isto é, o teste compara a função de distribuição empírica com a função de distribuição acumulada de uma determinada distribuição de probabilidade.
Hipóteses do teste:
\(H_0: F(x) = F_0(x) \forall x\),
\(H1:F(x) ≠ F_0(x) \mbox{ para algum } x\) .
Ou poderíamos reescrever as hipóteses do teste como:
\(H_0\): os dados são provenientes de uma determinada distribuição de probabilidade,
\(H_1\): os dados não são provenientes de uma determinada distribuição de probabilidade.
Em particular, quando \(F_0(x)\) for a função de distribuição acumulada da normal, estaremos fazendo um teste de normalidade.
A estatística do teste de Kolmogorov-Smirnov é baseada na maior diferença absoluta entre a função de distribuição empírica \(F(x)\) e a função de distribuição acumulada da variável a ser testada \(F_0(x)\).
No R, realizamos o teste de Kolmogorov-Smirnov por meio da função ks.test. É preciso informar um vetor com os dados, indicar a função que calcula a função de distribuição acumulada (no caso da normal é a pnorm) e indicar os parâmteros da distribuição \(\mu\) e \(\sigma\). Neste caso, iremos utilizar as estimativas amostrais.
#Obtendo media e desvio padraomedia =mean(base$altura, na.rm =TRUE)desvio =sd(base$altura, na.rm =TRUE)#Visualizando a estimativa da médiamedia
[1] 1.6888
#Visualizando a estimativa do desvio padrãodesvio
[1] 0.1203232
#Teste de Kolmogorov-Smirnovks.test(x = base$altura, "pnorm", mean = media, sd = desvio)
Warning in ks.test.default(x = base$altura, "pnorm", mean = media, sd =
desvio): ties should not be present for the Kolmogorov-Smirnov test
Asymptotic one-sample Kolmogorov-Smirnov test
data: base$altura
D = 0.10551, p-value = 0.9436
alternative hypothesis: two-sided
Com base no p-valor observado (p = 0,9436), se adotarmos um nível de significância de 0,01, não rejeitamos \(H_0\), ou seja, não existem evidências nos dados para irmos contra a hipótese que assume normalidade \(N(1.6888,(0.1203232)^2)\) para os dados de altura, confirmando as impressões fornecidas pelo QQ-plot.
Esse teste pode ser utilizado para outras distribuições de probabilidade. Por exemplo, é razoável supor que os dados da altura sejam provenientes de uma distribuição Exponencial com \(\lambda = 0,6\)?
#Teste de Kolmogorov-Smirnovks.test(x = base$altura, "pexp", rate =0.6)
Warning in ks.test.default(x = base$altura, "pexp", rate = 0.6): ties should
not be present for the Kolmogorov-Smirnov test
Asymptotic one-sample Kolmogorov-Smirnov test
data: base$altura
D = 0.58105, p-value = 9.327e-08
alternative hypothesis: two-sided
Supondo um nível de significância de 5%, como p-valor é menor do que \(\alpha\) rejeitamos \(H_0\), isto é, os dados não fornecem evidências de que os dados de altura possuam distribuição exponencial com \(\lambda = 0,6\).
16.2.2Teste de Shapiro-Wilk
É um teste específico de normalidade, diferente do Kolmogorov-Smirnov. Este teste baseia-se na comparação de duas medidas de variação.
Hipóteses do teste:
\(H_0\): os dados são provenientes de uma distribuição normal,
\(H_1\): os dados não são provenientes de uma distribuição normal.
Para a construção da estatística de teste, considere os seguintes passos
Obter uma ordenação da amostra:
\[
y_1 \leq y_2 \leq \ldots \leq y_n.
\]
Calcular a soma de quadrado dos desvios:
\[
S^2 = \sum_{i=1}^{n} (y_i - \bar{y})^2
\]
Calcular \(b\)
Se \(n\) é par, \(n=2k\) e calcule. Os \(a_i\) são valores tabelados. \[
b=\sum_{i=1}^{k}a_{n-i+1}(y_{n-i+1}-y_i)
\]
Se \(n\) foi ímpar, \(n=2k+1\), os cálculos permanecem os mesmos, exceto que \(a_{k+1} = 0\)
\[
b = a_n(y_n-y_1)+ \ldots, a_{k+2}(y_{k+2}-y_k)
\]
Calcular
\[
W = \frac{b^2}{s^2}
\]
Avaliar a estatística do teste por meio do p-valor. No caso de uma valor significativo para a estatística do teste (p-valor < \(\alpha\)), isso indica falta de normalidade para a variável aleatória analisada.
#Teste de normalidade de shapiro-wilkshapiro.test(x = base$altura)
Shapiro-Wilk normality test
data: base$altura
W = 0.97916, p-value = 0.868
Se analisarmos a saída do teste, com base em um nível de significância de 1%, não rejeitamos \(H_0\), ou seja, não existe evidências para desconfiarmos que a amostra não seja proveniente de uma distribuição normal.
Verifique se o peso possui distribuição normal. Apresente um análise exploratória completa e um teste de hipóteses. Use \(\alpha = 0,05\).
Verifique se a variável idade possui uma distribuição Gama com \(\alpha = 5\) e \(\beta = 0,1\). Apresente um histograma com a densidade, um qq-plot e um teste de hipóteses. Use \(\alpha = 0,01\).
Verifique se o comprimento da cintura possui distribuição normal. Apresente um análise exploratória completa e um teste de hipóteses. Use \(\alpha = 0,05\).