A seguir, apresentaremos algumas visualizações gráficas que podem ser úteis em alguns contextos que ainda não discutimos ao longo do curso.
9.1Gráfico de dispersão 3-D
Suponha que o nosso interesse seja o de avaliar a relação entre quilometragem, cilindrada do motor e o peso do carro graficamente e de forma conjunta. As três variáveis envolvidas são quantitativas e um possível gráfico para visualizarmos a relação das 3 variáveis de interesse seria o gráfico de dispersão 3-D.
Atividade: Importe o arquivo Base_carros.txt e armazene-o em um objeto chamado base_carros.
Os dados foram extraídos da revista Motor Trend US 1974, trata-se da base mtcars do R. A base de dados possui 32 observações e 11 variáveis, dentre elas:
mpg - Milhas por galão;
cyl- número de cilindros;
disp - cilindrada do motor (em polegadas cúbicas - cu. in.);
Vamos usar o pacote scatterplot3d para criarmos o nosso primeiro gráfico de dispersão 3-D.
# carregando pacotelibrary(scatterplot3d)# criando um gráfico de dispersão 3-D simpleswith(base_carros, {scatterplot3d(x = disp,y = wt, z = mpg,main="Gráfico de dispersão 3-D")})
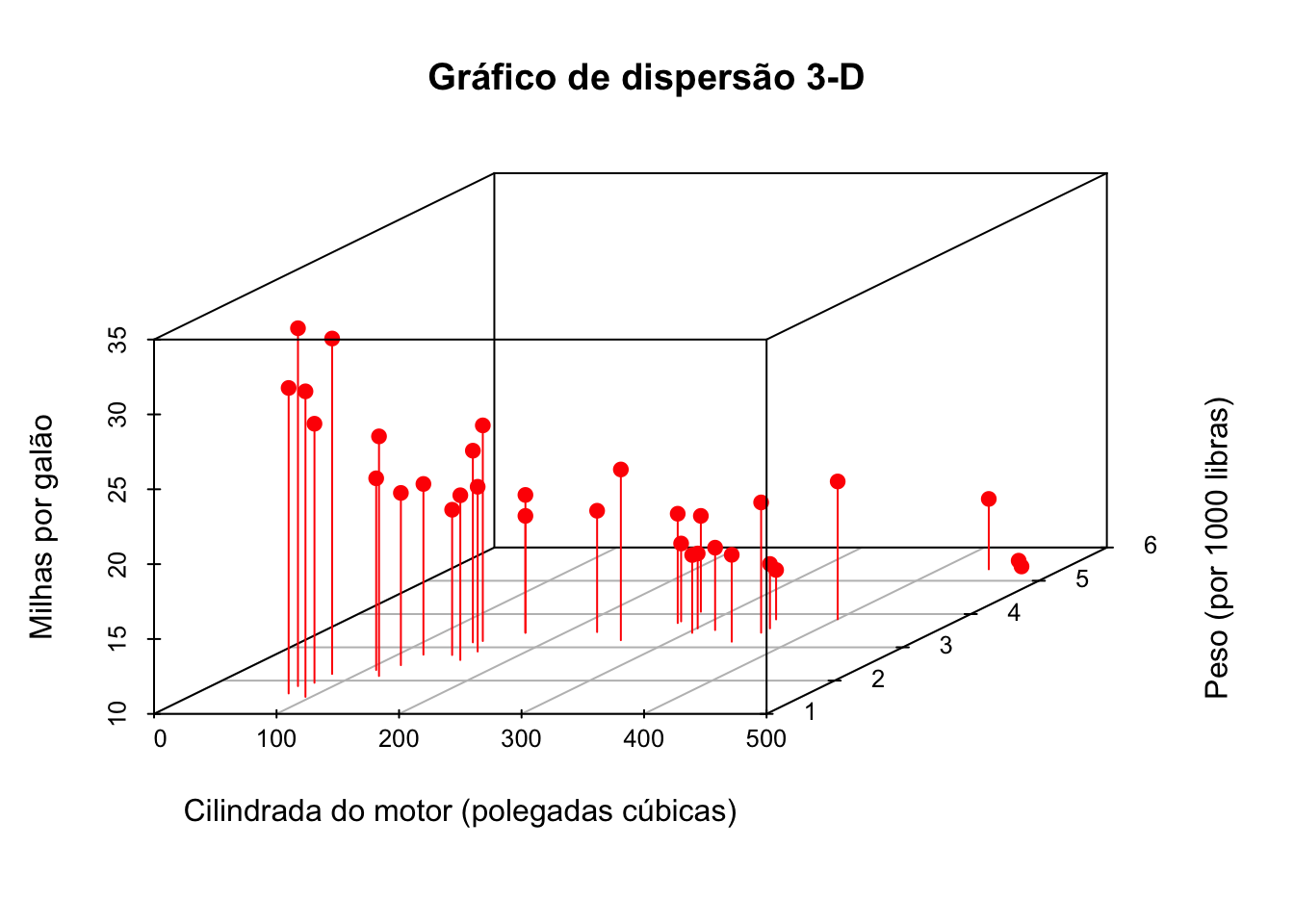
O gráfico precisa de algumas modificações para ficar mais fácil de interpretar. Vamos modificar o gráfico substituindo os pontos por círculos vermelhos preenchidos, além disso, vamos adicionar linhas no plano x-y e modificar os rótulos dos eixos.
# modificando o gráfico de dispersão 3-Dwith(base_carros, {scatterplot3d(x = disp, y = wt, z = mpg,# escolhendo um círculo preenchidopch=19,# cor do círculocolor="red", # incluindo linhas no plano horizontaltype ="h",main ="Gráfico de dispersão 3-D",xlab ="Cilindrada do motor (polegadas cúbicas)",ylab ="Peso (por 1000 libras)",zlab ="Milhas por galão")})
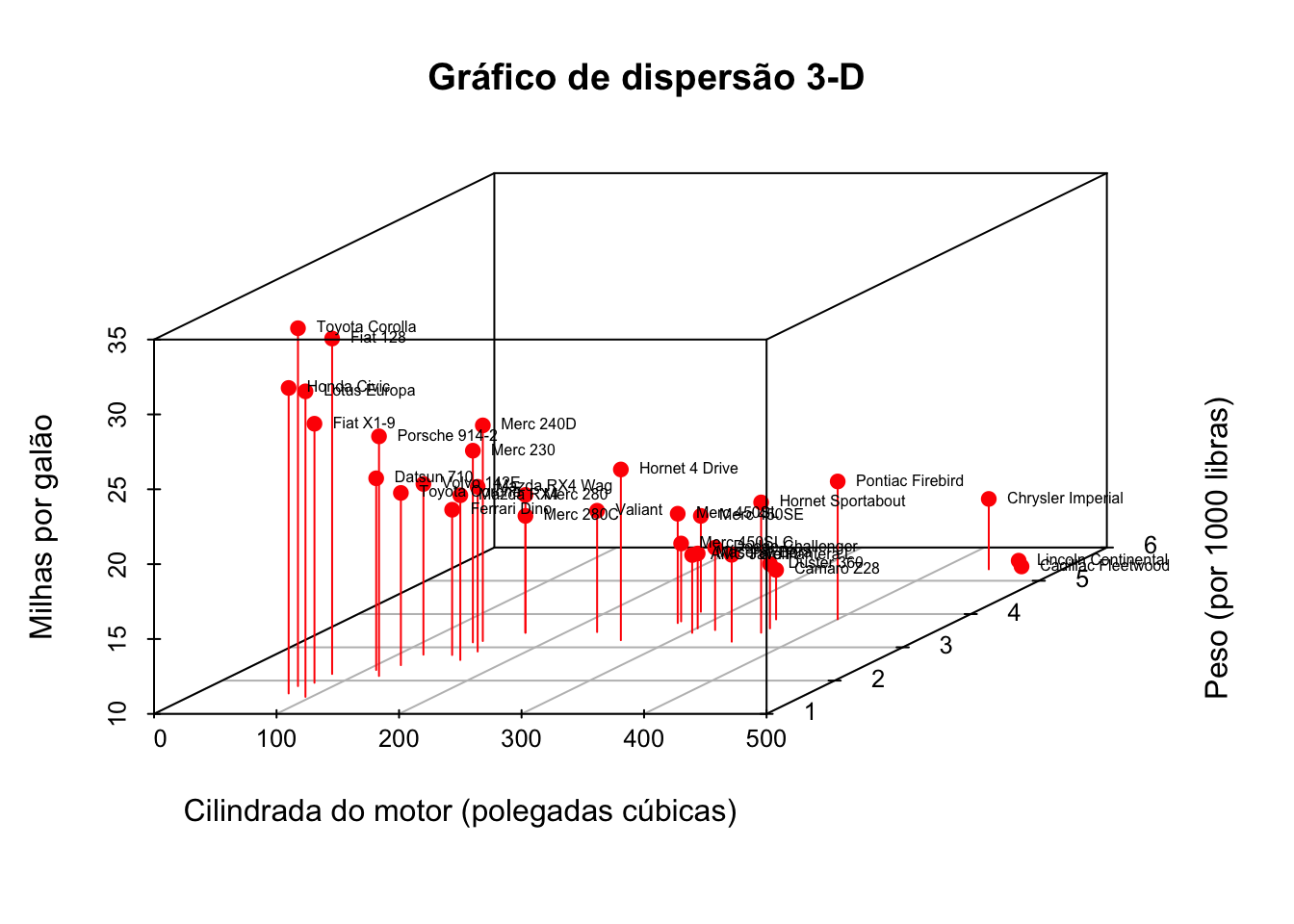
A seguir, vamos indicar a marca do carro nos pontos. Podemos fazer isso salvando os resultados da função scatterplot3d em um objeto, usando a função xyz.convert para converter coordenadas de 3-D (x, y, z) em projeções 2-D (x, y) e aplicar o texto função para adicionar rótulos ao gráfico
# criando o gráfico de dispersão 3-D como um objetowith(base_carros, { Disp_3d <-scatterplot3d(x = disp, y = wt, z = mpg,pch =19,color ="red", type ="h",main ="Gráfico de dispersão 3-D",xlab ="Cilindrada do motor (polegadas cúbicas)",ylab ="Peso (por 1000 libras)",zlab ="Milhas por galão")# convertendo projeções 3-D em 2-D Disp_3d.coords <- Disp_3d$xyz.convert(disp, wt, mpg) # plotando o texto com encolhimento de 50% e à direita do pontotext(Disp_3d.coords$x, Disp_3d.coords$y, labels = nome, cex = .5, pos =4)})
Vamos avaliar os possíveis valores obtidos pela variável número de cilindros.
# carregando o pacotelibrary(janitor)
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
base_carros |>tabyl(var1 = cyl) |>adorn_totals(where ="row") |>#adiciona uma linha com os totaisadorn_pct_formatting() #apresenta os percentuais na escala de 0 a 100 com o símbolo %
cyl n percent
4 11 34.4%
6 7 21.9%
8 14 43.8%
Total 32 100.0%
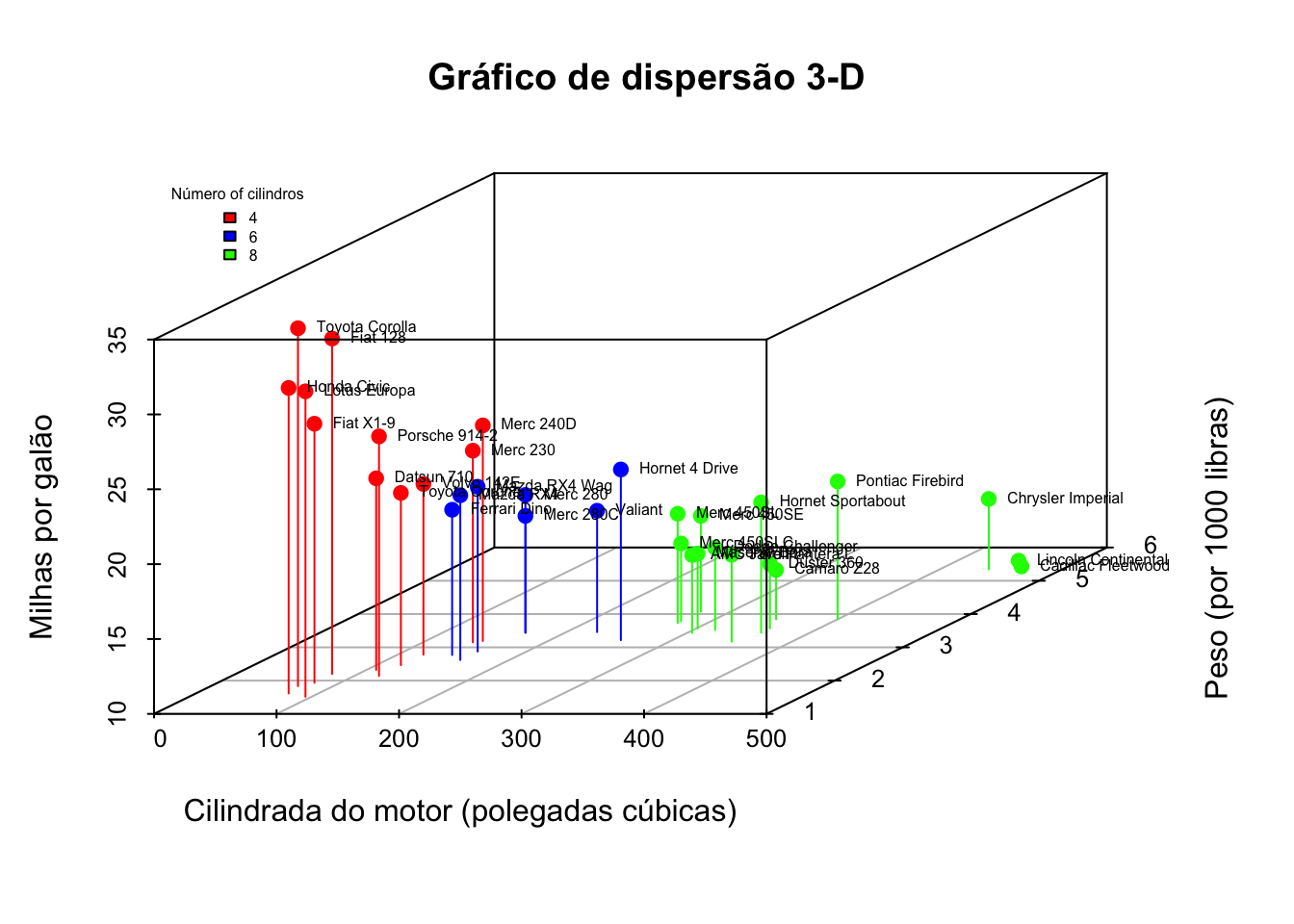
A seguir, vamos criar uma variável atribuindo uma cor para cada valor de cilindro e iremos incluir essa informação no gráfico.
# Definindo cores para cada valor do cilindrobase_carros = base_carros |>mutate(cores =if_else(cyl ==4, "red", if_else(cyl ==6, "blue", "green")))# criando o gráfico de dispersão 3-D como um objetowith(base_carros, { Disp_3d <-scatterplot3d(x = disp, y = wt, z = mpg,pch =19,color = cores, type ="h",main ="Gráfico de dispersão 3-D",xlab ="Cilindrada do motor (polegadas cúbicas)",ylab ="Peso (por 1000 libras)",zlab ="Milhas por galão")# convertendo projeções 3-D em 2-D Disp_3d.coords <- Disp_3d$xyz.convert(disp, wt, mpg) # plotando o texto com encolhimento de 50% e à direita do pontotext(Disp_3d.coords$x, Disp_3d.coords$y, labels = nome, cex = .5, pos =4)# adicionando a legendalegend(#localização da legenda"topleft", inset=.05,# para suprimir a caixa da legenda e encolendo o texto em 50 %bty="n", cex=.5, title="Número of cilindros",c("4", "6", "8"), fill=c("red", "blue", "green"))})
Podemos ver facilmente que o Toyota Corolla faz a maior distância e tem baixa cilindrada, baixo peso e 4 cilindros.
9.2Gráfico de bolhas
É um gráfico usado para avaliar a relação de três variáveis. De uma forma geral, podemos dizer que um gráfico de bolhas é basicamente um gráfico de dispersão no qual o tamanho do ponto é proporcional aos valores de uma terceira variável quantitativa.
A seguir, vamos representar graficamente o peso do carro em relação à sua quilometragem e usar o tamanho do ponto para representar a potência.
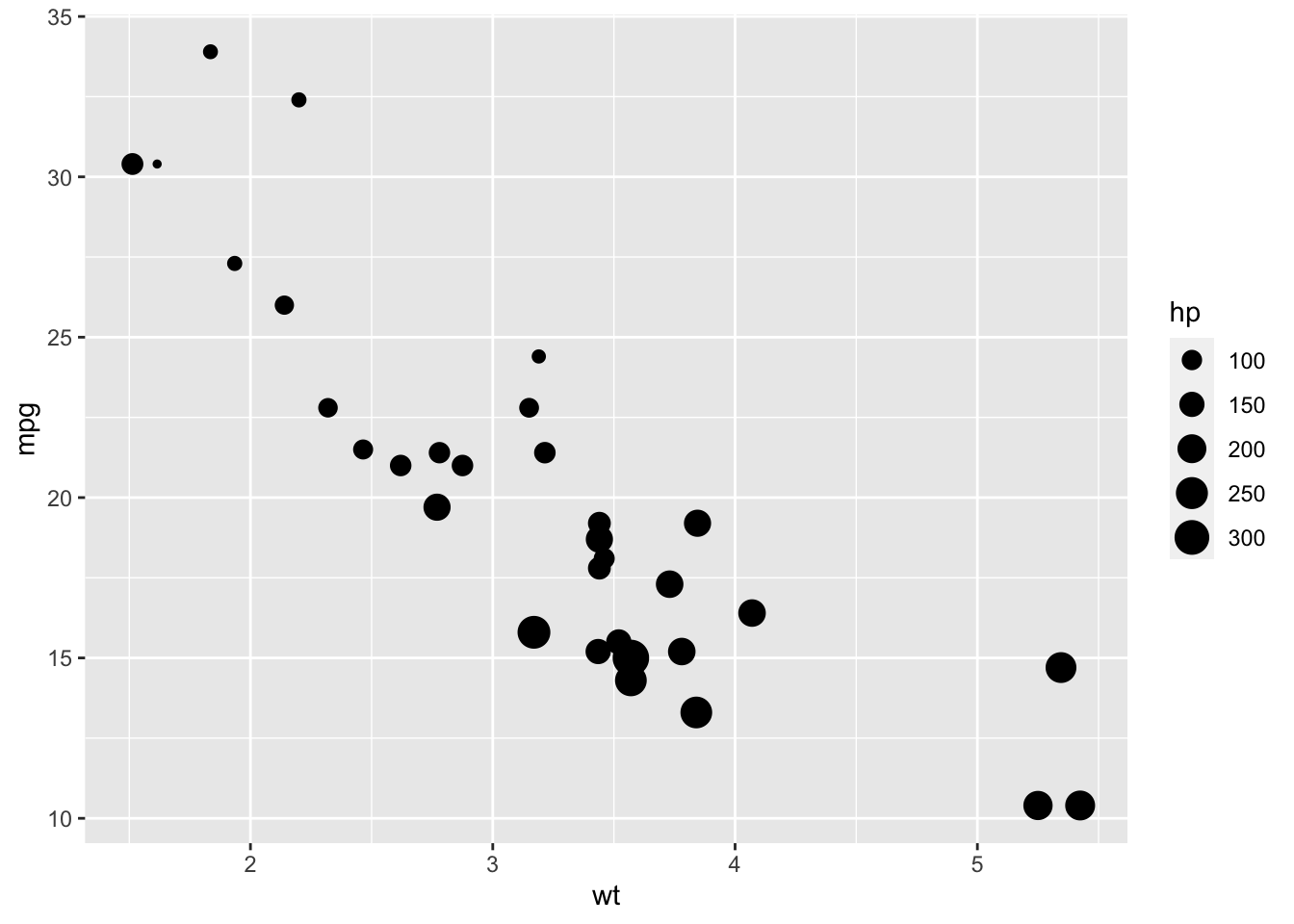
#Ativando pacotelibrary(ggplot2)# criando um gráfico de bolhasbase_carros |>ggplot(mapping =aes(x = wt, y = mpg, size = hp)) +geom_point()
É possível melhorarmos a aparência padrão de gráfico fazendo simples modificações. Por exemplo, é possível aumentarmos o tamanho das bolhas, escolhermos uma forma e uma cor de ponto diferente e adicionarmos alguma transparência.
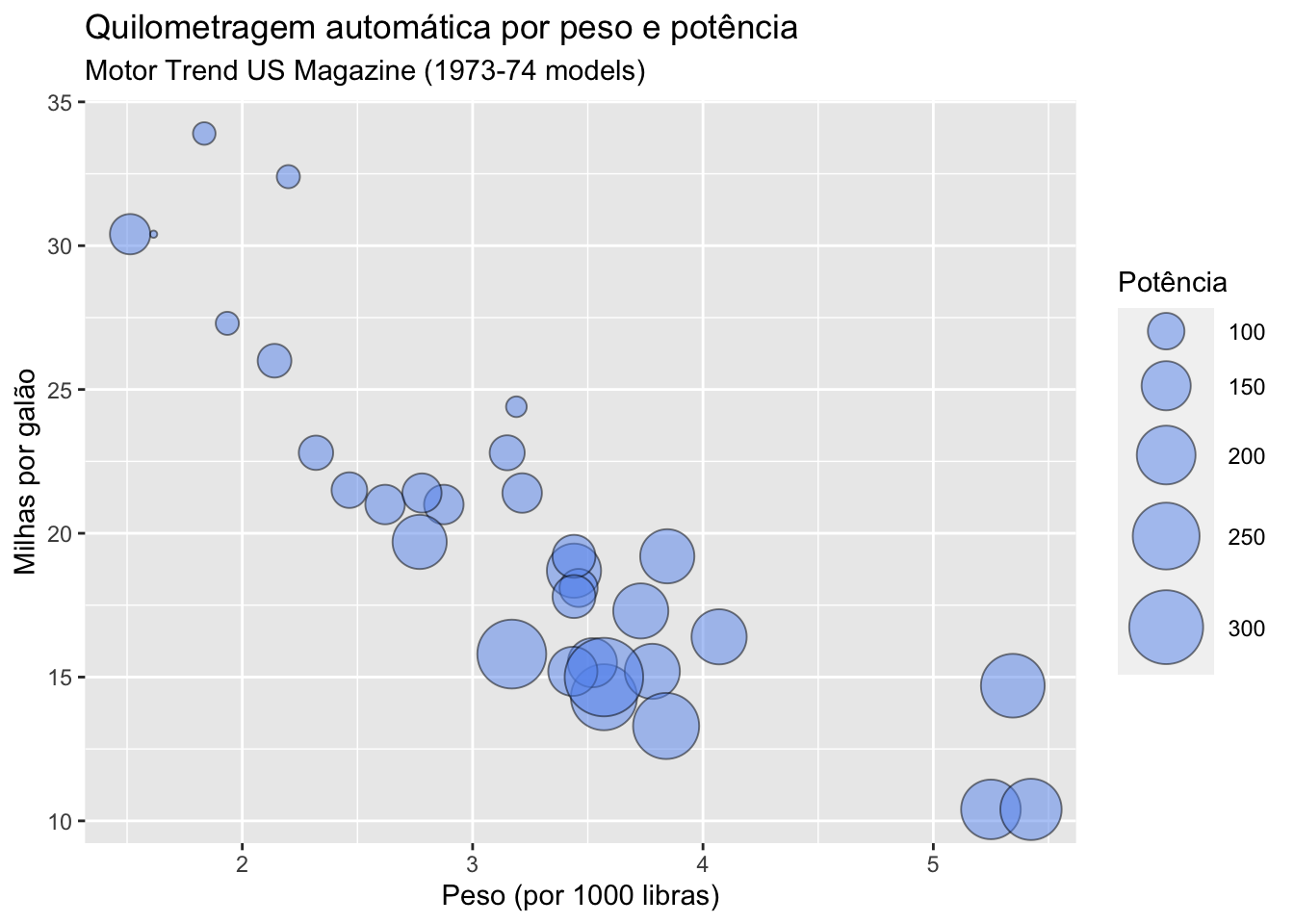
# melhorando o gráfico de bolhasbase_carros |>ggplot(mapping =aes(x = wt, y = mpg, size = hp)) +geom_point(alpha = .5, fill="cornflowerblue", color="black", shape=21) +scale_size_continuous(range =c(1, 14)) +labs(title ="Quilometragem automática por peso e potência",subtitle ="Motor Trend US Magazine (1973-74 models)",x ="Peso (por 1000 libras)",y ="Milhas por galão",size ="Potência")
O argumento range da função scale_size_continuous especifica o tamanho mínimo e máximo do símbolo no gráfico. O default é o intervalo = c (1, 6).
O argumento shape da função geom_point especifica um círculo com uma cor de borda e cor de preenchimento.
Pelo gráfico, podemos ver claramente que as milhas por galão diminuem com o aumento do peso e da potência do carro. No entanto, há um carro com baixo peso, alta potência e grande consumo de combustível. Quem seria o carro?
Podemos dizer que os gráficos de bolhas são controversos pelo mesmo motivo que os gráficos de setores são controversos. As pessoas são melhores em julgar a extensão do que o volume. No entanto, eles são bastante populares.
9.3Diagramas aluviais
Os diagramas aluviais podem ser usados para visualizar as distribuições de frequência ao longo do tempo ou tabelas de frequência envolvendo várias variáveis categóricas.
Para ilustrar a visualização, iremos utilizar o arquivo survey85.csv.
Atividade: Importe o arquivo survey85.csv e armazene-o em um objeto chamado survey.
A base de dados possui variáveis referentes a uma pesquisa survey realizada em 1985 contendo remuneração e outras características de trabalhadores, tais como:
salário por hora em dólares (remuneracao);
número de anos de educação (educacao);
sexo;
é hispânico? (hispanico);
é do sul? (sul);
é casado? (casado);
tempo de experiência de trabalho (exper);
idade;
setor de trabalho (setor).
# Visualizando o objetosurvey
# A tibble: 533 × 10
remuneracao educacao raca sexo hispanico sul casado exper idade setor
<dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 9 10 Branco M N N S 27 43 constru…
2 5.5 12 Branco M N N S 20 38 vendas
3 3.8 12 Branco F N N N 4 22 vendas
4 10.5 12 Branco F N N S 29 47 adminis…
5 15 12 Branco M N N S 40 58 constru…
6 9 16 Branco F N N S 27 49 adminis…
7 9.57 12 Branco F N N S 5 23 servico
8 15 14 Branco M N N N 22 42 vendas
9 11 8 Branco M N N S 42 56 fabrica
10 5 12 Branco F N N S 14 32 vendas
# ℹ 523 more rows
Inicialmente iremos criar um resumo que contempla as variáveis setor, raça e sexo. Como são muitas categorias de setor, estamos filtrando a base para alguns setores de interesse.
# resumindo os dadostabela_survey <- survey %>%filter(setor %in%c("administrativo","servico","vendas")) |>group_by(setor, raca, sexo) %>%count()# visualizando o objetotabela_survey
# A tibble: 11 × 4
# Groups: setor, raca, sexo [11]
setor raca sexo n
<chr> <chr> <chr> <int>
1 administrativo Branco F 67
2 administrativo Branco M 15
3 administrativo Não Branco F 9
4 administrativo Não Branco M 6
5 servico Branco F 40
6 servico Branco M 26
7 servico Não Branco F 9
8 servico Não Branco M 8
9 vendas Branco F 14
10 vendas Branco M 21
11 vendas Não Branco F 3
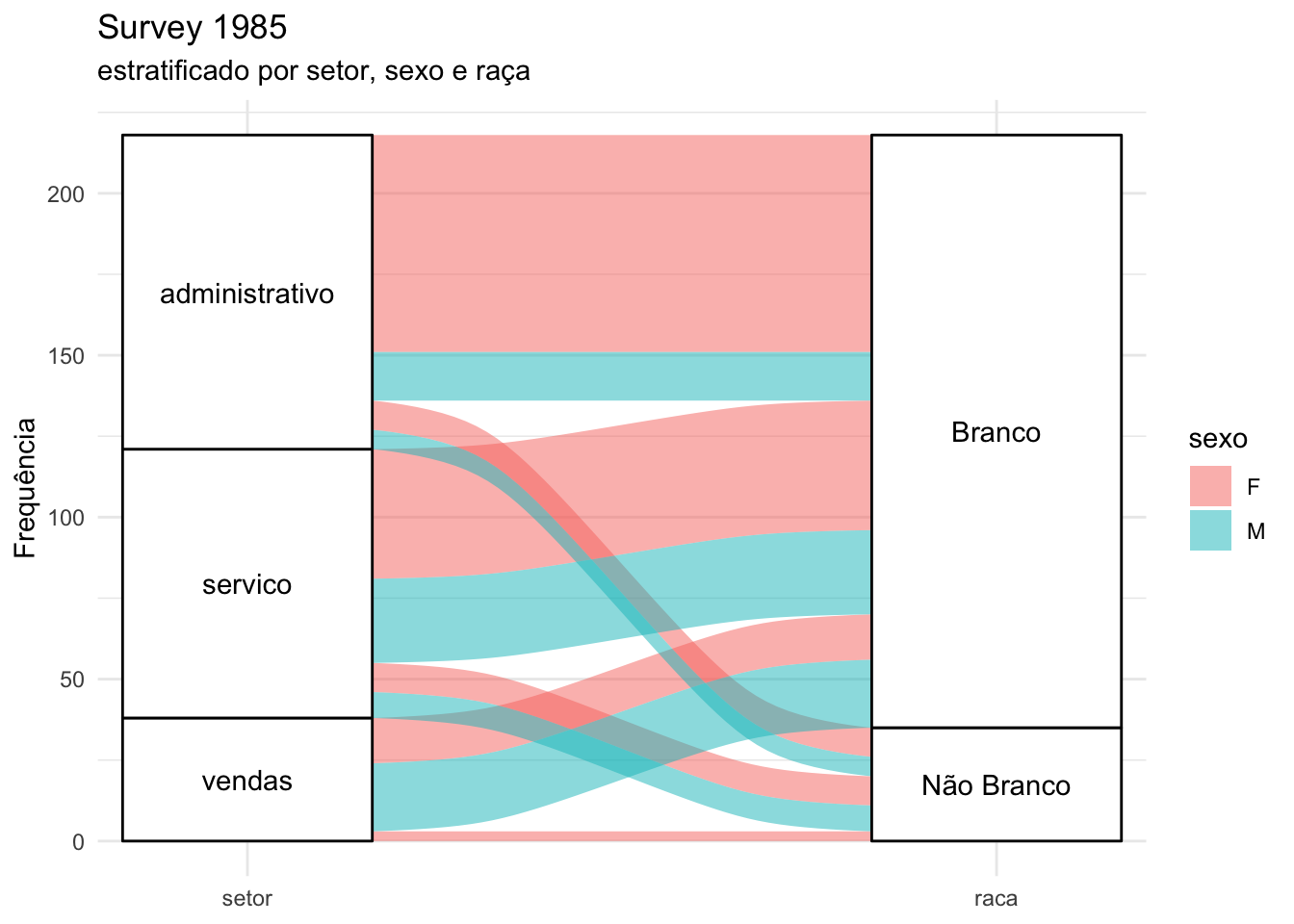
Com o diagrama a seguir, é possível, visualmente entendermos a distribuição de cada variável e a relação entre elas (setor, raça e sexo).
# carregando pacotelibrary(ggalluvial)# criando o diagramatabela_survey |>ggplot(mapping =aes(axis1 = setor,axis2 = raca,y = n)) +geom_alluvium(aes(fill = sexo)) +geom_stratum() +geom_text(aes(label =after_stat(stratum)),stat ="stratum") +scale_x_discrete(limits =c("setor", "raca"),expand =c(.1, .1)) +labs(title ="Survey 1985",subtitle ="estratificado por setor, sexo e raça",y ="Frequência") +theme_minimal()
No gráfico acima, percebemos que existe uma maior frequência de brancos do que não brancos na amostra. Dos setores, venda é o que possui menor frequência. Que o percentual de Brancos no setor administrativo é grande, e que entre estes a maioria é do sexo feminino.
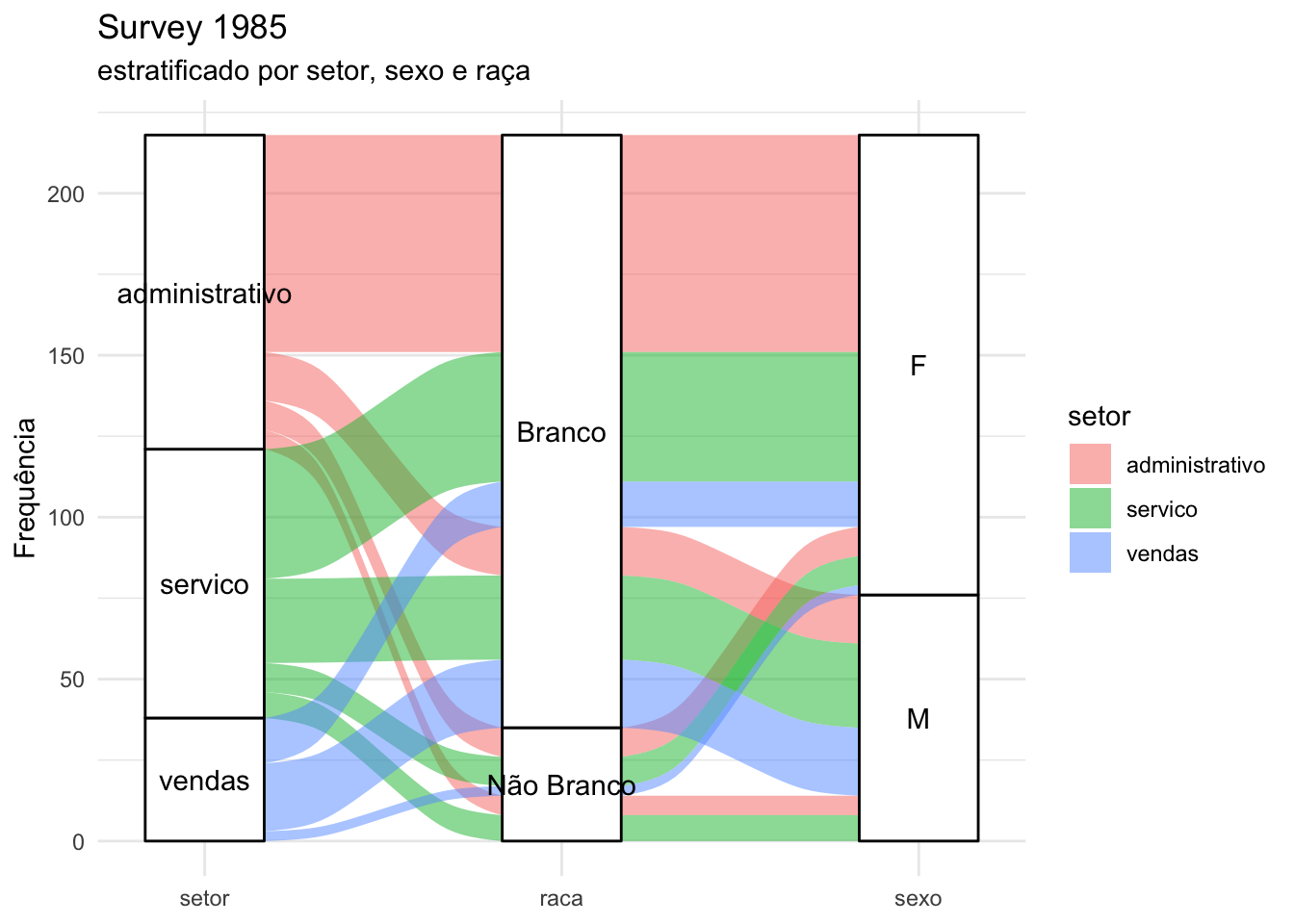
A seguir apresentamos uma modificação que pode ser útil no diagrama.
# criando outro diagramatabela_survey |>ggplot(mapping =aes(axis1 = setor,axis2 = raca,axis3 = sexo,y = n)) +geom_alluvium(aes(fill = setor)) +geom_stratum() +geom_text(aes(label =after_stat(stratum)),stat ="stratum") +scale_x_discrete(limits =c("setor", "raca","sexo"),expand =c(.1, .1)) +labs(title ="Survey 1985",subtitle ="estratificado por setor, sexo e raça",y ="Frequência") +theme_minimal()
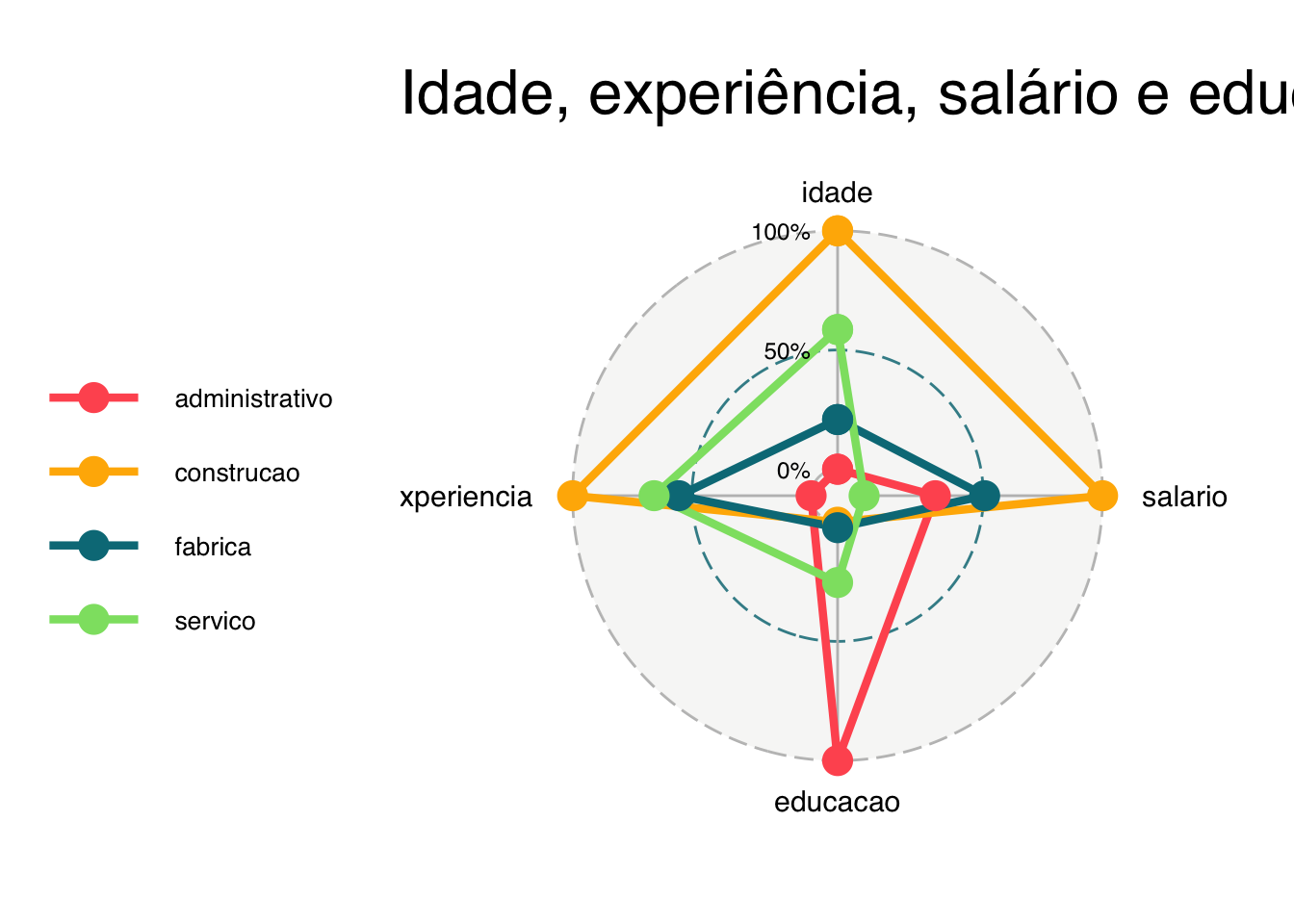
9.4Gráfico de radar
Um gráfico de radar (também conhecido como mapa de aranha ou estrela) compara um ou mais grupos (ou observações) com relação a três ou mais variáveis quantitativas.
Inicialmente, vamos instalar o pacote ggradar.
# Instalando o pacote ggradardevtools::install_github("ricardo-bion/ggradar")
# calculando as médias das variáveis e reescalonando as mesmasresumo_graf <- survey |>filter(setor %in%c("administrativo", "construcao", "fabrica", "servico"," vendas")) |>group_by(setor) |>summarise(idade =mean(idade, na.rm =TRUE),salario =mean(remuneracao, na.rm =TRUE),educacao =mean(educacao, na.rm =TRUE),experiencia =mean(exper, na.rm =TRUE)) |>mutate_at(.vars =vars(-setor),.funs = scales::rescale)# Visualizando o objetoresumo_graf
# carregando o pacotelibrary(ggradar)# generate radar chartggradar(resumo_graf, grid.label.size =4,axis.label.size =4, group.point.size =5,group.line.width =1.5,legend.text.size=10) +labs(title ="Idade, experiência, salário e educação")
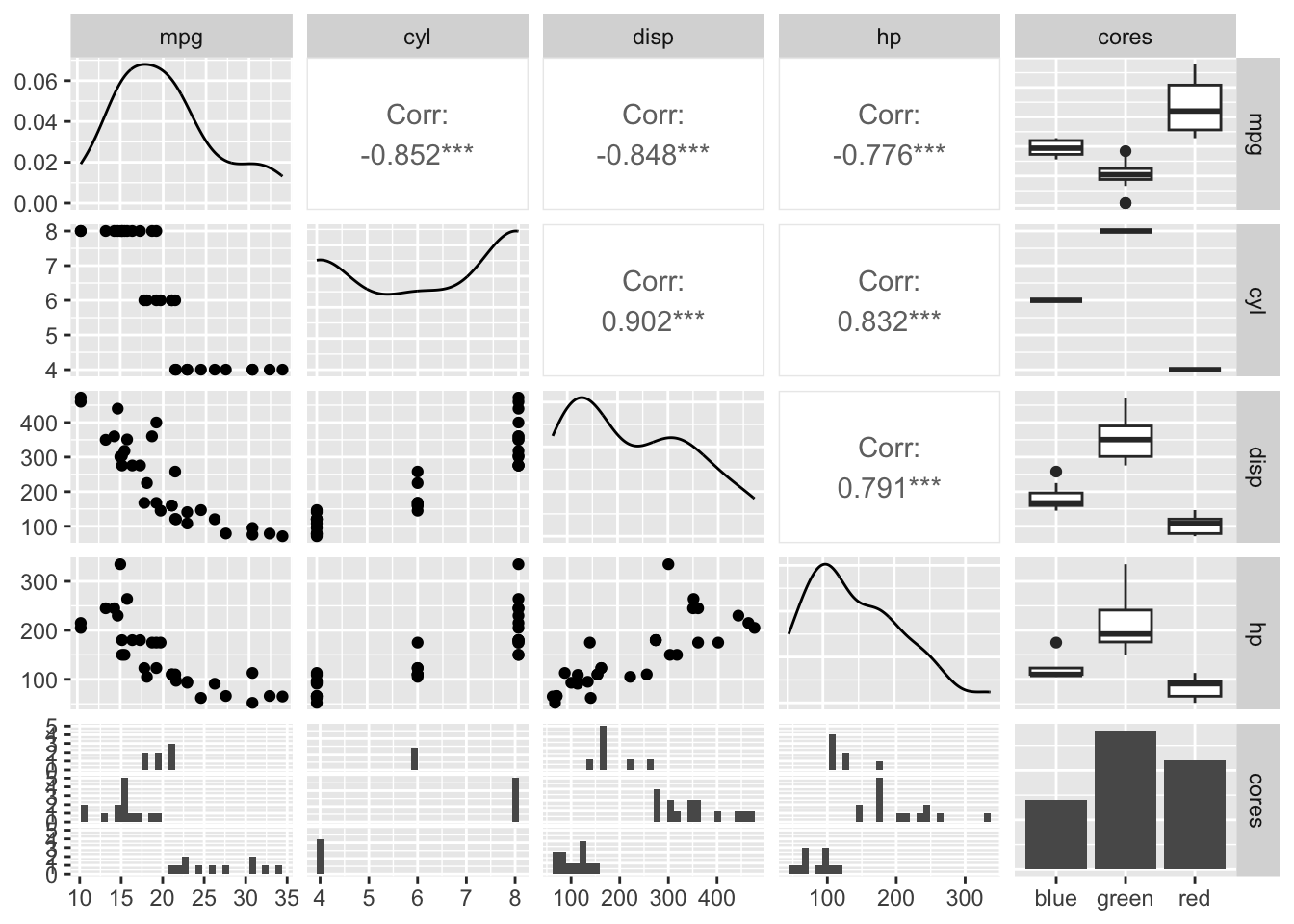
9.5Matriz de gráfico de dispersão
Uma matriz de gráfico de dispersão é uma coleção de gráficos de dispersão organizados em uma grade.
# carregando o pacotelibrary(GGally)
Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2
# retirando as variáveis nome e coresbase_carros_disp = base_carros |>select( mpg, cyl, disp, hp, cores)# criando uma matriz de gráfico de dispersãoggpairs(base_carros_disp)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Na diagonal principal ele apresenta o gráfico da densidade para as variáveis quantitativas e um gráfico de barras para as variáveis qualitativas.
Acima da diagonal principal, no cruzamento de duas variáveis quantitativas, ele nos mostra o valor da correlação das duas variáveis. No cruzamento de uma variável qualitativa e uma quantitativa, ele nos mostra o comportamento do boxplot da variável quantitativa para cada categoria da variável qualitativa.