Gráficos bivariados são visualizações usadas para avaliar a relação entre duas variáveis. O tipo de gráfico irá depender do tipo das duas variáveis envolvidas na análise, isto é, se as duas variáveis são qualitativas, se as duas são quantitativas ou se uma é qualitativa e outra quantitativa.
5.1 Qualitativa x Qualitativa
O gráfico mais simples utilizado para avaliar a relação entre duas variáveis qualitativas é o gráfico de barras. Essas barras podem ser empilhadas ou agrupadas.
Atividade:Crie um projeto chamado Analises Bivariadas. Após abra o Script Cap5. Use o espaço em branco no início do script para importar o arquivo survey85.csv e armazene-o em um objeto chamado survey.
A base de dados possui variáveis referentes a uma pesquisa survey realizada em 1985 contendo remuneração e outras características de trabalhadores, tais como:
salário por hora em dólares (remuneracao);
número de anos de educação (educacao);
sexo;
é hispânico? (hispanico);
é do sul? (sul);
é casado? (casado);
tempo de experiência de trabalho (exper);
idade;
setor de trabalho (setor).
#Visualizando o objetosurvey
# A tibble: 533 × 10
remuneracao educacao raca sexo hispanico sul casado exper idade setor
<dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 8.44 12 Branco F N N N 4 22 vend…
2 5.72 12 Branco F N N S 29 47 admi…
3 2.93 16 Branco F N N S 27 49 admi…
4 8.34 12 Branco F N N S 5 23 serv…
5 5.21 12 Branco F N N S 14 32 vend…
6 9.07 17 Não Bran… F N N S 32 55 admi…
7 3.92 14 Branco F N N N 15 35 admi…
8 4.27 12 Branco F N N S 38 56 serv…
9 5.55 12 Branco F N N N 7 25 serv…
10 5.28 17 Branco F N N N 5 28 prof
# ℹ 523 more rows
5.1.1Gráfico de barras agrupadas
O gráfico de barras agrupadas ajuda a avaliar a relação entre duas variáveis qualitativas. No ggplot2, a estrutura é semelhante ao gráfico de barras para uma variável qualitativa.
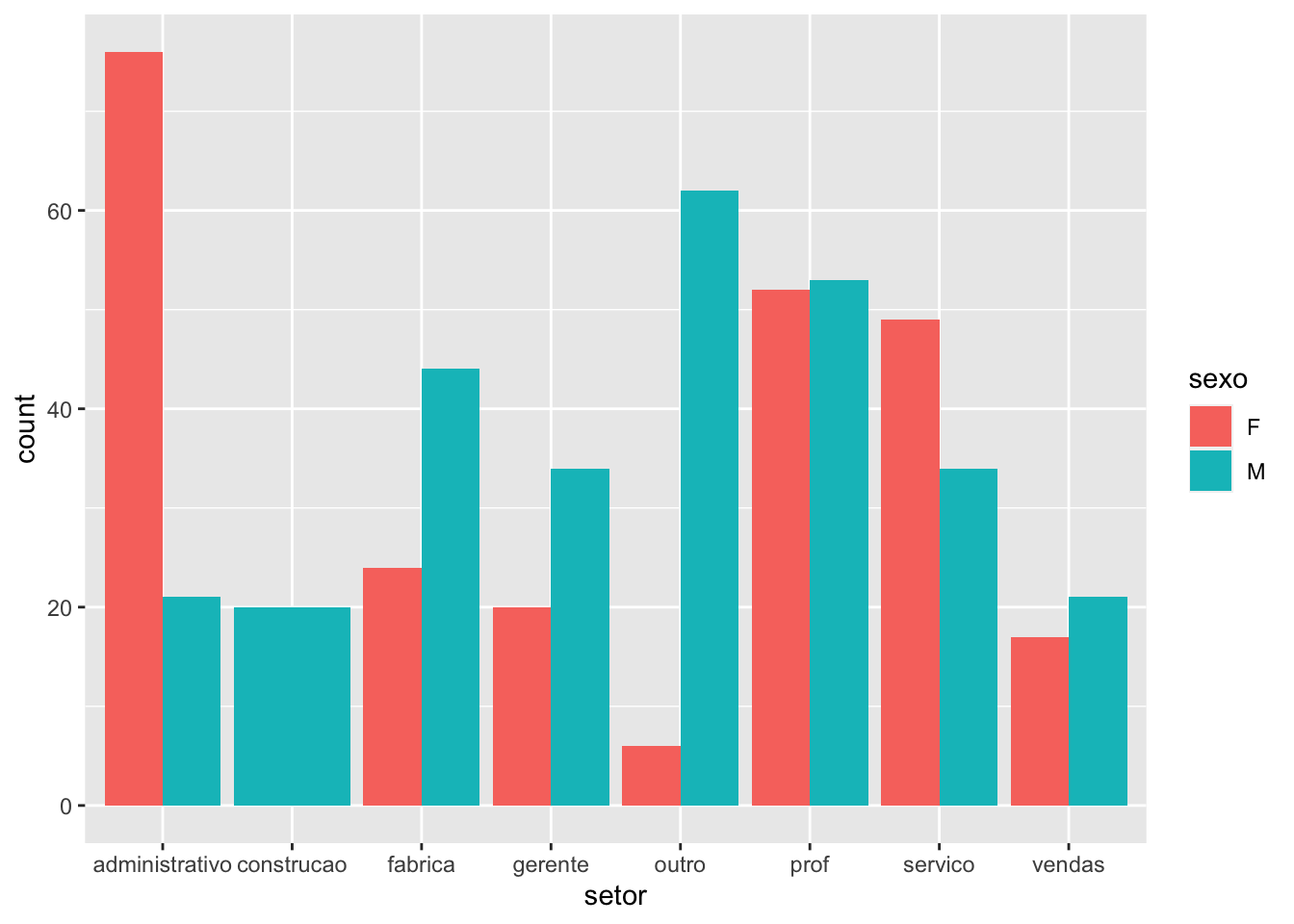
A seguir apresentamos como construir um gráfico de barras agrupadas para entender a relação entre as variáveis setor e sexo.
# Carregando pacoteslibrary(ggplot2)# Criando um gráfico de barras agrupado.survey |>ggplot(mapping =aes(x = setor,fill = sexo)) +geom_bar(position ="dodge")
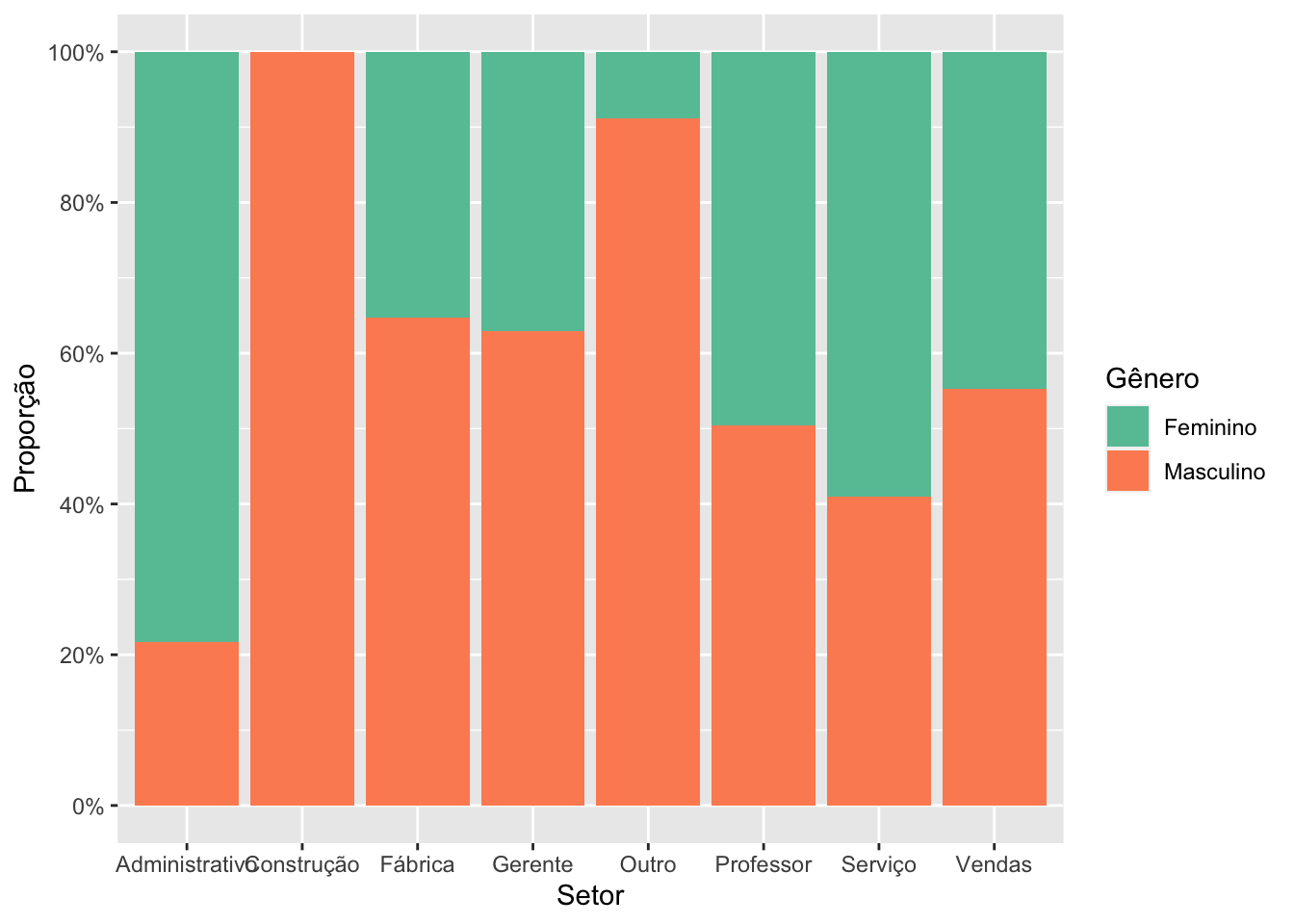
No exemplo acima, definimos no mapeamento da função ggplot o eixo x como a variável setor e fill como a variável sexo. Deste modo, serão construídas barras para cada categoria da variável sexo e apresentadas uma ao lado da outra para cada categoria da variável setor. O position = "dodge" é o responsável por deixar as barras agrupadas.
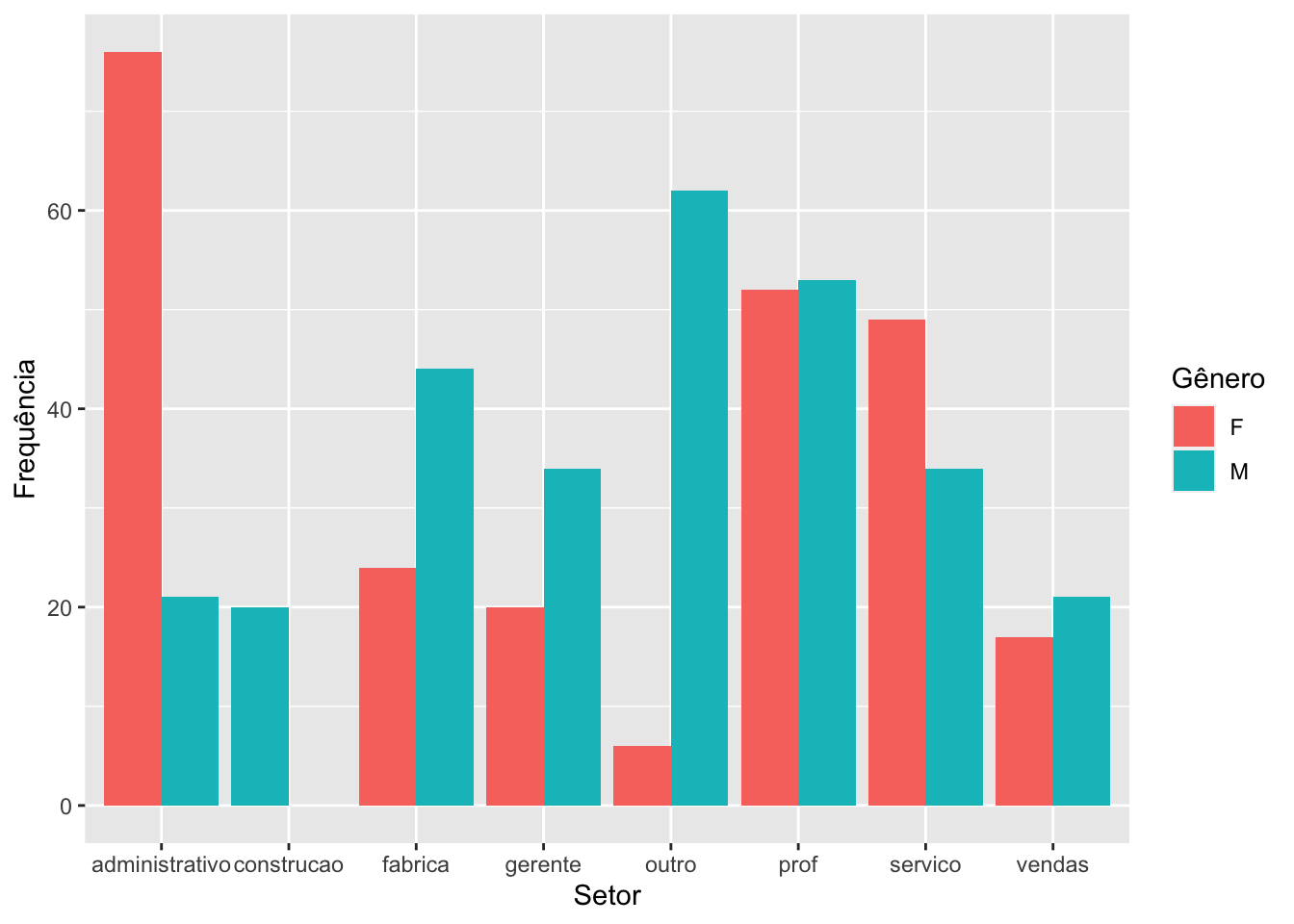
Entretando percebam que no setor de construção, não existem pessoas do sexo feminino e que a barra desta categoria está mais larga do que nos outros setores, isto ocorre porque o default da função é retirar as barras com frequência zero e fazer com que as barras restantes ocupem o todo o espaço. Para que isso não ocorra, podemos modificar o preenchimento do argumento position, como feito abaixo.
# Mantendo as categorias com frequência zero e mehorando os rótulossurvey |>ggplot(mapping =aes(x = setor,fill = sexo)) +geom_bar(position =position_dodge(preserve ="single")) +labs(x ="Setor",y ="Frequência",fill ="Gênero")
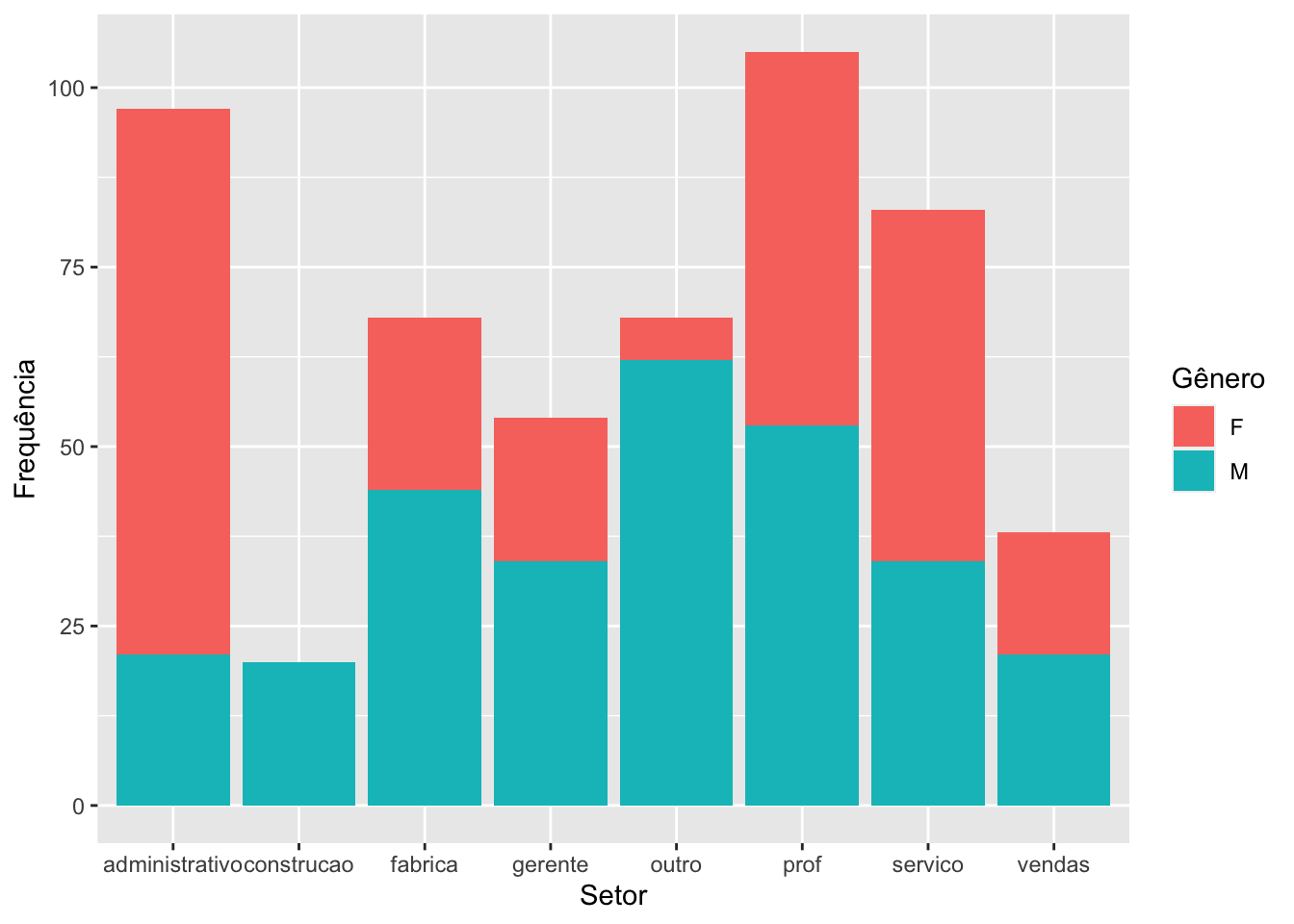
5.1.2Gráfico de barras empilhadas
O argumento position controla como as barras serão dispostas no gráfico. Abaixo, iremos apresentar as opções stack e fill.
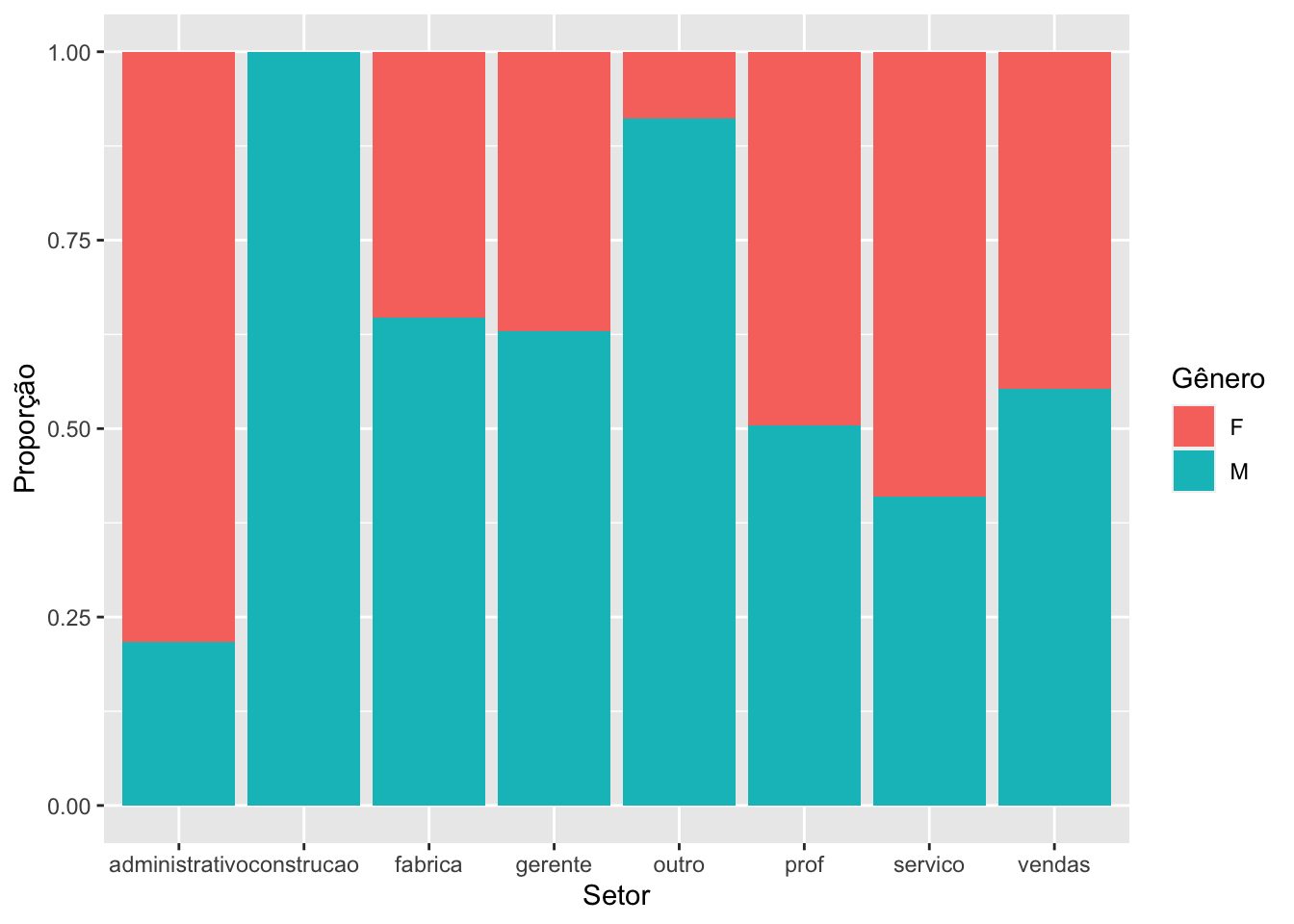
Quando estamos avaliando a distribuição do sexo por setores e a quantidade de pessoas em cada setor é diferente, é preferível trabalhar com o gráfico de barras empilhadas com proporção.
Claramente percebemos que parece existir uma diferença de distribuição do gênero dependendo do setor, indicando existir algum tipo de relação entre as variáveis.
A seguir, iremos apresentar algumas modificações para melhorar essa visualização.
# carregando pacotelibrary(scales)
Attaching package: 'scales'
The following object is masked from 'package:readr':
col_factor
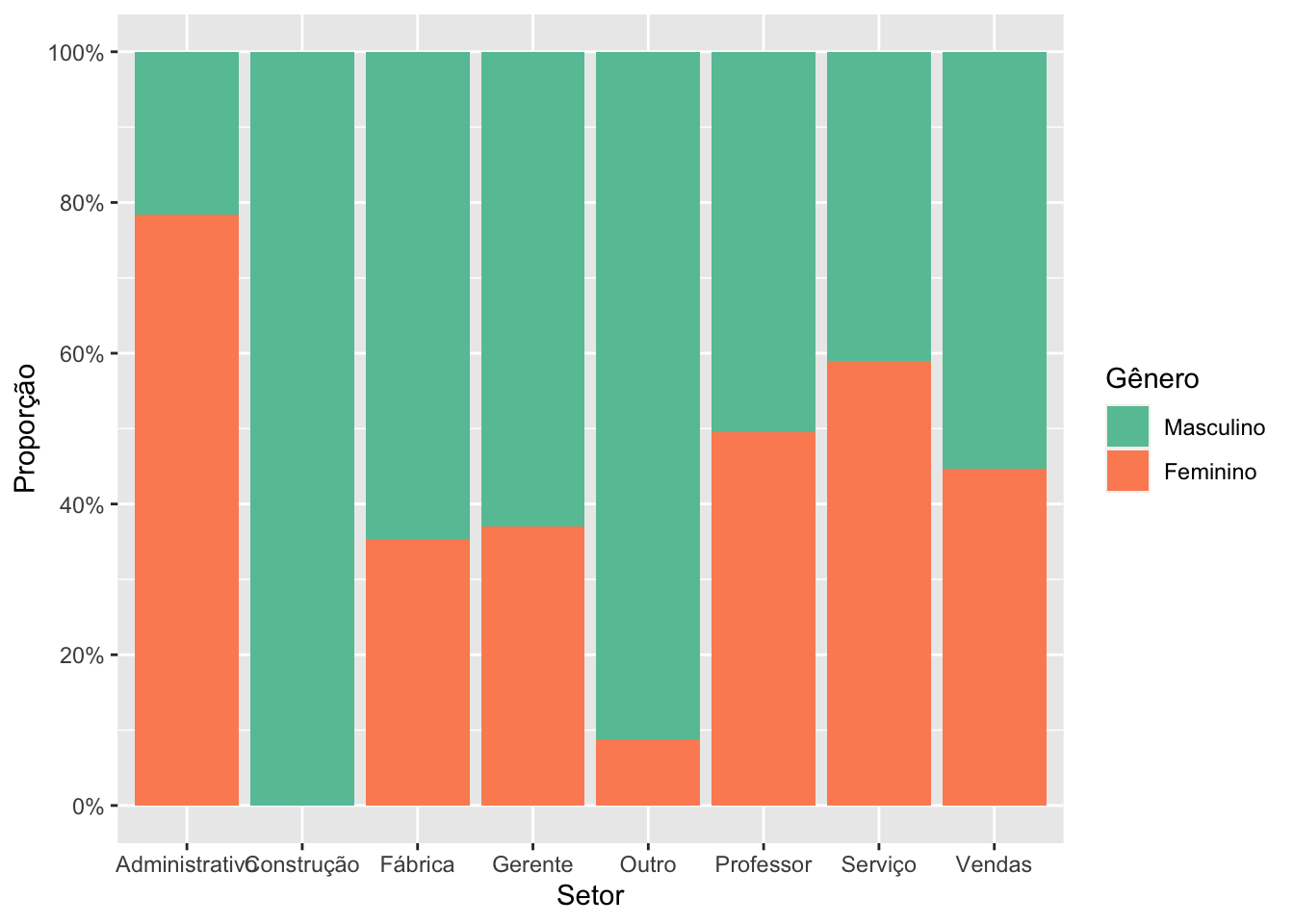
É possível fazer modificações na ordem das categorias que estão preenchendo as barras, modificando a função factor, por exemplo. No exemplo abaixo, nós indicamos que a ordenação da variável sexo se dava da seguinte forma, primeiro é o M e depois o F e os rótulos foram informados seguindo essa ordenação. Percebam que não modificamos a base, a modificação da variável foi feita somente na visualização criada.
# invertendo a ordem das categorias no preenchimento da barrasurvey |>ggplot(mapping =aes(x = setor,fill =factor(sexo,levels =c("M","F"),labels =c("Masculino","Feminino")))) +geom_bar(position ="fill") +scale_y_continuous(breaks =seq(0, 1, .2), label = percent) +scale_x_discrete(labels =c("vendas"="Vendas","servico"="Serviço","prof"="Professor","outro"="Outro","gerente"="Gerente","fabrica"="Fábrica","construcao"="Construção","administrativo"="Administrativo")) +scale_fill_brewer(palette ="Set2") +labs(x ="Setor",y ="Proporção",fill ="Gênero")
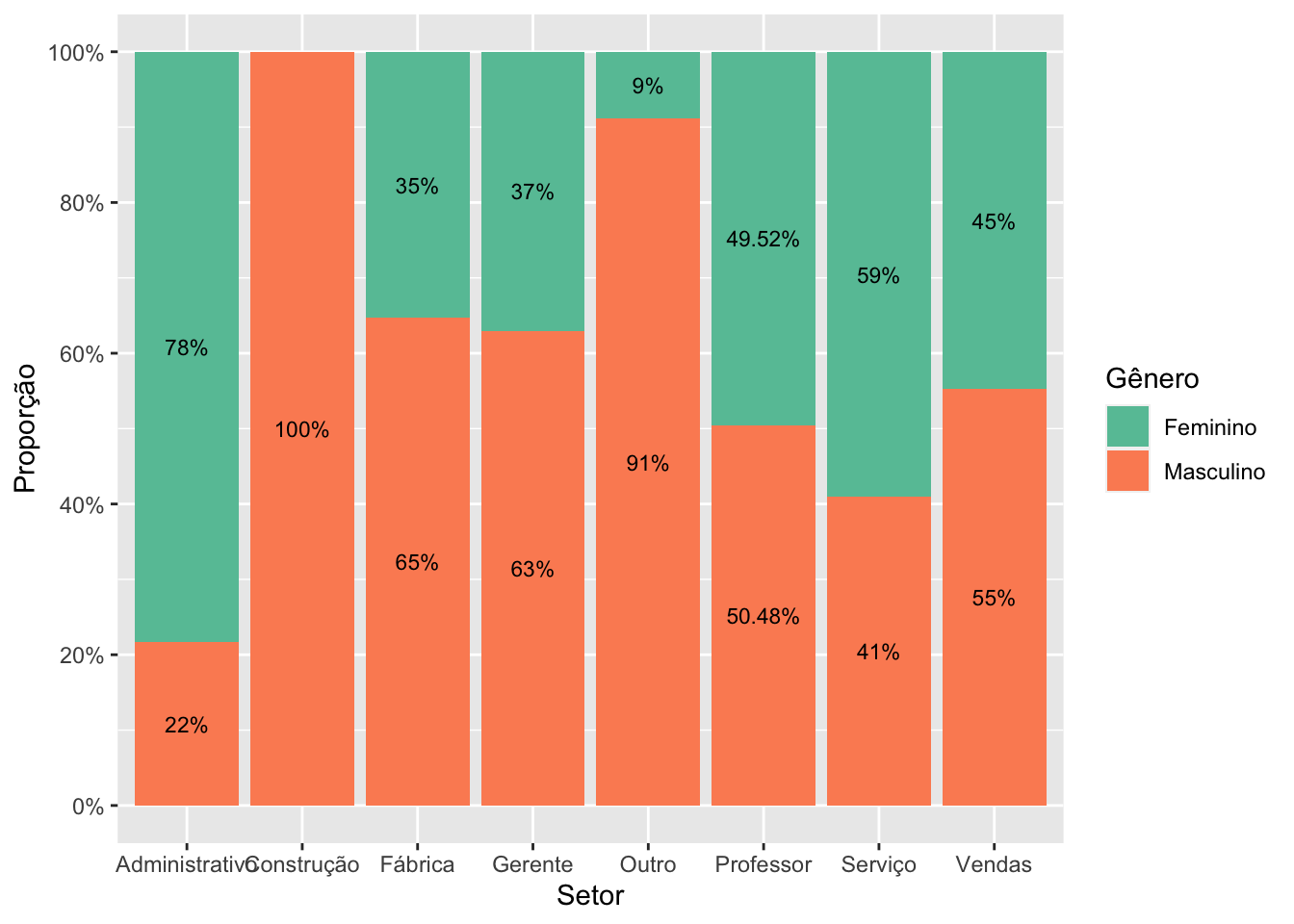
Também é possível incluir os percentuais no gráfico.
# carregando pacotelibrary(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
# criando um resumo do objeto surveyperct_setor_sexo <- survey |>group_by(setor, sexo) |>summarize(n =n()) |>mutate(pct = n/sum(n),rotulo = scales::percent(pct))
`summarise()` has grouped output by 'setor'. You can override using the
`.groups` argument.
# visualizando o objetoperct_setor_sexo
# A tibble: 15 × 5
# Groups: setor [8]
setor sexo n pct rotulo
<chr> <chr> <int> <dbl> <chr>
1 administrativo F 76 0.784 78%
2 administrativo M 21 0.216 22%
3 construcao M 20 1 100%
4 fabrica F 24 0.353 35%
5 fabrica M 44 0.647 65%
6 gerente F 20 0.370 37%
7 gerente M 34 0.630 63%
8 outro F 6 0.0882 9%
9 outro M 62 0.912 91%
10 prof F 52 0.495 49.52%
11 prof M 53 0.505 50.48%
12 servico F 49 0.590 59%
13 servico M 34 0.410 41%
14 vendas F 17 0.447 45%
15 vendas M 21 0.553 55%
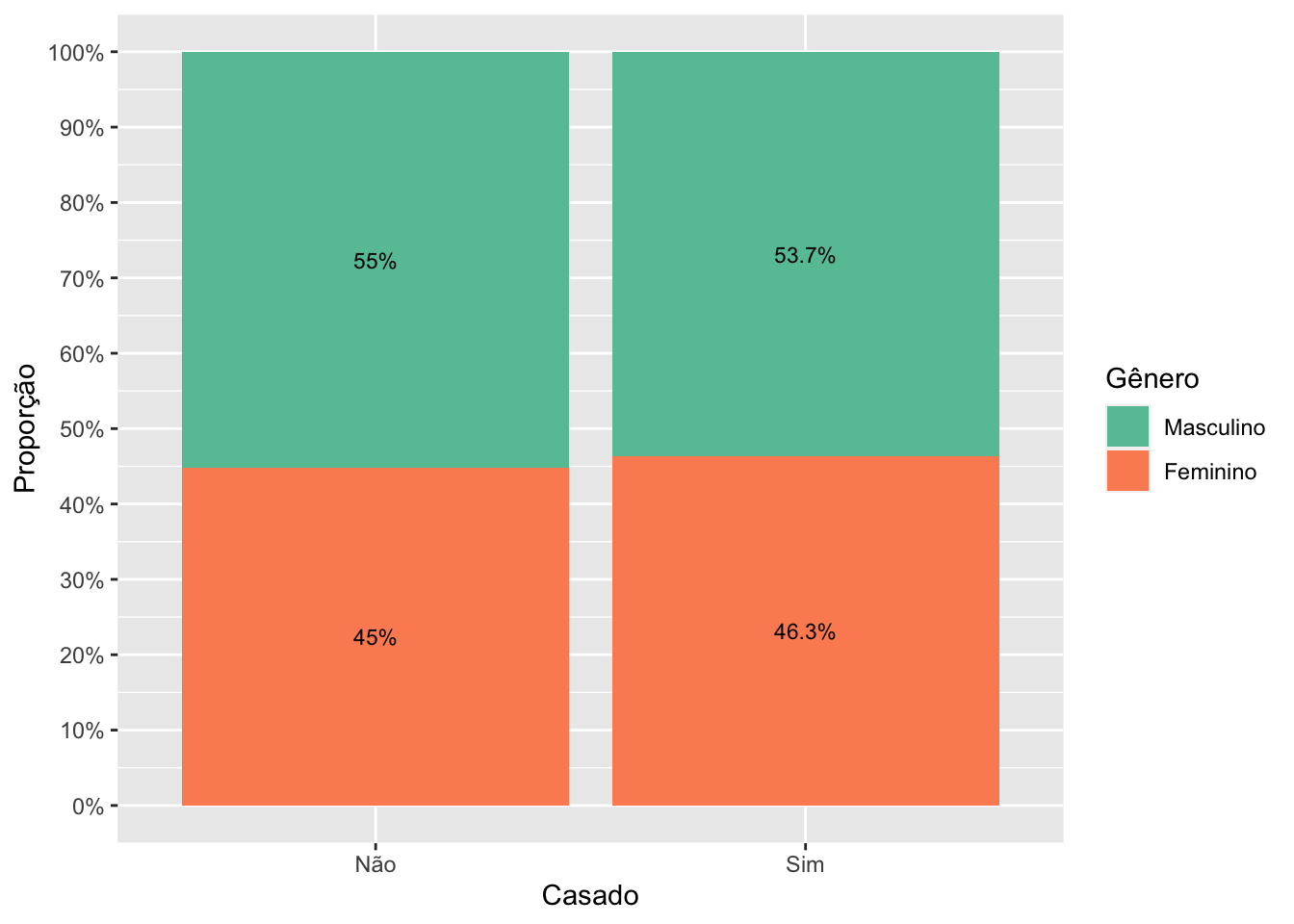
Atividade:Produza o código necessário para criar o gráfico abaixo.
5.2Quantitativa x Quantitativa
O gráfico mais simples utilizado para avaliar a relação entre duas variáveis quantitativas é o gráfico de dispersão. Nele é possível avaliar se existe algum tipo de relação entre as duas variáveis e qual a forma dessa relação. Linear? Não linear?
5.2.1Gráfico de dispersão
Um gráfico de dispersão é construído no ggplot2 por meio do geom_point. Para exemplificarmos a sua construção iremos precisar de uma nova base de dados.
Atividade:Importe o arquivo base_salario.txt e armazene-o em um objeto chamado base.
A base de dados possui duas variáveis:
salário em reais (salario);
número de anos completos de exeperiência na área que trabalha atualmente (experiencia).
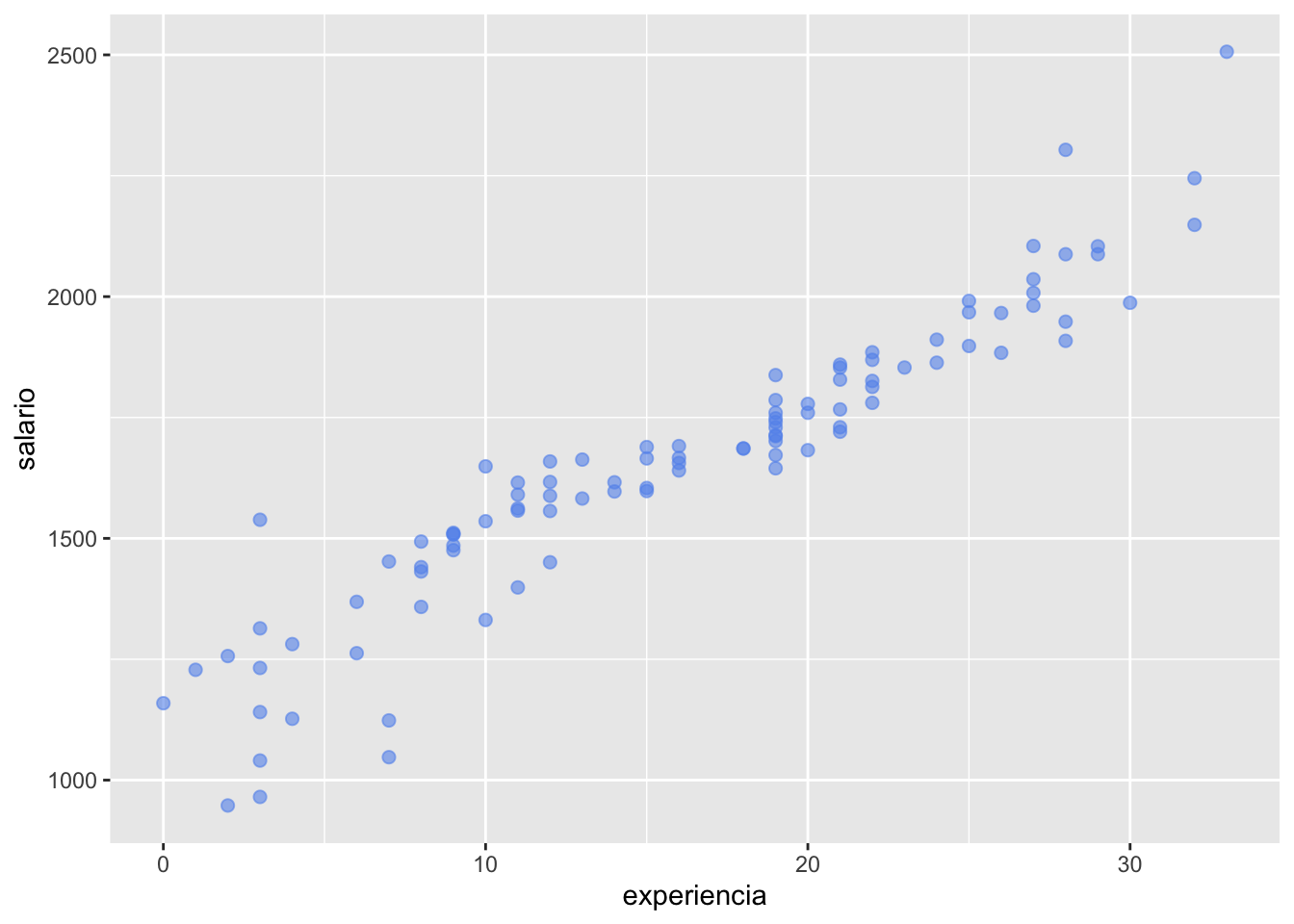
A seguir apresentamos como construir um gráfico de dispersão para as variáveis salário e experiência.
# gráfico de dispersãobase |>ggplot(mapping =aes(x = experiencia, y = salario)) +geom_point(color ="cornflowerblue", size =2, alpha = .6)
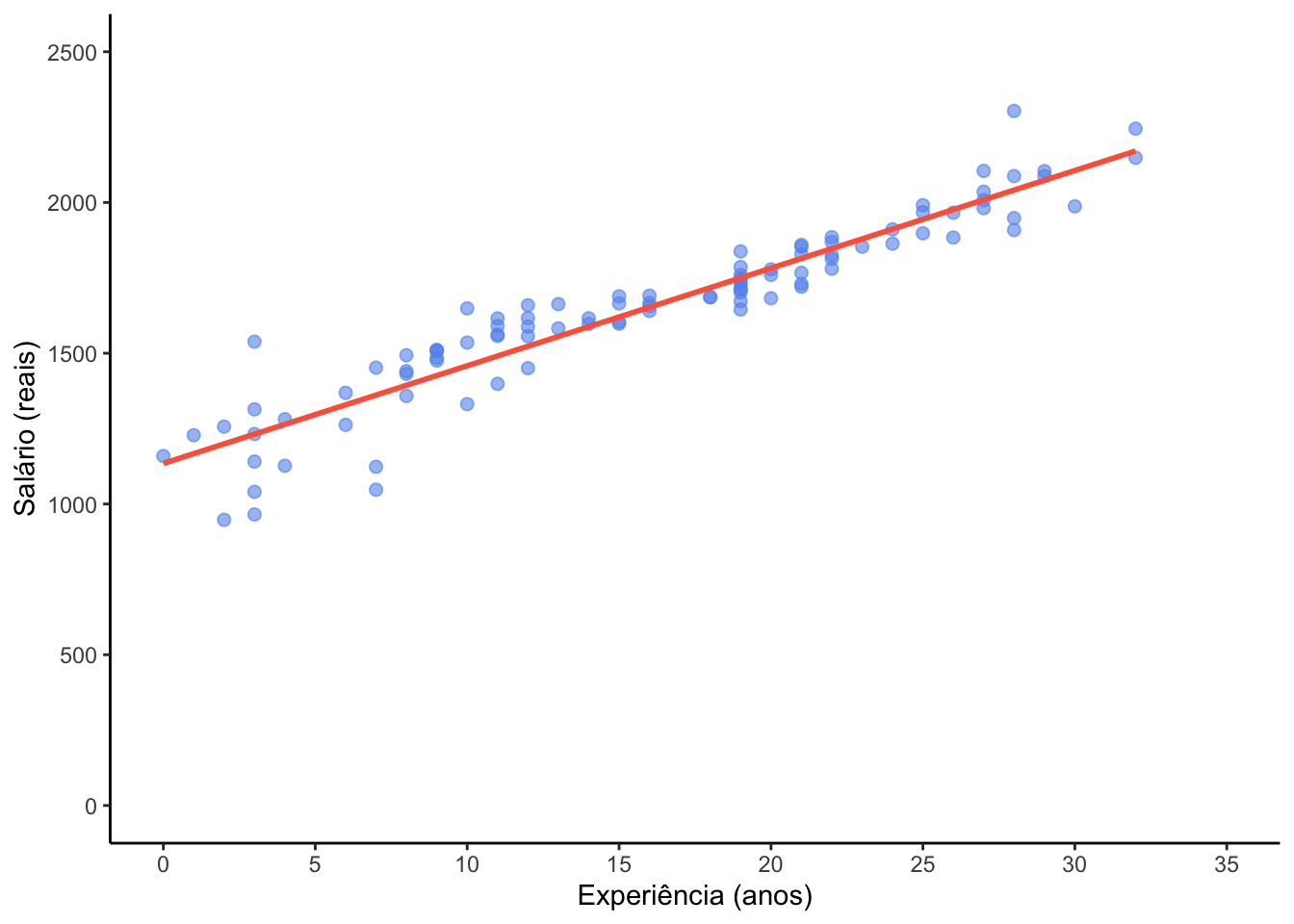
Claramente parece existir uma relação linear crescente entre as duas variáveis. A seguir, vamos fazer algumas melhorias no gráfico e incluir uma reta do modelo de regressão linear simples, já discutida anteriormente.
Existem diversos gráficos que podemos utilizar para investigar a relação entre uma variável qualitativa e uma variável quantitativa. A escolha do gráfico depende do que desejamos apresentar. Dentre os mais utilizados, podem mencionar os gráficos de barras usando estatísticas resumidas, os gráficos de densidade de kernel agrupados, os boxplot lado a lado e algumas variações, os gráficos de violino, os gráficos de média e os gráficos de Cleveland.
A seguir apresentaremos aplicações destes gráficos e outros.
5.3.1Gráfico de barras para medidas resumos
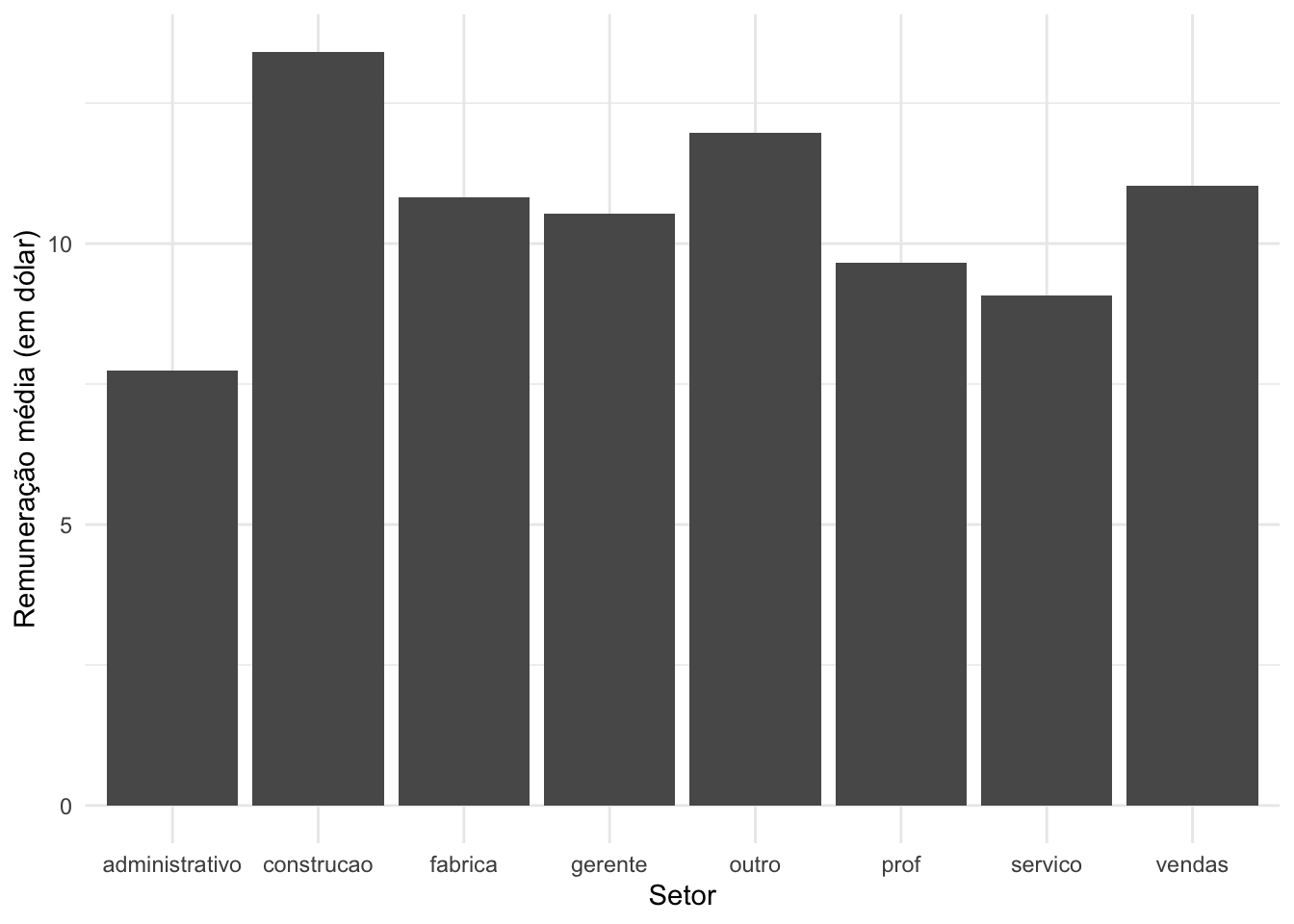
Com o geom_bar é possível fazermos gráficos de barras para medidas resumos de uma variável quantitativa de interesse, em função das categorias de uma variável qualitativa. A seguir, iremos apresentar as remunerações médias por setor e fazer um gráfico de barras apreentando as mesmas.
# criando um resumo do objeto surveymedia_grafico <- survey |>group_by(setor) |>summarize(media =mean(remuneracao, na.rm =TRUE))# visualizando o objetomedia_grafico
# criando o gráfico de barras para as médiasmedia_grafico |>ggplot(mapping =aes(x = setor,y = media)) +geom_bar(stat ="identity") +labs(x ="Setor",y ="Remuneração média (em dólar)") +theme_minimal()
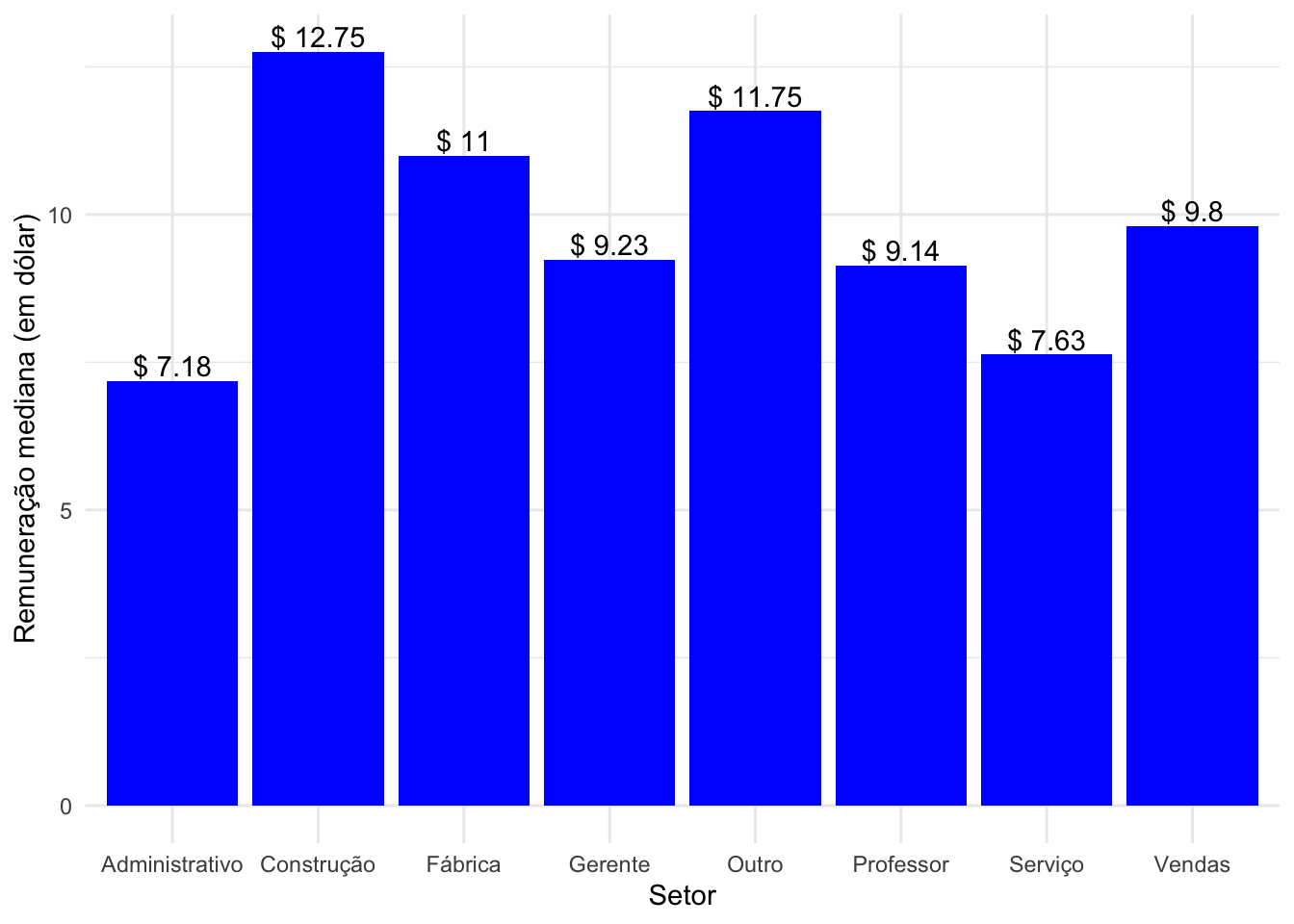
Atividade:Produza o código necessário para criar o gráfico abaixo.
5.3.2Gráfico de densidades por grupos
Podemos comparar a distribuição de uma variável quantitativa entre as categorias de uma variável qualitativa usando gráficos de densidades.
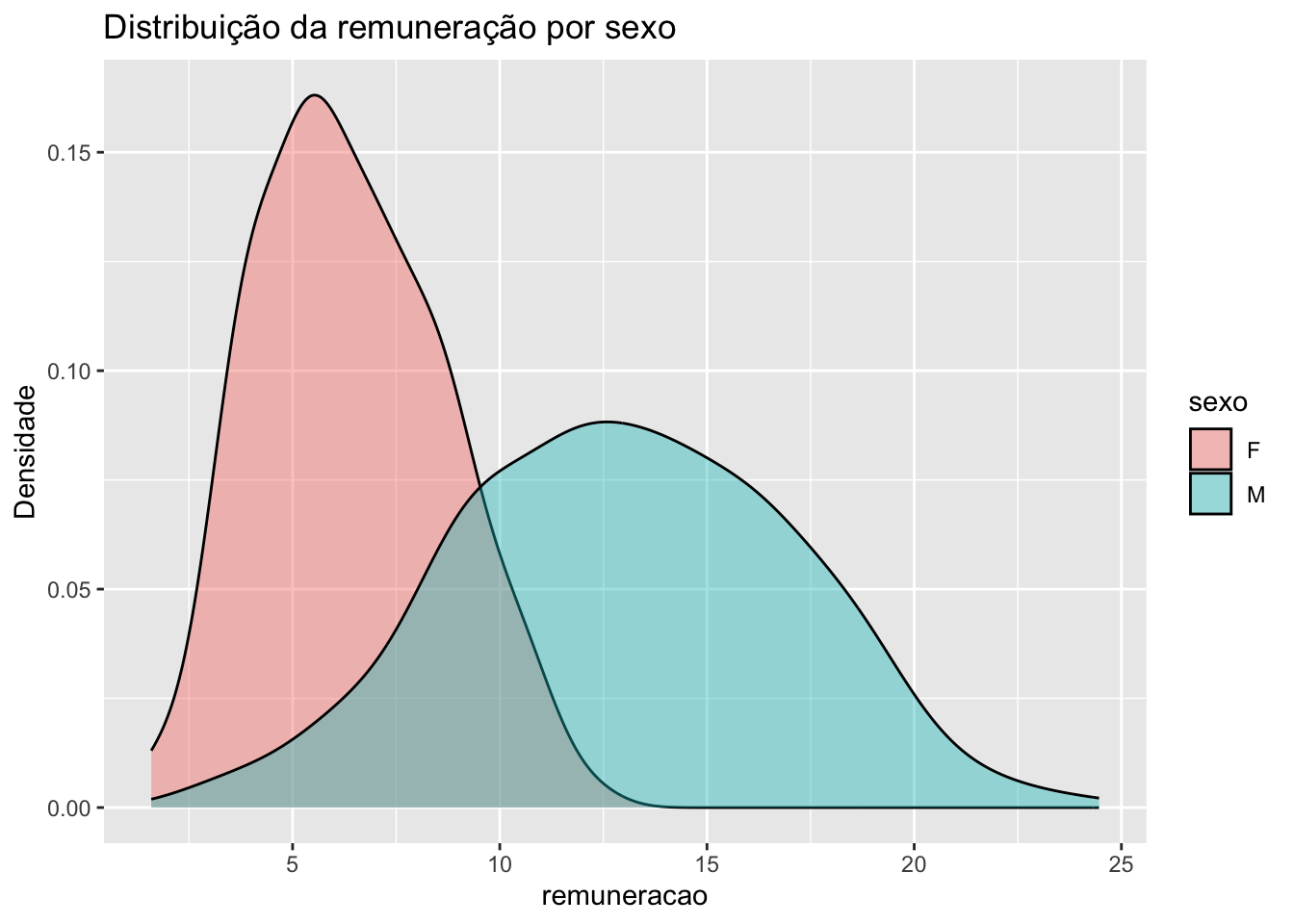
A seguir, apresentamos as densidades da variável remuneração para cada categoria da variável sexo.
# gráfico de densidade da remuneração por sexosurvey |>ggplot(mapping =aes(x = remuneracao,fill = sexo)) +geom_density(alpha =0.4) +labs(title ="Distribuição da remuneração por sexo",y ="Densidade")
O argumento alpha controla a transparência das densidades. Ele varia entre 0 (transparente) e 1 (opaco).
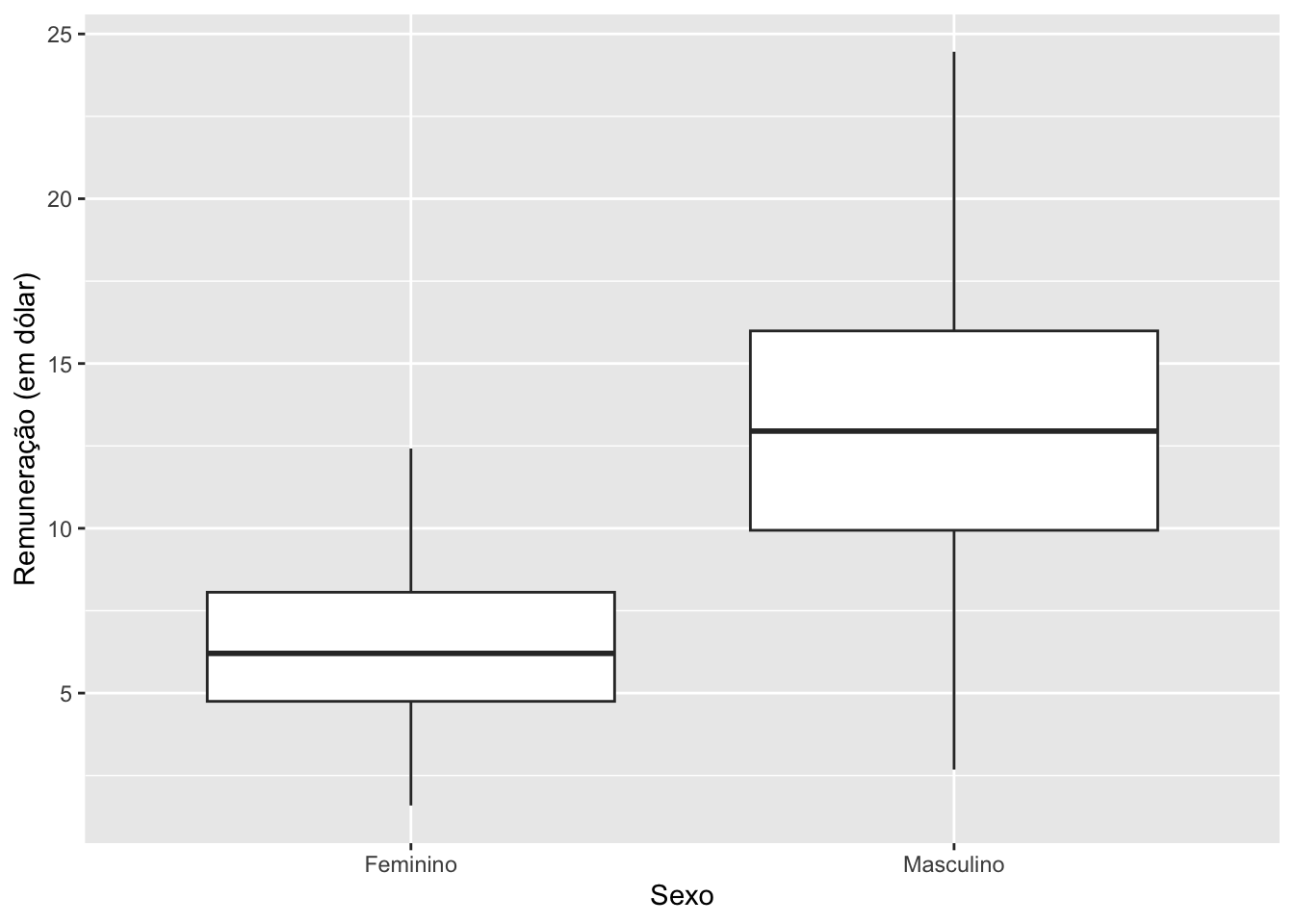
5.3.3Boxplots por grupos
Outra forma de comparar a distribuição de uma variável quantitativa entre as categorias de uma variável qualitativa é por meio do boxplot.
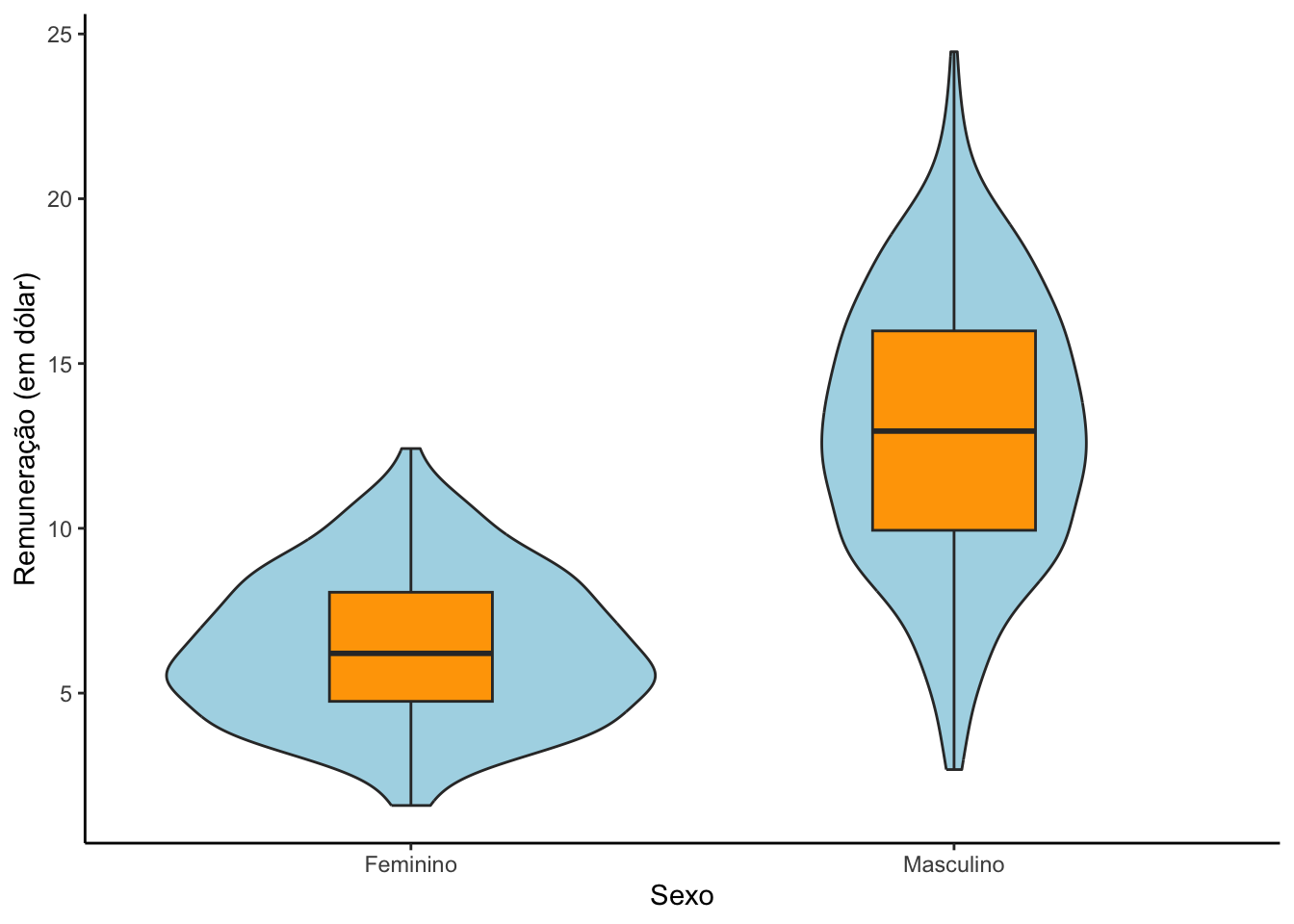
# Boxplot por sexosurvey |>ggplot(mapping =aes(y = remuneracao,x =factor(sexo,labels =c("Feminino","Masculino")))) +geom_boxplot() +labs(x ="Sexo",y ="Remuneração (em dólar)")
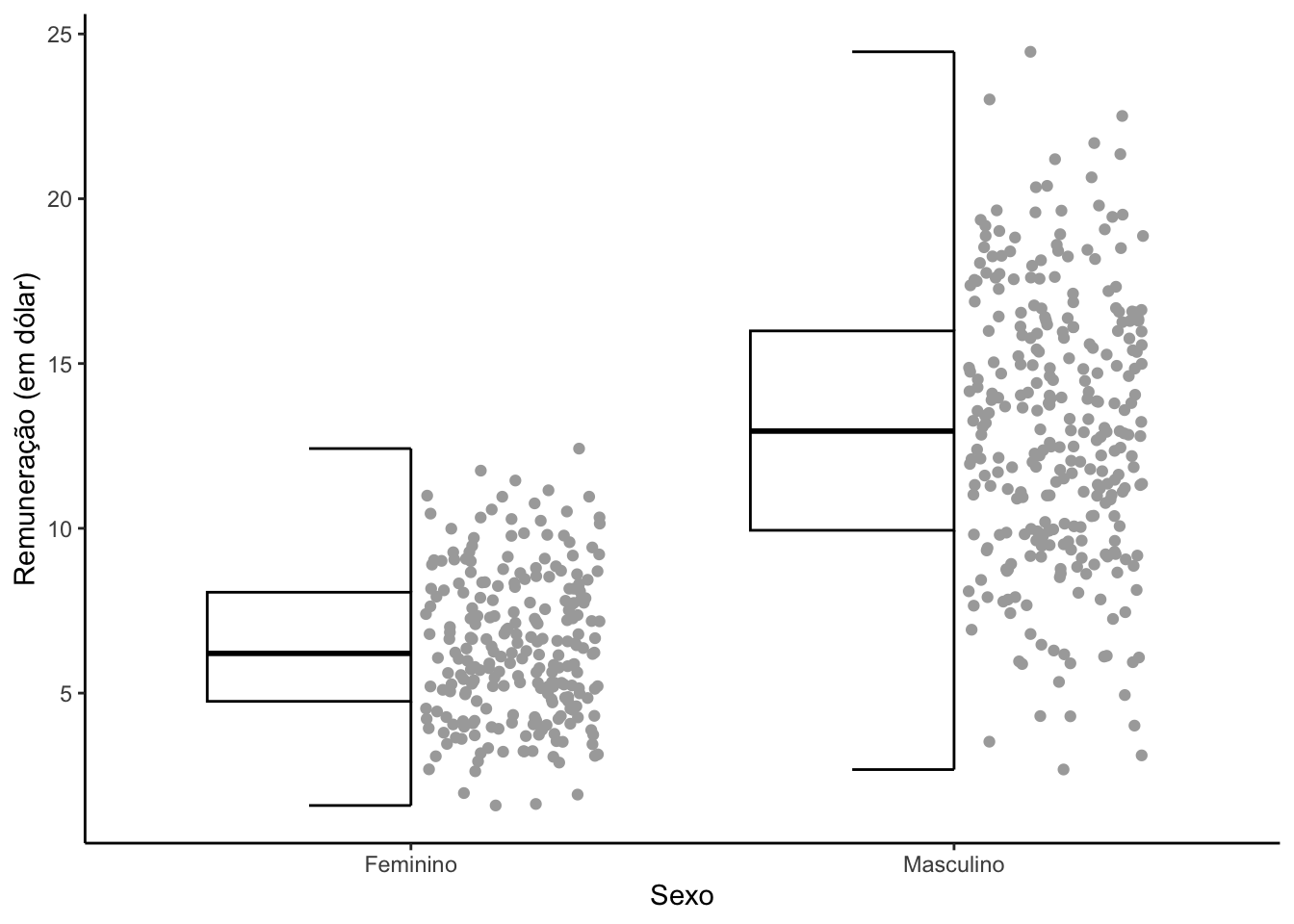
É possível criar um boxplot hibrido (meio boxplot e meio gráfico de dispersão).
Warning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.
Warning: Using the `size` aesthetic with geom_segment was deprecated in ggplot2 3.4.0.
ℹ Please use the `linewidth` aesthetic instead.
Warning: Using the `size` aesthetic with geom_crossbar was deprecated in ggplot2 3.4.0.
ℹ Please use the `linewidth` aesthetic instead.
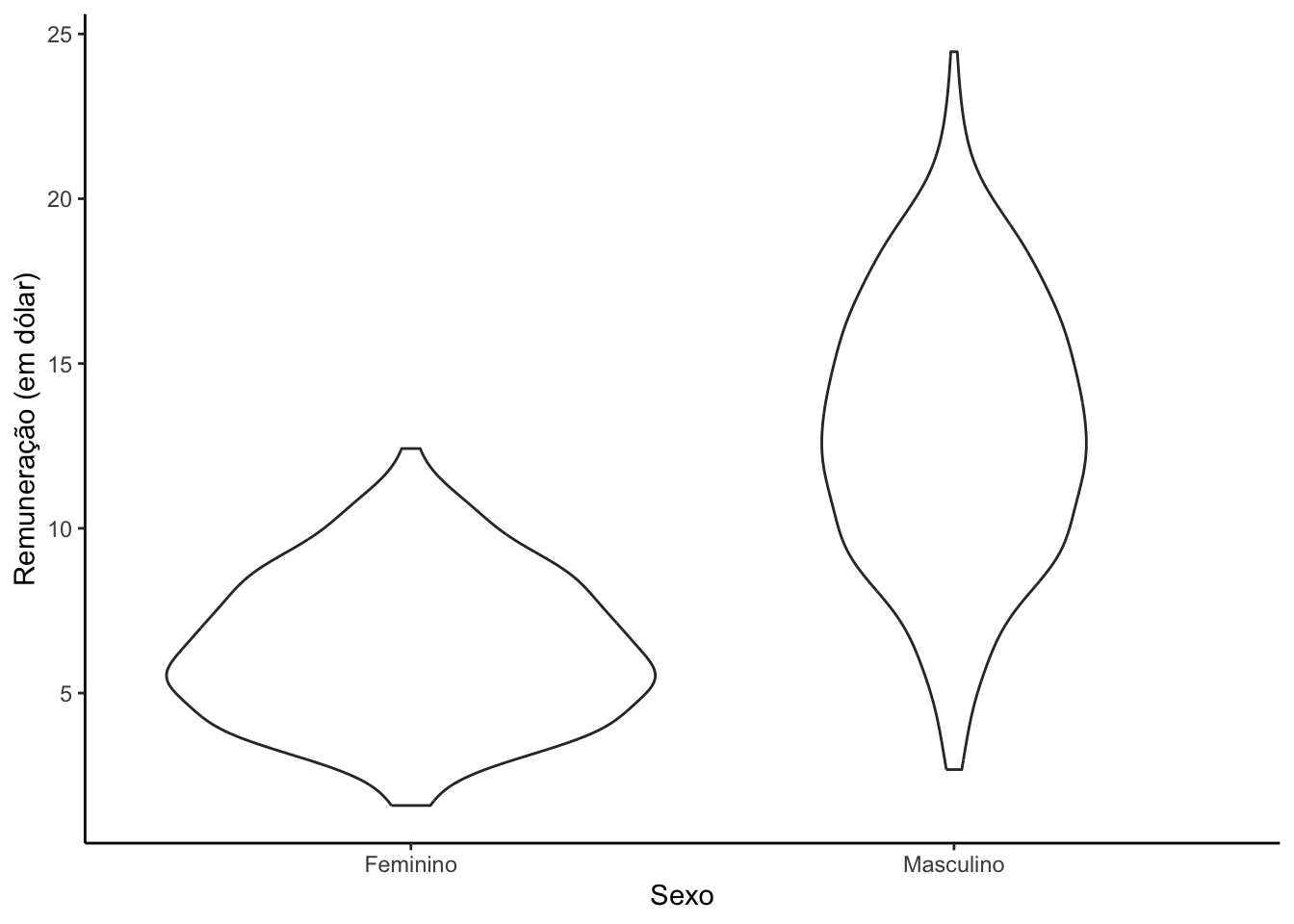
5.3.4Violinos por grupos
Os gráficos de violinos são semelhantes aos gráficos de densidades, porém são espelhados e rotacionados em 90 graus. Também é mais um gráfico que fala sobre o formato da distribuição de uma variável.
# Boxplot por sexosurvey |>ggplot(mapping =aes(y = remuneracao,x =factor(sexo,labels =c("Feminino","Masculino")))) +geom_violin() +labs(x ="Sexo",y ="Remuneração (em dólar)") +theme_classic()
É possível fazer uma combinação do gráfico de violinos com s boxplot? SIM! Vejamos como construir uma combinação deste tipo abaixo.
# combinando o violino com o boxplotsurvey |>ggplot(mapping =aes(y = remuneracao,x =factor(sexo,labels =c("Feminino","Masculino")))) +geom_violin(fill ="Light Blue") +geom_boxplot(fill ="orange",width = .3) +labs(x ="Sexo",y ="Remuneração (em dólar)") +theme_classic()
O argumento width é o responsável por diminuir as caixas do boxplot para que as mesmas fiquem dentro do formato dos violinos.
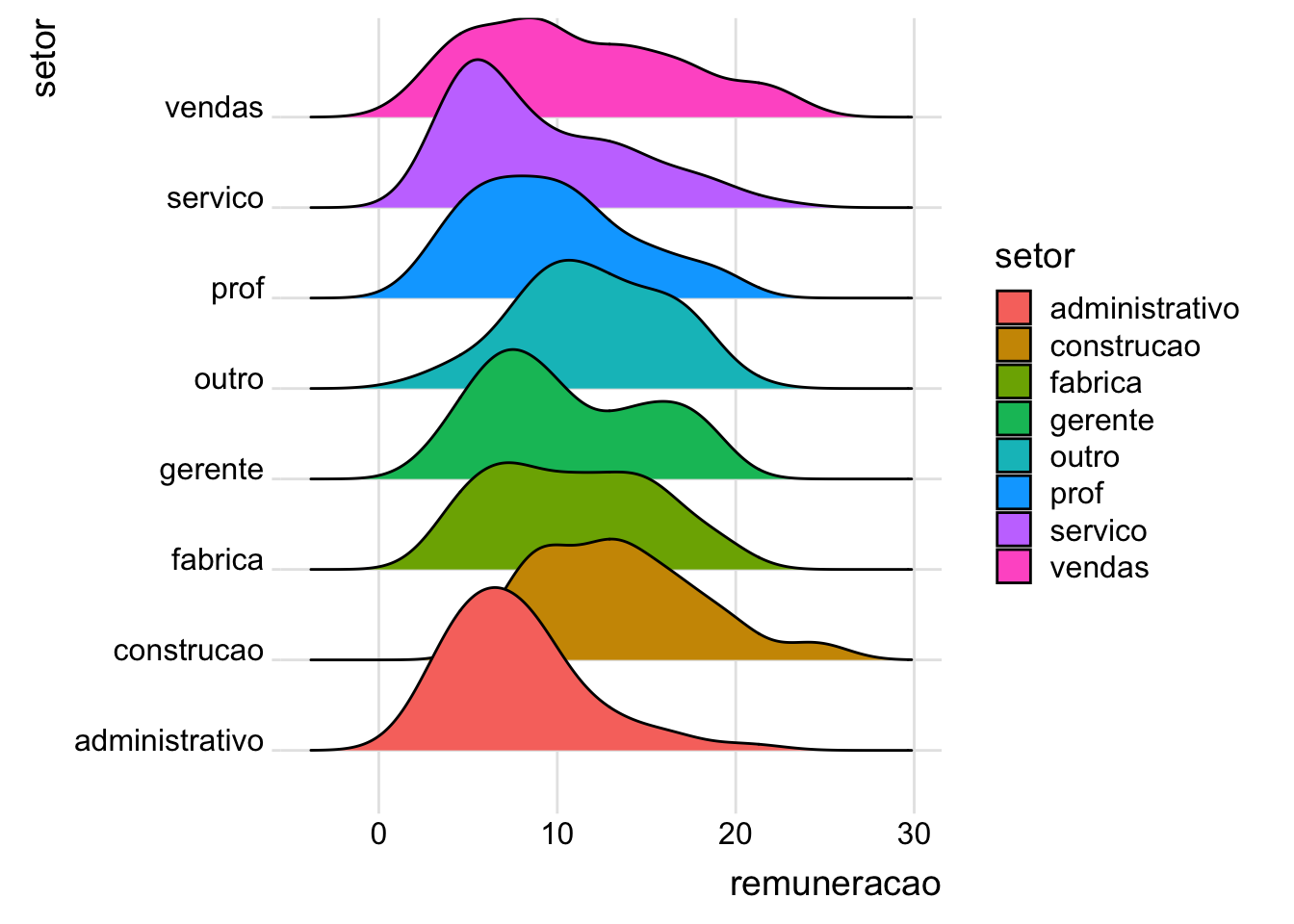
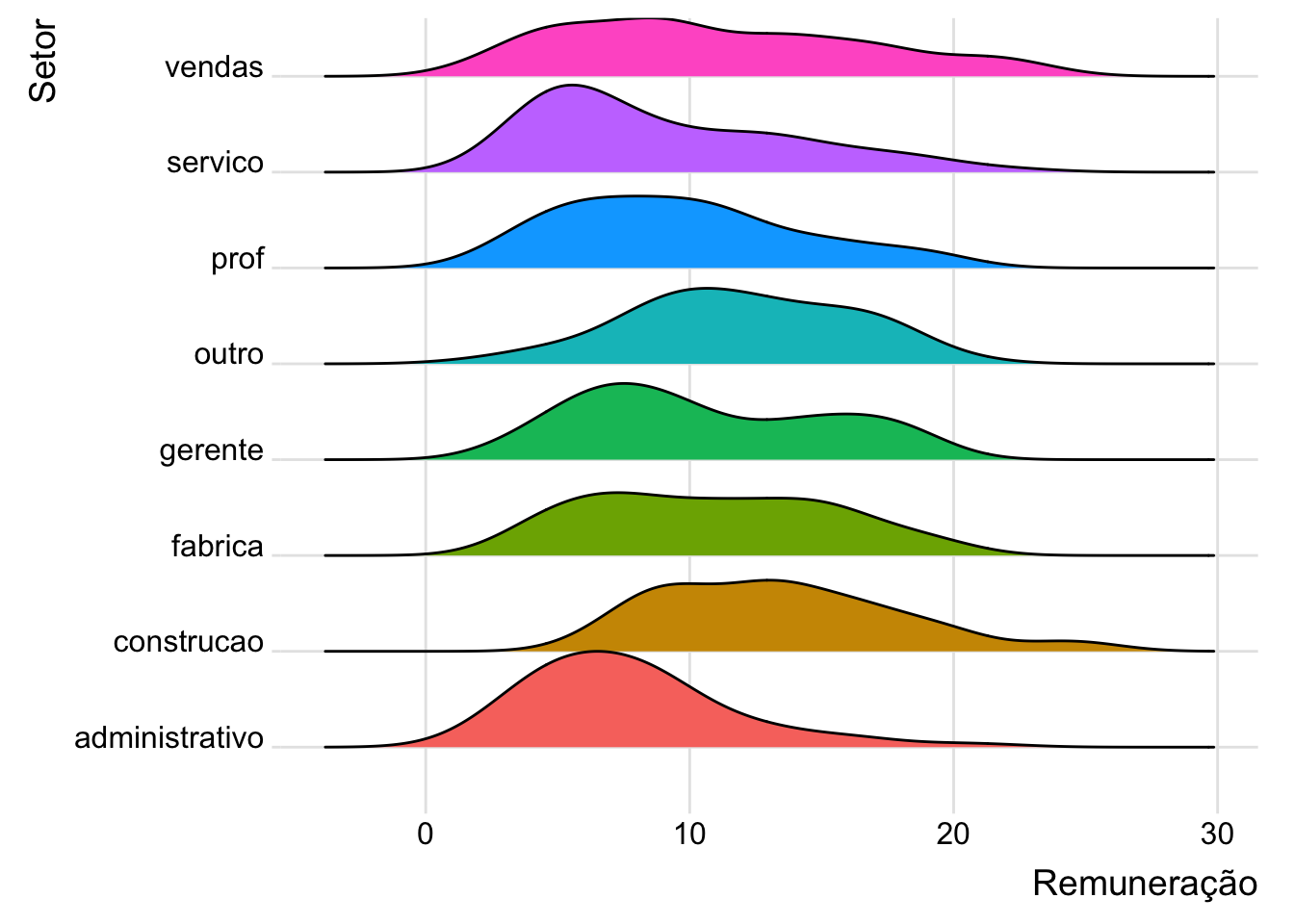
5.3.5Gráficos ridgelines
Os gráficos ridgelines mostram a distribuição de uma variável quantitativa para as diversas categorias de uma variável qualitativa. Estes gráficos são muito semelhantes aos gráficos de densidades, porém eles são separados de forma vertical (como se usássemos um facet, porém ocupam menos espaço). É um gráfico mais interessante quando possuímos um número de categorias não muito pequeno.
# carregando pacotelibrary(ggridges)# ridgelines de remuneração por sexosurvey |>ggplot(mapping =aes(y = setor,x = remuneracao,fill = setor)) +geom_density_ridges() +theme_ridges()
Picking joint bandwidth of 1.8
Como podemos perceber, a informação da legenda não é necessária. Nem as cores seriam, elas estão sendo usadas para “embelezar” o gráfico. A seguir, usamos o scale para diminuir a sobreposição das densidades e o legend.position = "none" para retirar a legenda.
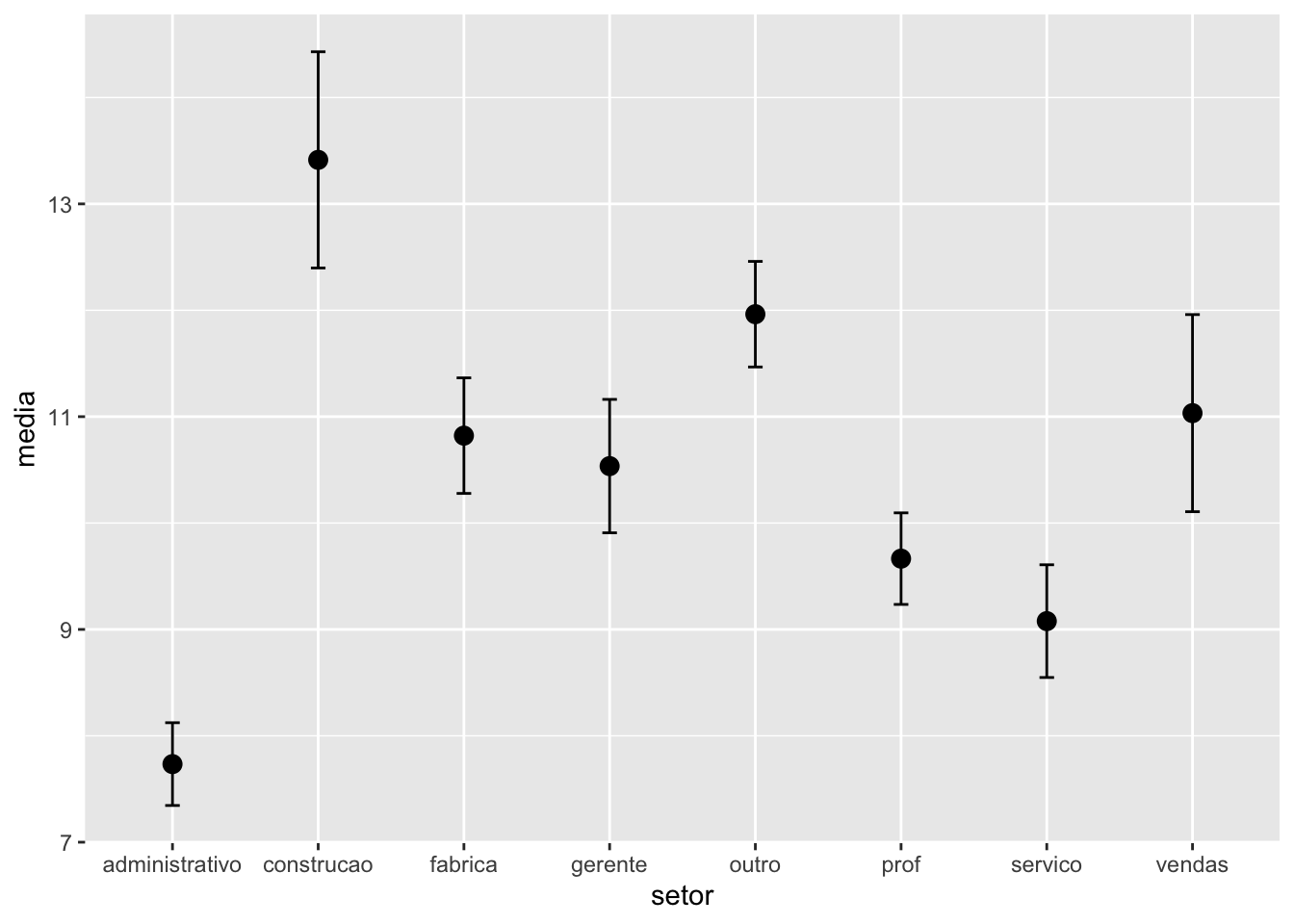
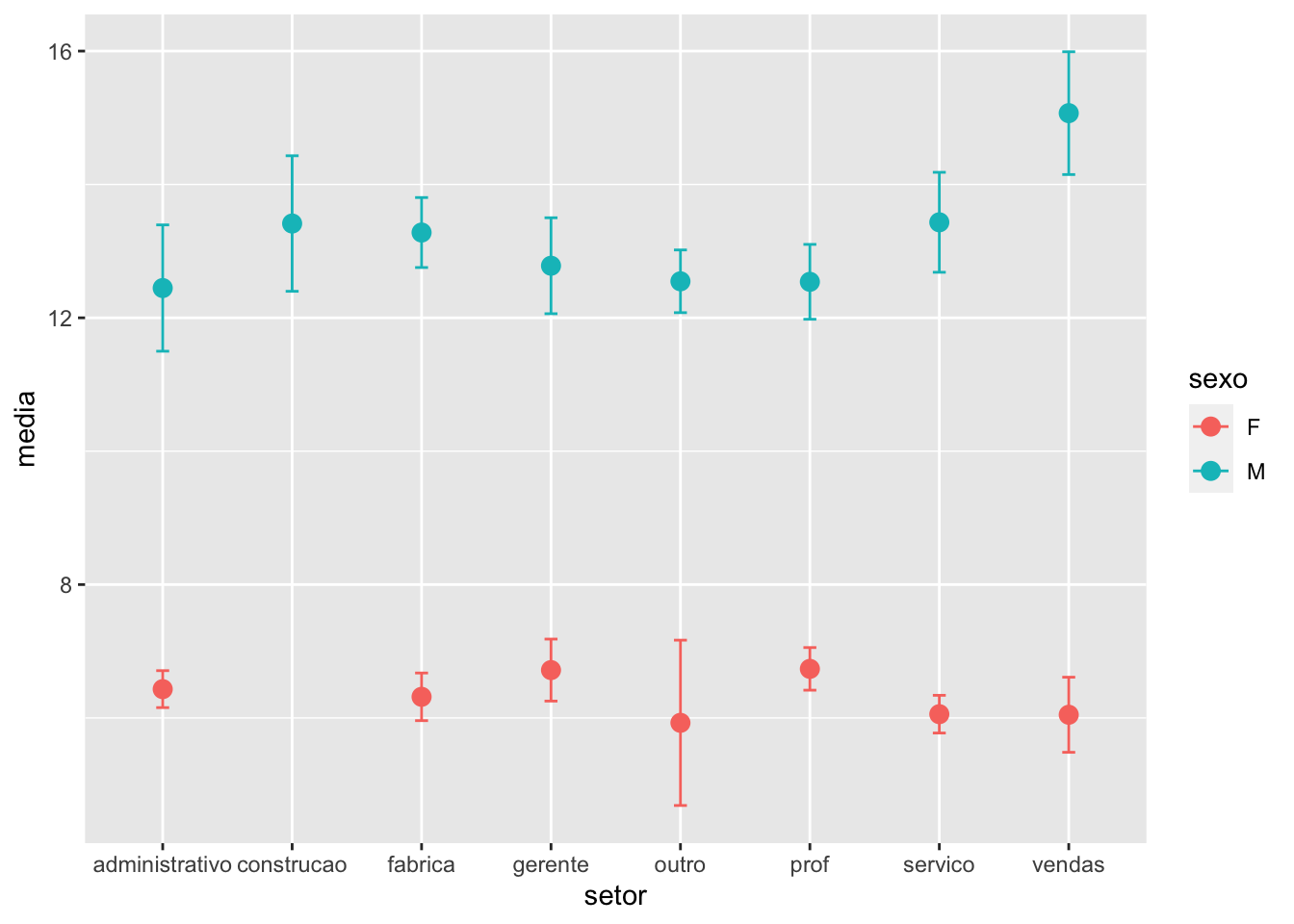
O gráfico de médias com barras de erro é um método popular para comparar grupos com relação a uma variável numérica (quantitativa). A barra de erro pode representar um desvio padrão, um erro padrão da média ou um intervalo de confiança. Nesta seção, representaremos um gráfico com as médias e os erros padrões.
# calculando a media e as diversas medidas para as barrasmedia_erros <- survey |>group_by(setor) |>summarize(n =n(),media =mean(remuneracao),desvio =sd(remuneracao),erro.padrao = desvio /sqrt(n))# gráfico de médias com os erros padrõesmedia_erros |>ggplot(mapping =aes(x = setor,y = media)) +geom_point(size =3) +geom_errorbar(aes(ymin = media - erro.padrao, ymax = media + erro.padrao), width = .1)
Suponha que o nosso interesse é verificar o comportamento das médias por sexo em cada setor?
# calculando a media e as barras por sexo e setormedia_erros <- survey |>group_by(setor,sexo) |>summarize(n =n(),media =mean(remuneracao),desvio =sd(remuneracao),erro.padrao = desvio /sqrt(n))
`summarise()` has grouped output by 'setor'. You can override using the
`.groups` argument.
# gráfico de médias com os erros padrõesmedia_erros |>ggplot(mapping =aes(x = setor,y = media,group = sexo,color = sexo)) +geom_point(size =3) +geom_errorbar(aes(ymin = media - erro.padrao, ymax = media + erro.padrao), width = .1)
Além de calcular as medidas por setor e por sexo, usamos no mapeamento do ggplot o argumento group = sexo. Este argumento faz com que todos os geoms seguintes sejam executados para cada categoria da variável indicada em group. Esse argumento está presente em diversas funções do pacote ggplot2 sendo uma ferramenta extremamente valiosa para a criação de gráfico. Outros exemplos serão apresentados nas seções a seguir.
5.3.7Gráfico de Cleveland
Estes gráficos são úteis para comparar uma medida numérica para um grande número de grupos.
Atividade:Importe o arquivo PNUD.csv e armazene-o em um objeto chamado base_PNUD.
A base de dados possui duas variáveis:
ano;
muni (nome do município);
idhm (índice de desenvolvimento humano municipal);
idhme (índice de desenvolvimento humano municipal educação);
idhml (índice de desenvolvimento humano municipal longevidade);
idhmr (índice de desenvolvimento humano municipal renda);
espvida (expectativa de vida);
rdpc (renda per capta);
gini (índice de gini);
pop (número de habitantes);
lat (coordenada de latitude do centróide do município);
lon (coordenada de longitude do centróide do município).
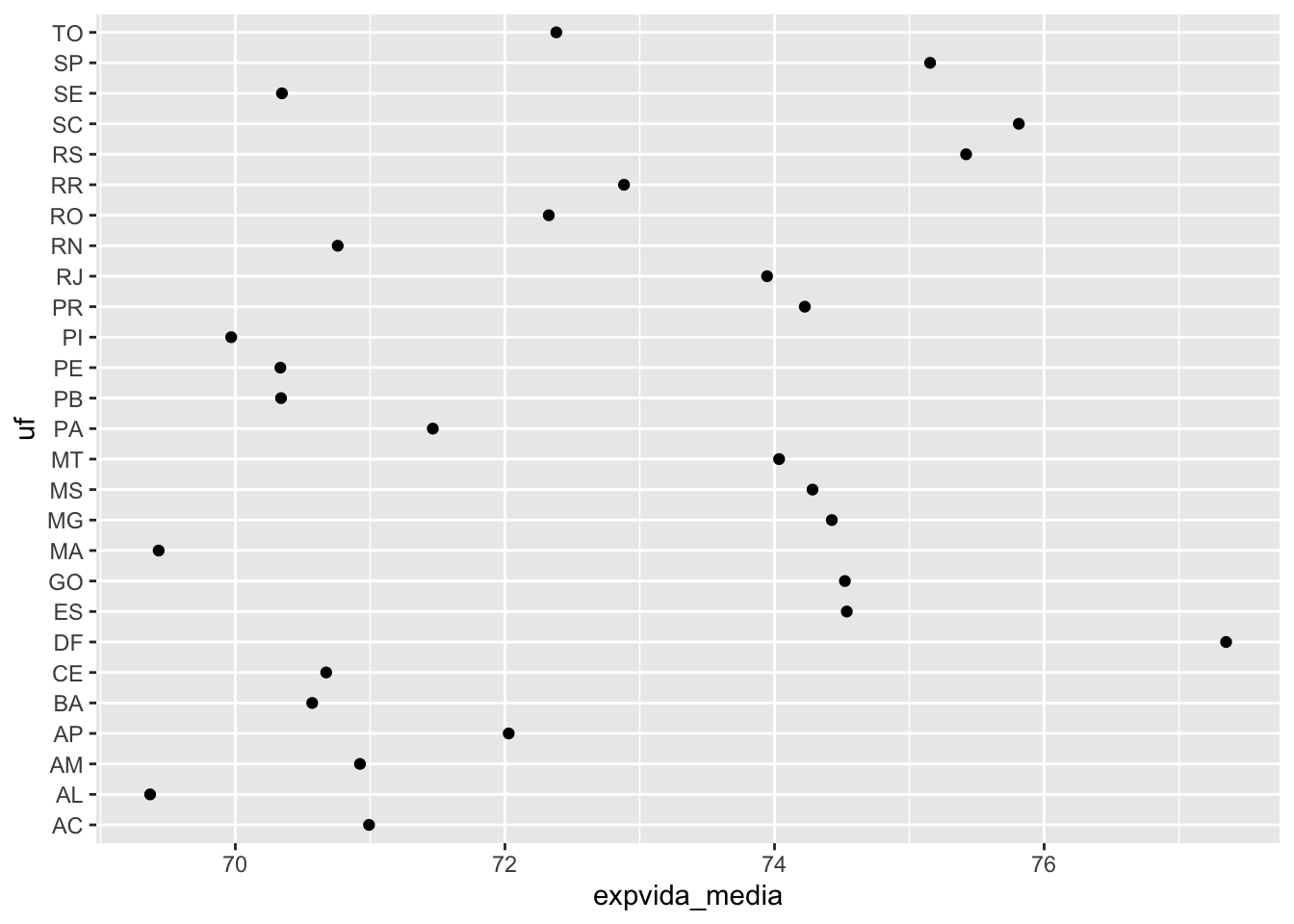
A seguir, vamos apresentar um gráfico de cleveland para a variável expectativa de vida média por UF no ano de 2010.
# selecionando os dados de 2010 e calculando a média da expectativa de vida por UFbase_UF <- base_PNUD |>filter(ano ==2010) |>group_by(uf) |>summarise(expvida_media =mean(expvida, na.rm =TRUE))# Gráfico de Cleveland básico para a expectativa de vida por UF no ano de 2010base_UF |>ggplot(mapping =aes(x= expvida_media, y = uf)) +geom_point()
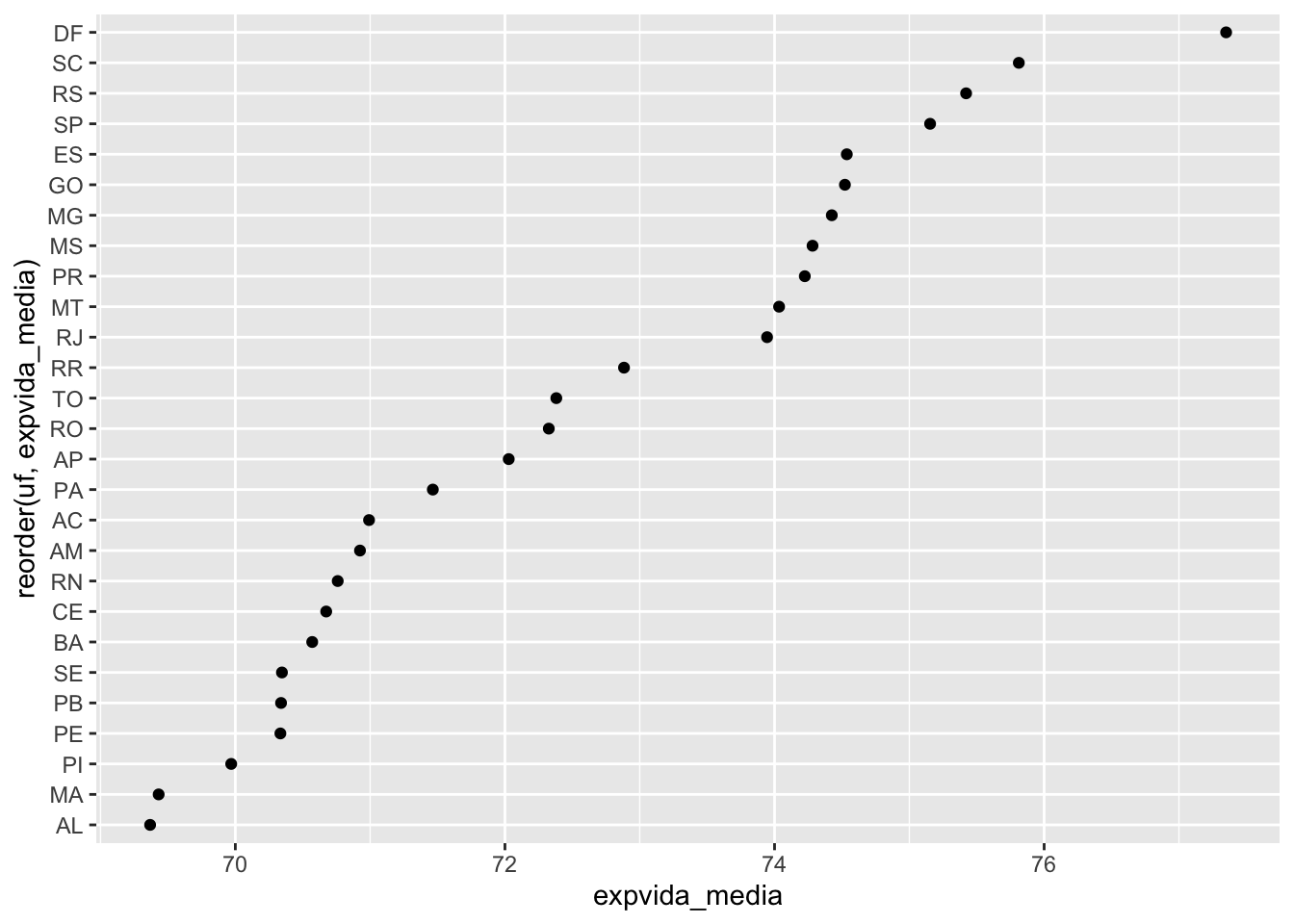
Para melhorarmos a visualização, podemos reordenar o eixo y em função dos valores da expectativa de vida média.
# reordenando o eixo ybase_UF |>ggplot(mapping =aes(x= expvida_media, y =reorder(uf, expvida_media))) +geom_point()
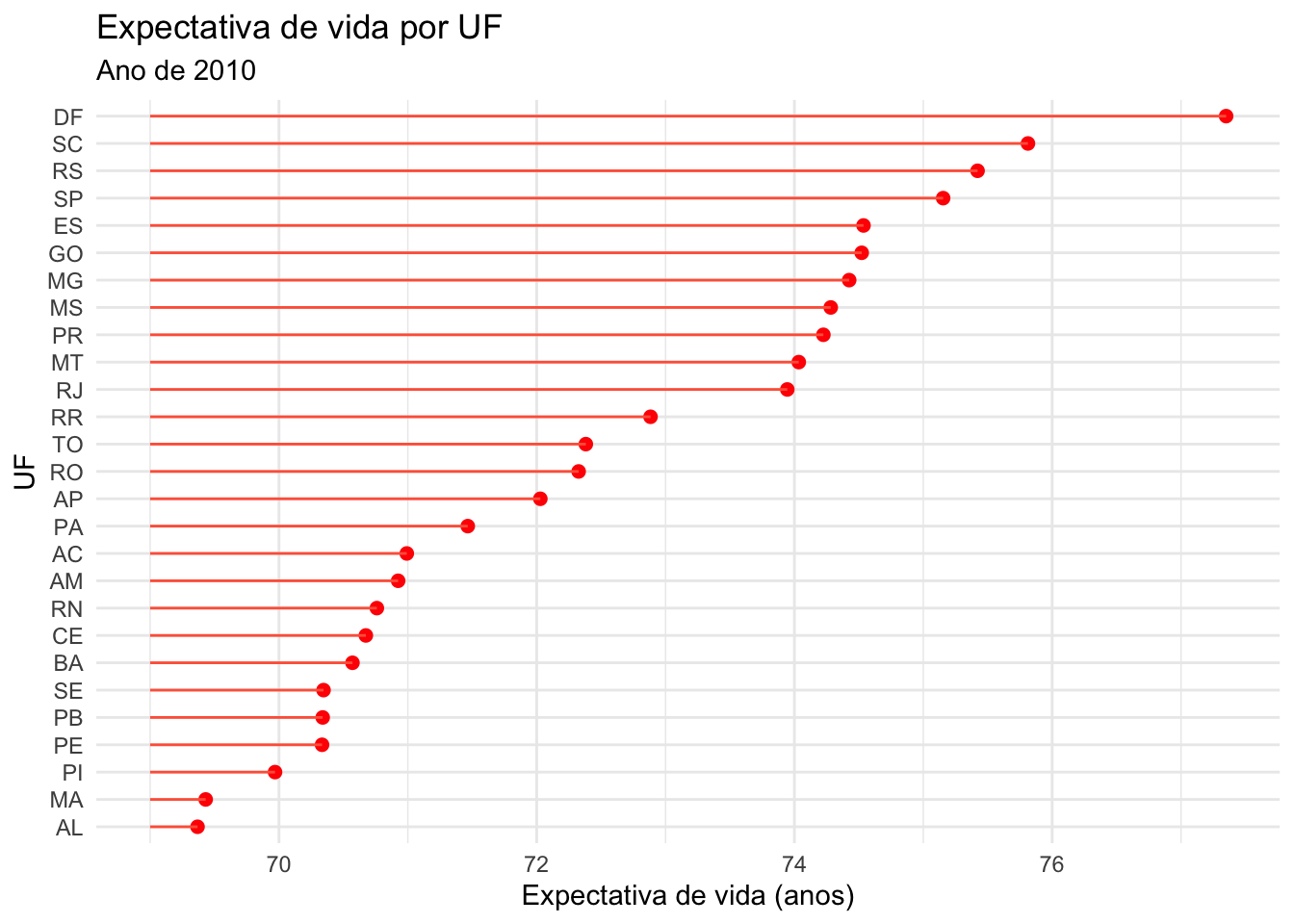
É possível melhorarmos a visualização. Iremos utilizar alguns recursos para tornar o gráfico mais atrativo.
# reordenando o eixo ybase_UF |>ggplot(mapping =aes(x= expvida_media, y =reorder(uf, expvida_media))) +geom_point(color="red", size =2) +geom_segment(aes(x =69, xend = expvida_media, y =reorder(uf, expvida_media), yend =reorder(uf, expvida_media)),color ="tomato1") +labs (x ="Expectativa de vida (anos)",y ="UF",title ="Expectativa de vida por UF",subtitle ="Ano de 2010") +theme_minimal()
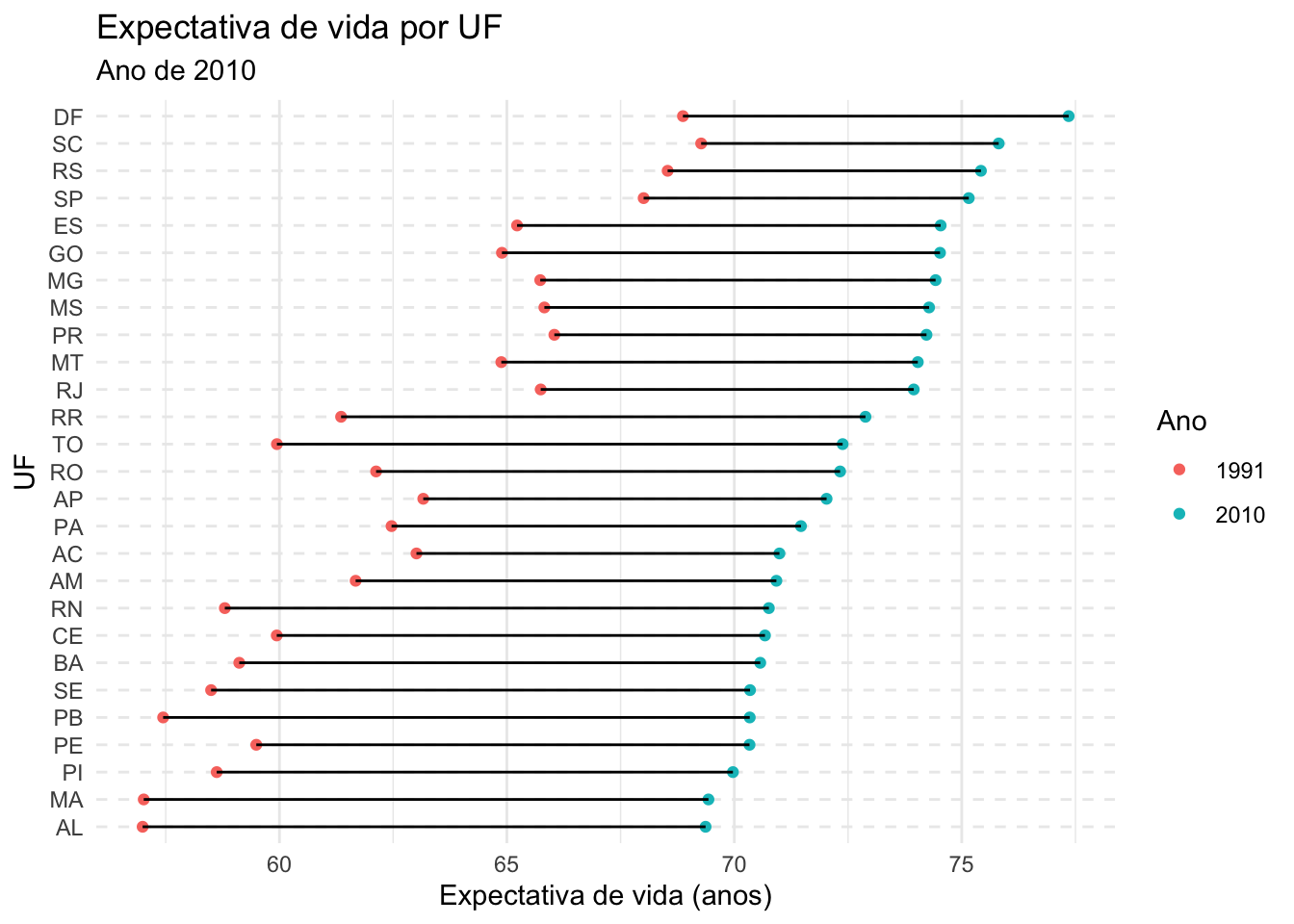
E se o nosso desejo fosse fazer uma comparação entre a expectativa de vida de 1991 com a de 2010?
5.3.8Gráfico de Dummbbell
Gráficos de Dummbbell são úteis para mostrar a mudança entre dois períodos de tempo para vários grupos de observações.
# subset dados de 1991 e 2010 e calculando a média por UF# para cada anobase_UF_91_10 <- base_PNUD |>filter(ano %in%c(1991,2010)) |>group_by(uf,ano) |>summarise(expvida_media =mean(expvida, na.rm =TRUE))
`summarise()` has grouped output by 'uf'. You can override using the `.groups`
argument.
# comparando expectativa de vida nos dois anosbase_UF_91_10 |>ggplot(mapping =aes(x= expvida_media, y =reorder(uf, expvida_media, max))) +geom_point(aes(color =factor(ano))) +geom_line(aes(group = uf)) +labs (x ="Expectativa de vida (anos)",y ="UF",color ="Ano",title ="Expectativa de vida por UF",subtitle ="Ano de 2010") +theme_minimal() +theme(panel.grid.major.y =element_line(linetype ="dashed"))
Atividade:Crie um gráfico semelhante ao anterior. Entretanto, o mesmo deve apresentar as diferenças entre o índice de gini de 1991 e 2010 e estar em ordem decrescente.