Uma série temporal pode ser vista como uma coleção de variáveis contínuas mensurada em intervalos regulares de tempo. A melhor representação visual para dados desse tipo são gráficos de linha, que são úteis para mostrar o comportamento de uma variável ao longo do tempo. A seguir, vamos considerar alguns gráficos que são úteis para representações de medidas ao longo do tempo.
8.1Gráfico de linhas
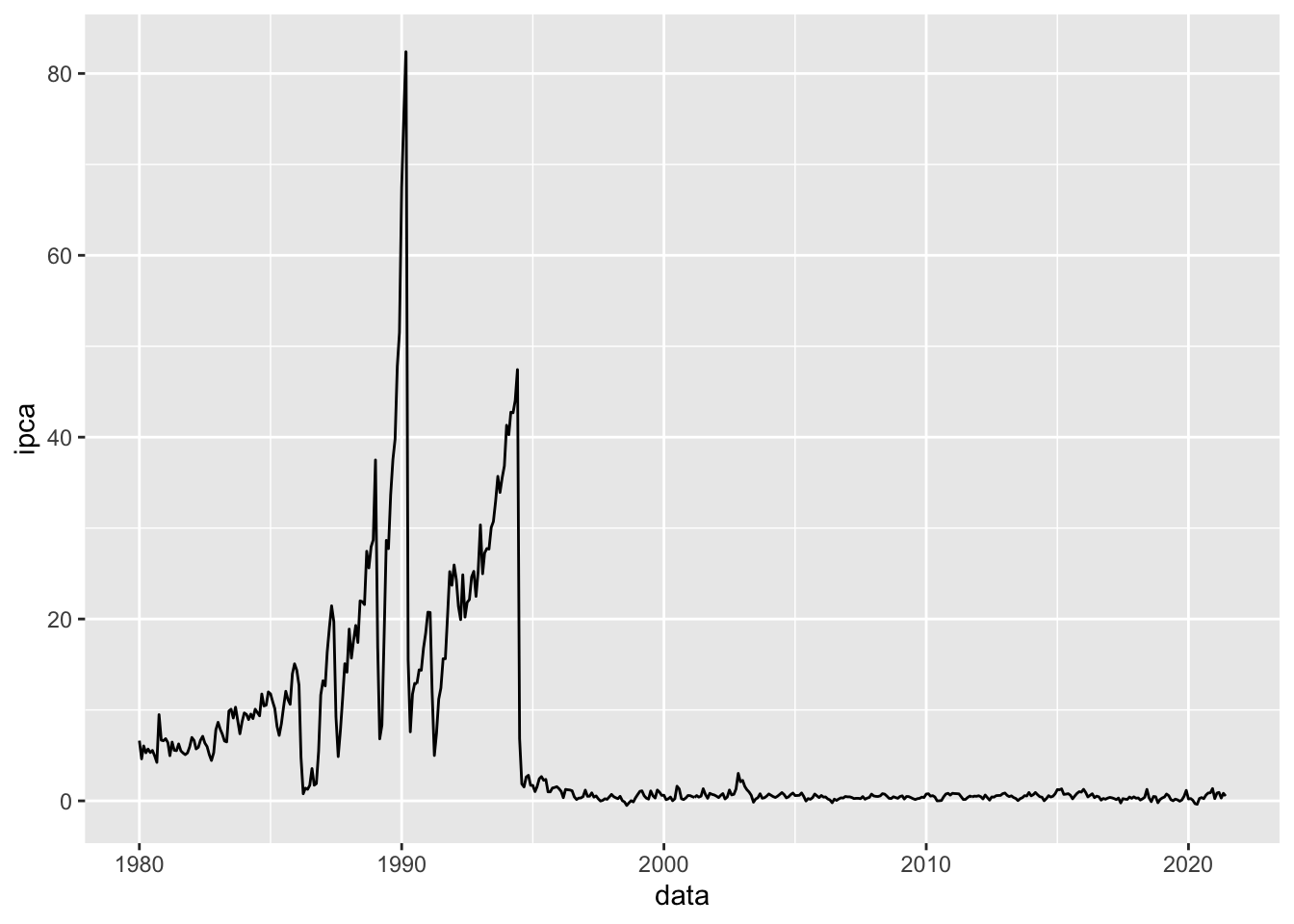
Como exemplo para gráficos de linha, vamos plotar a evolução de um importante indicador econômico brasileiro: o índice IPCA.
Atividade: Importe o arquivo base_SELIC_IPCA.csv e armazene-o em um objeto chamado base_BR.
A base de dados possui variáveis referentes a dois índices econômicos brasileiros:
data - data referente a mensuração do índice;
índice nacional de preços ao consumidor amplo (ipca);
taxa selic (selic).
# Visualizando o objetobase_BR
# A tibble: 498 × 3
data ipca selic
<chr> <dbl> <dbl>
1 01/01/1980 6.62 NA
2 01/02/1980 4.62 NA
3 01/03/1980 6.04 NA
4 01/04/1980 5.29 NA
5 01/05/1980 5.7 NA
6 01/06/1980 5.31 NA
7 01/07/1980 5.55 NA
8 01/08/1980 4.95 NA
9 01/09/1980 4.23 NA
10 01/10/1980 9.48 NA
# ℹ 488 more rows
Podemos perceber que o objeto acima está assumindo que a variável data não é uma variável com classe date, ou seja, uma data. Sendo assim, é preciso transformar essa variável com a ajuda do pacote lubridate.
# Carregando pacotelibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ purrr 1.0.2
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(lubridate)# Tratando a database_BR = base_BR |>mutate(data =dmy(data))# Visualizando o objetobase_BR
# A tibble: 498 × 3
data ipca selic
<date> <dbl> <dbl>
1 1980-01-01 6.62 NA
2 1980-02-01 4.62 NA
3 1980-03-01 6.04 NA
4 1980-04-01 5.29 NA
5 1980-05-01 5.7 NA
6 1980-06-01 5.31 NA
7 1980-07-01 5.55 NA
8 1980-08-01 4.95 NA
9 1980-09-01 4.23 NA
10 1980-10-01 9.48 NA
# ℹ 488 more rows
A função dmy foi usada, pois a variável estava organizada primeiro com o dia (day), depois mês (month) e por último o ano (year) - dmy. Existem diversas variações dessas funções que devem ser usadad de acordo com as ordenações de mês, dia e ano, por exemplo: ymd, ydm, myd, mdy e dym.
#Criando um gráfico de linhasbase_BR |>ggplot(mapping =aes(x = data, y = ipca)) +geom_line()
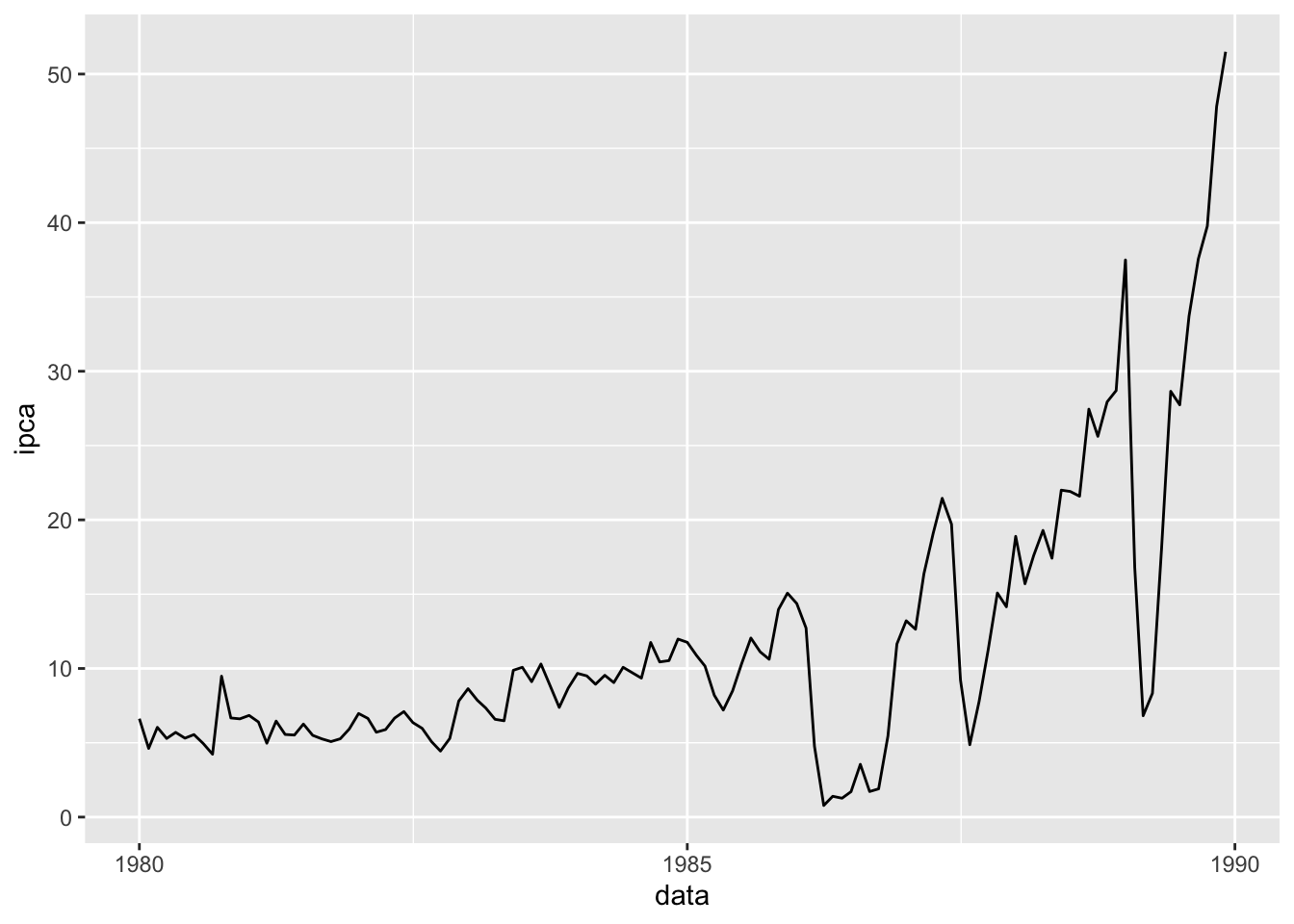
Suponha que gostaríamos de avaliar a série somente na década de 80.
#Criando um gráfico de linhas para um período específicobase_BR |>filter(data <dmy("01-01-1990")) |>ggplot(mapping =aes(x = data, y = ipca)) +geom_line()
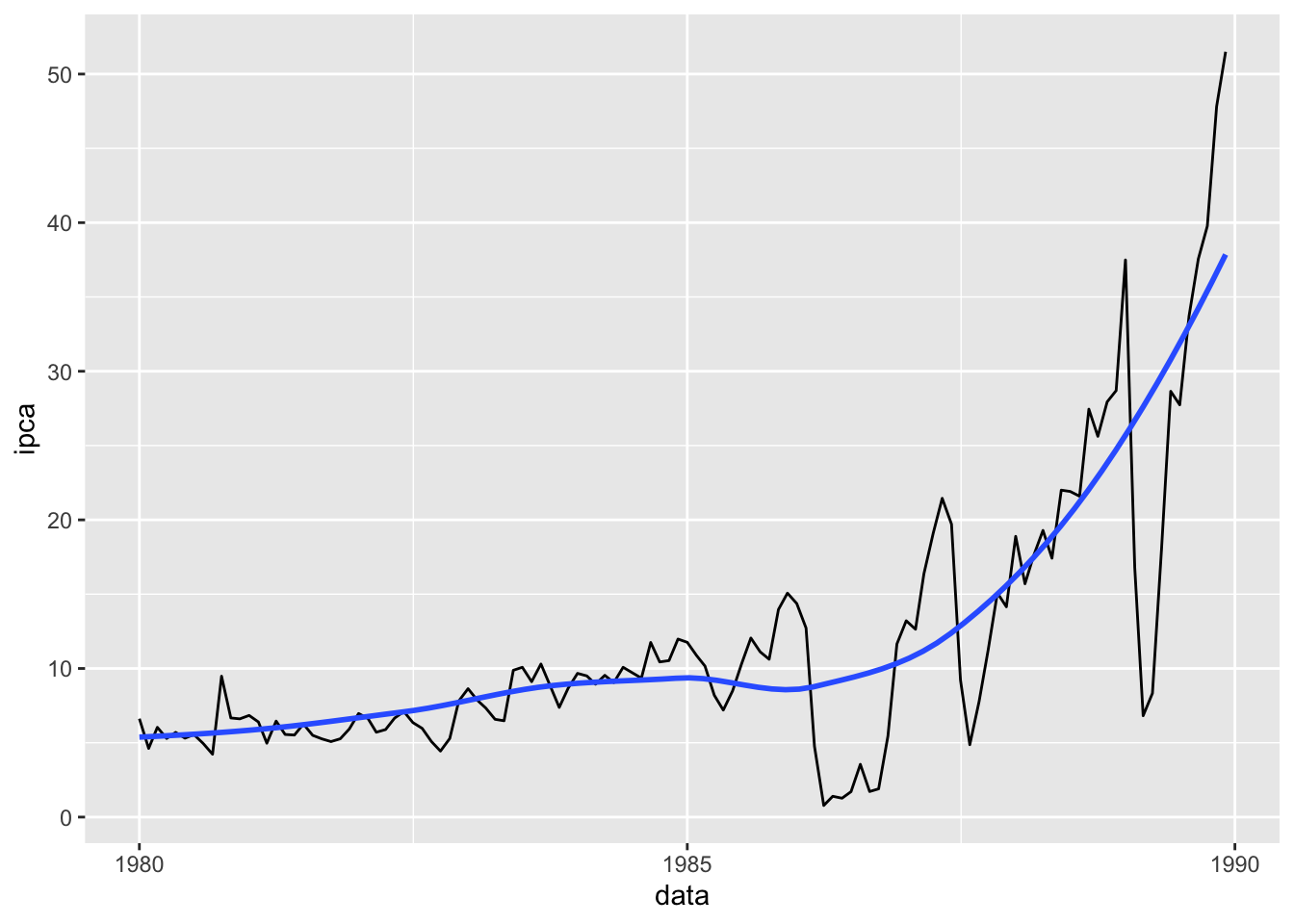
Se tivermos interessado em observar qual o comportamento da tendência desse série, podemos usar o geom_smooth com base no método loess.
#Criando um gráfico de linhas para um período específicobase_BR |>filter(data <dmy("01-01-1990")) |>ggplot(mapping =aes(x = data, y = ipca)) +geom_line() +geom_smooth(method ="loess",se =FALSE)
`geom_smooth()` using formula = 'y ~ x'
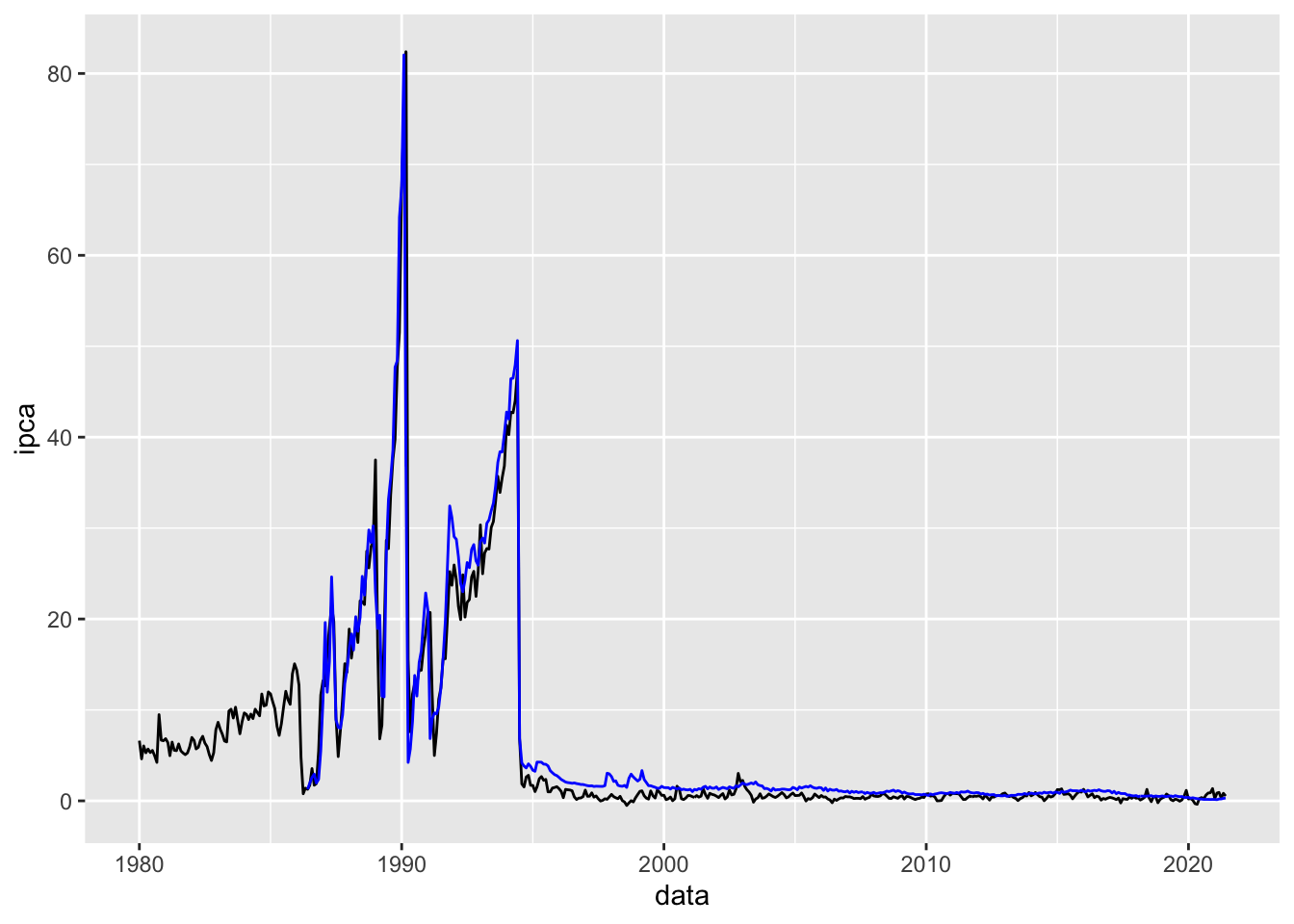
Suponha agora que o nosso interesse seja o de avaliar o comportamento das duas séries ao mesmo tempo? Naturalmente elas precisam estar numa mesma escala, idealmente no mesmo gráfico.
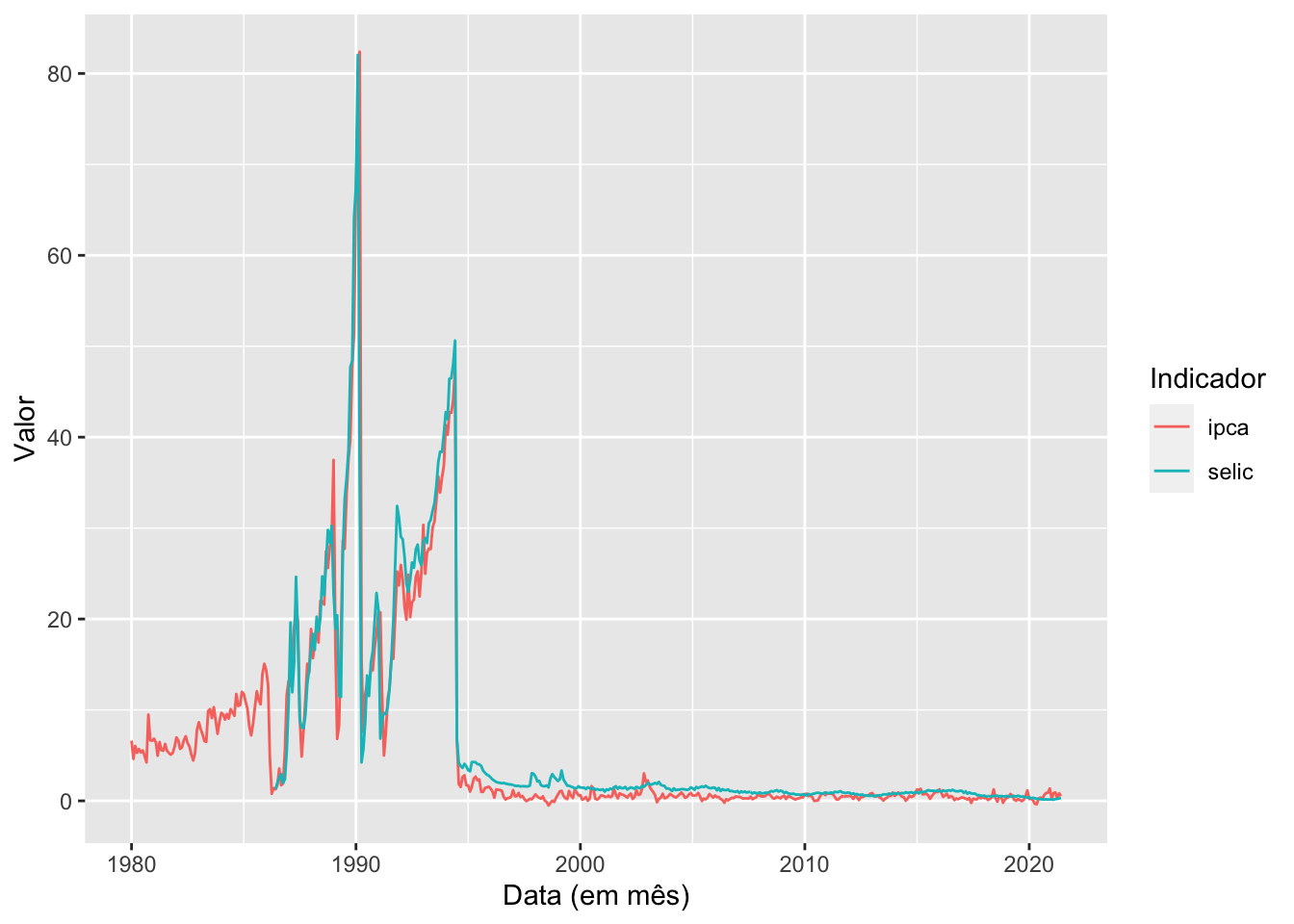
# Plotando duas séries no mesmo gráficobase_BR |>ggplot(mapping =aes(x = data, y = ipca)) +geom_line() +geom_line(aes(y = selic), color ="blue")
No gráfico acima conseguimos avaliar o comportamento das duas séries, mas ele não está completo, uma vez que não temos a indicação de quem é a série em azul e quem é a série em preto. Sendo assim, a melhor forma de fazer o gráfico é manipularmos a base com o gather.
# Plotando duas séries no mesmo gráficobase_BR |>gather(serie, valor, ipca:selic) %>%ggplot(aes(x = data, y = valor, color = serie)) +geom_line() +labs(x ="Data (em mês)",y ="Valor",color ="Indicador")
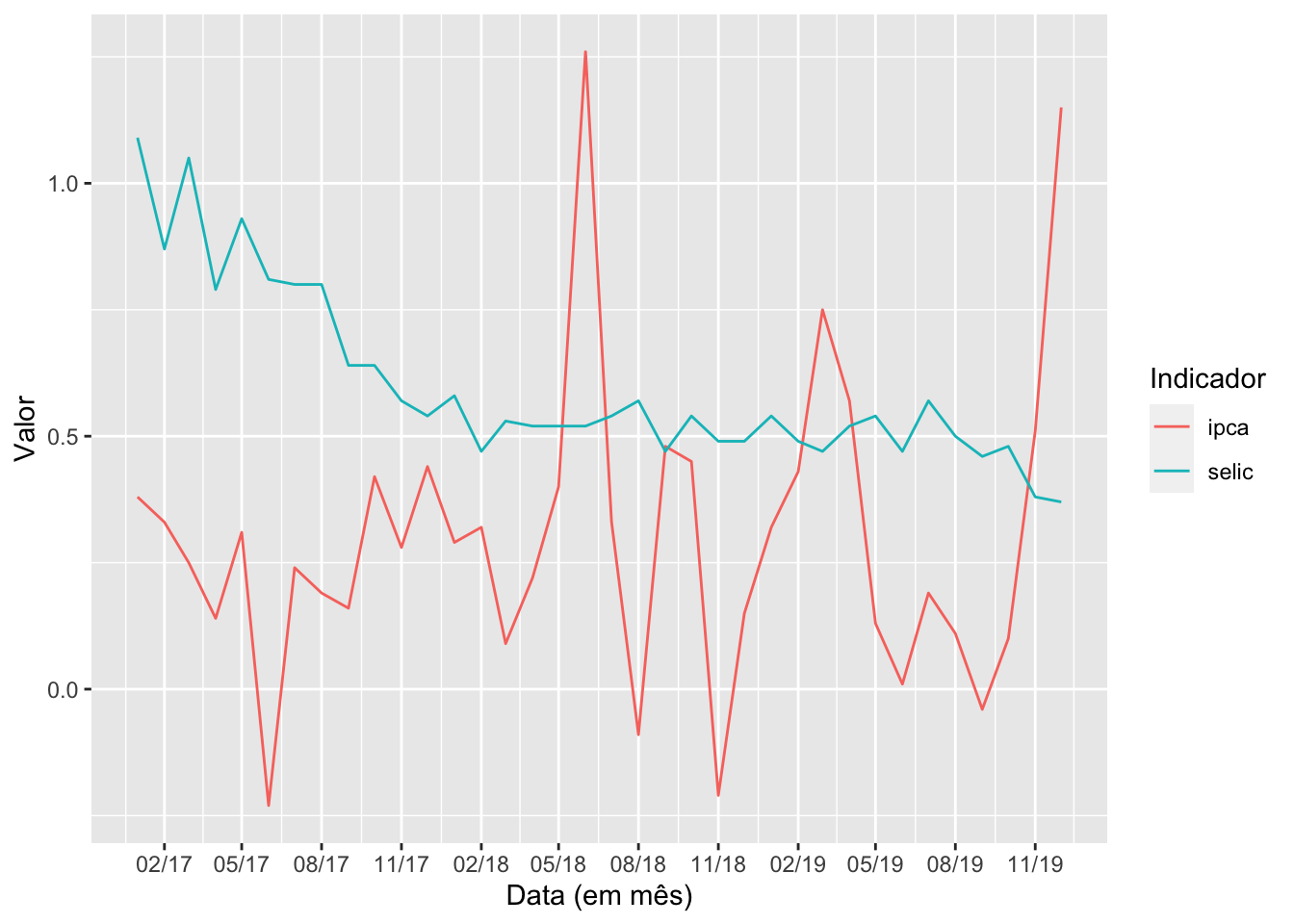
Vamos fazer a avaliação das duas séries nos anos de 2017 a 2019.
# Plotando duas séries no mesmo gráficobase_BR |>gather(serie, valor, ipca:selic) |>filter(data >dmy("31-12-2016"), data <dmy("01-01-2020")) |>ggplot(aes(x = data, y = valor, color = serie)) +geom_line() +scale_x_date(date_breaks ='3 month', labels = scales::date_format("%m/%y")) +labs(x ="Data (em mês)",y ="Valor",color ="Indicador")
No gráfico acima, o scale_x_date foi usado para tratar do eixo x. Vejam que foi indicado o intervalo de espaçamento para aparecer a data e o formato foi indicado como sendo mês/ano.
8.2Gráfico de Dummbbell
Gráficos de Dummbbell são úteis para mostrar a mudança entre dois períodos de tempo para vários grupos de observações.
Nós já criamos esse gráfico anteriormente, mas agora vamos mostrar como fazê-lo usando um geom apropriado, o geom_dumbbell.
Atividade: Importe o arquivo PNUD.csv e armazene-o em um objeto chamado base_PNUD
A base de dados possui duas variáveis:
ano;
muni (nome do município);
idhm (índice de desenvolvimento humano municipal);
idhme (índice de desenvolvimento humano municipal educação);
idhml (índice de desenvolvimento humano municipal longevidade);
idhmr (índice de desenvolvimento humano municipal renda);
espvida (expectativa de vida);
rdpc (renda per capta);
gini (índice de gini);
pop (número de habitantes);
lat (coordenada de latitude do centróide do município);
lon (coordenada de longitude do centróide do município).
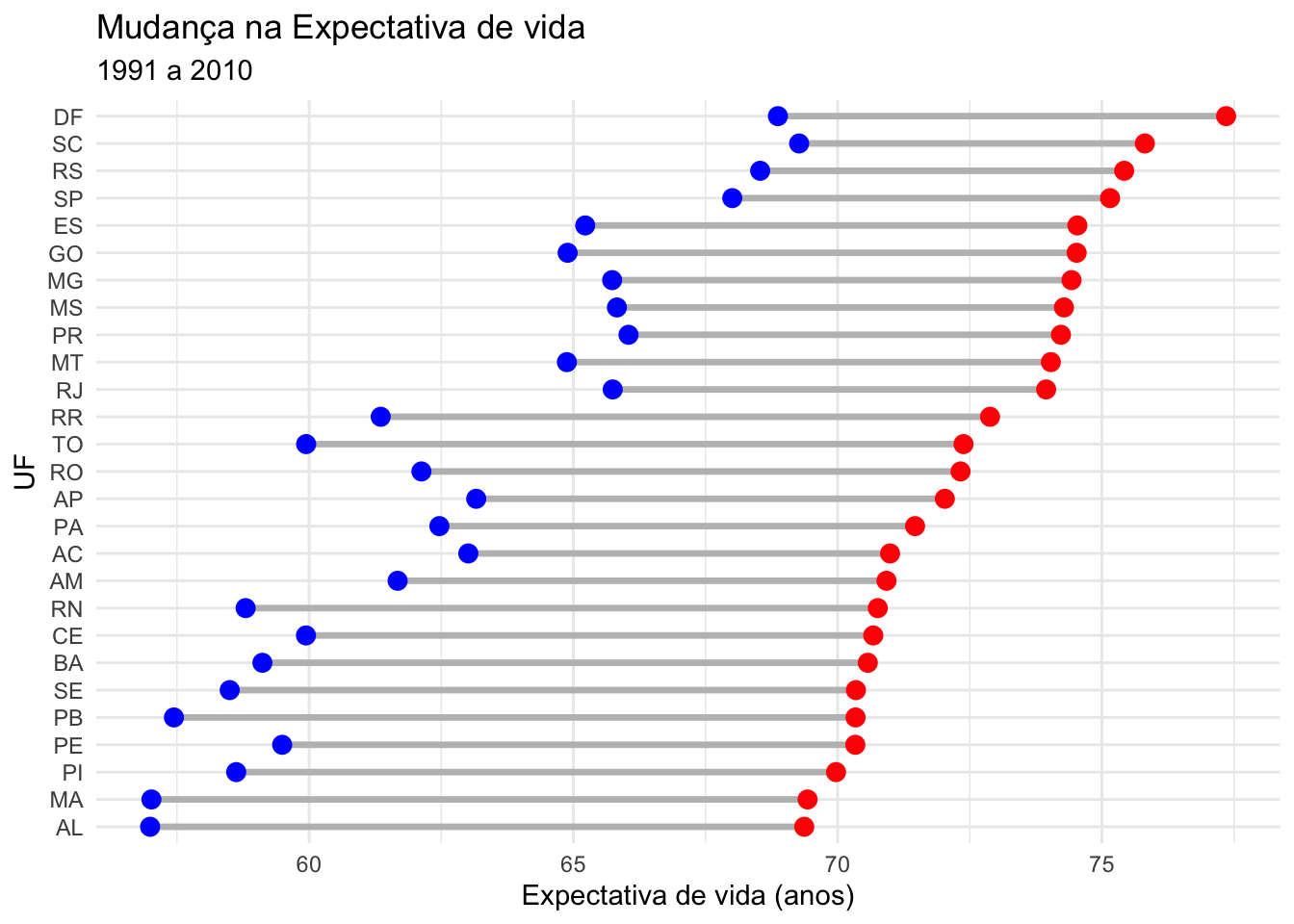
A seguir, vamos apresentar um gráfico de cleveland para a variável expectativa de vida média por UF no ano de 2010.
A seguir vamos criar uma base com medidas da expectativa de vida em 1991 e 2010, calculadas por UF.
# subset dados de 1991, 2000 e 2010 e calculando a média por UF# para cada anobase_UF <- base_PNUD |>group_by(uf,ano) |>summarise(expvida_media =mean(expvida, na.rm =TRUE))
`summarise()` has grouped output by 'uf'. You can override using the `.groups`
argument.
#Visualizando o objetobase_UF
# A tibble: 81 × 3
# Groups: uf [27]
uf ano expvida_media
<chr> <dbl> <dbl>
1 AC 1991 63.0
2 AC 2000 66.3
3 AC 2010 71.0
4 AL 1991 57.0
5 AL 2000 63.6
6 AL 2010 69.4
7 AM 1991 61.7
8 AM 2000 65.6
9 AM 2010 70.9
10 AP 1991 63.2
# ℹ 71 more rows
Para usarmos o geom_dumbbell precisamos que a base esteja espalhada, logo iremos usar o spread nela.
# Espalhando a basebase_UF_Spread = base_UF |>spread(key = ano,value = expvida_media) |>rename( "Ano_1991"=`1991`,"Ano_2000"=`2000`,"Ano_2010"=`2010`)#Visualizando o objetobase_UF_Spread
# A tibble: 27 × 4
# Groups: uf [27]
uf Ano_1991 Ano_2000 Ano_2010
<chr> <dbl> <dbl> <dbl>
1 AC 63.0 66.3 71.0
2 AL 57.0 63.6 69.4
3 AM 61.7 65.6 70.9
4 AP 63.2 67.2 72.0
5 BA 59.1 64.2 70.6
6 CE 59.9 66.2 70.7
7 DF 68.9 73.9 77.4
8 ES 65.2 69.9 74.5
9 GO 64.9 70.4 74.5
10 MA 57.0 62.2 69.4
# ℹ 17 more rows
# Carregando pacotelibrary(ggalt)
Registered S3 methods overwritten by 'ggalt':
method from
grid.draw.absoluteGrob ggplot2
grobHeight.absoluteGrob ggplot2
grobWidth.absoluteGrob ggplot2
grobX.absoluteGrob ggplot2
grobY.absoluteGrob ggplot2
# Criando um gráfico de dumbbellbase_UF_Spread |>ggplot(mapping =aes(y =reorder(uf, Ano_2010),x = Ano_1991,xend = Ano_2010)) +geom_dumbbell(size =1.2,size_x =3, size_xend =3,colour ="grey", colour_x ="blue", colour_xend ="red") +theme_minimal() +labs(title ="Mudança na Expectativa de vida",subtitle ="1991 a 2010",x ="Expectativa de vida (anos)",y ="UF")
Warning: Using the `size` aesthetic with geom_segment was deprecated in ggplot2 3.4.0.
ℹ Please use the `linewidth` aesthetic instead.
Vejam que a criação do gráfico é bastante simples. Basta informarmos no mapeamento da função ggplot qual a variável do eixo y e quais as variáveis que representam o ponto inicial e o ponto final no eixo x. Tudo que foi especificado no geom_dumbell foi para modificar a estética do gráfico.
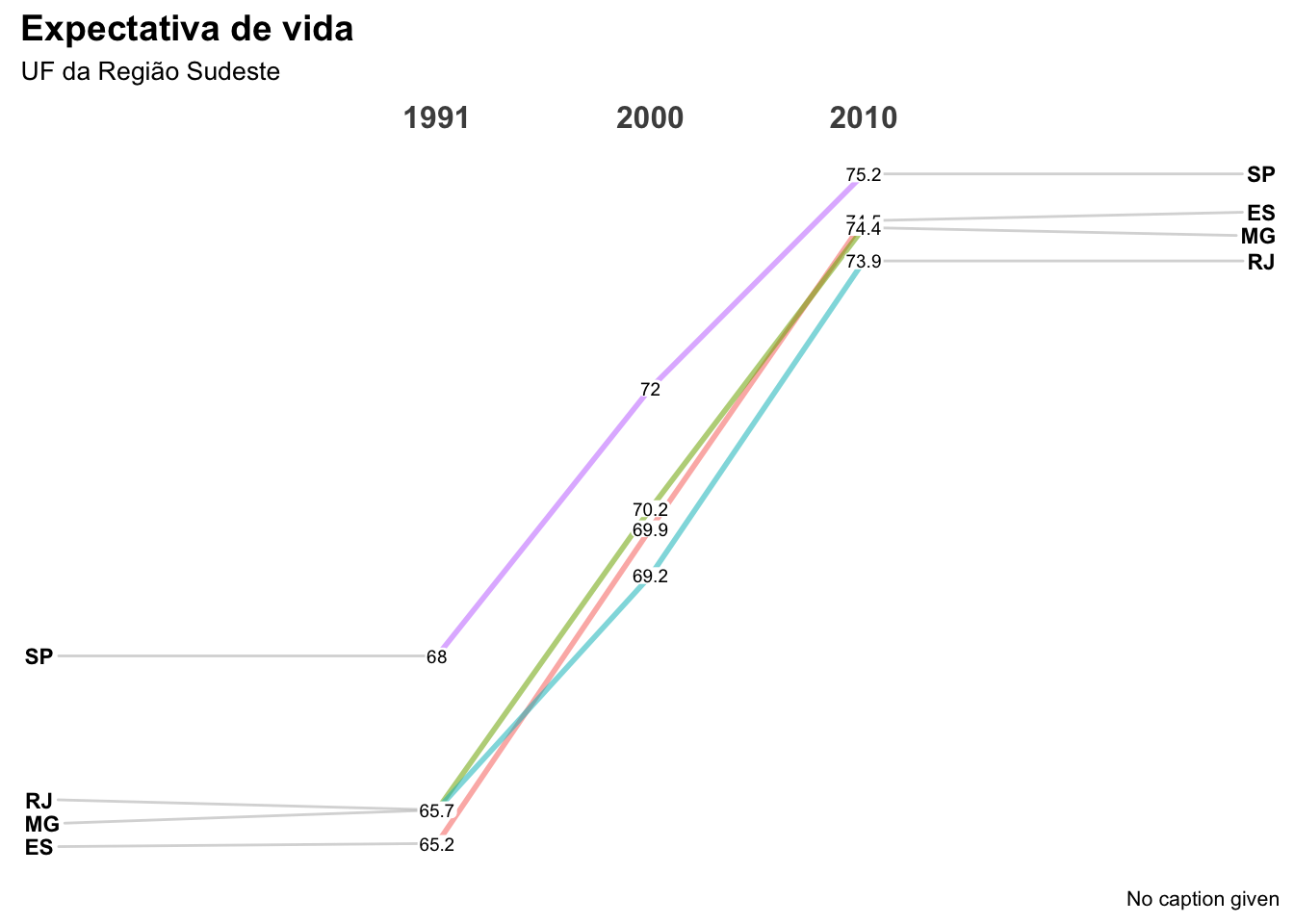
E se o interesse fosse em mostrar a evolução ao longo do tempo?
8.3Gráfico de inclinação
# os dados precisam estar organizados da seguinte formabase_UF = base_UF |>mutate(ano =factor(ano),expvida_media =round(expvida_media,1))# Carregando pacotelibrary(CGPfunctions)# Gráfico de inclinação para os estados da região sudestebase_UF |>filter(uf %in%c("RJ","SP","ES","MG")) |>newggslopegraph(Times = ano,Measurement = expvida_media,Grouping = uf) +labs(title ="Expectativa de vida", subtitle ="UF da Região Sudeste")
Converting 'ano' to an ordered factor
8.4Gráfico de área
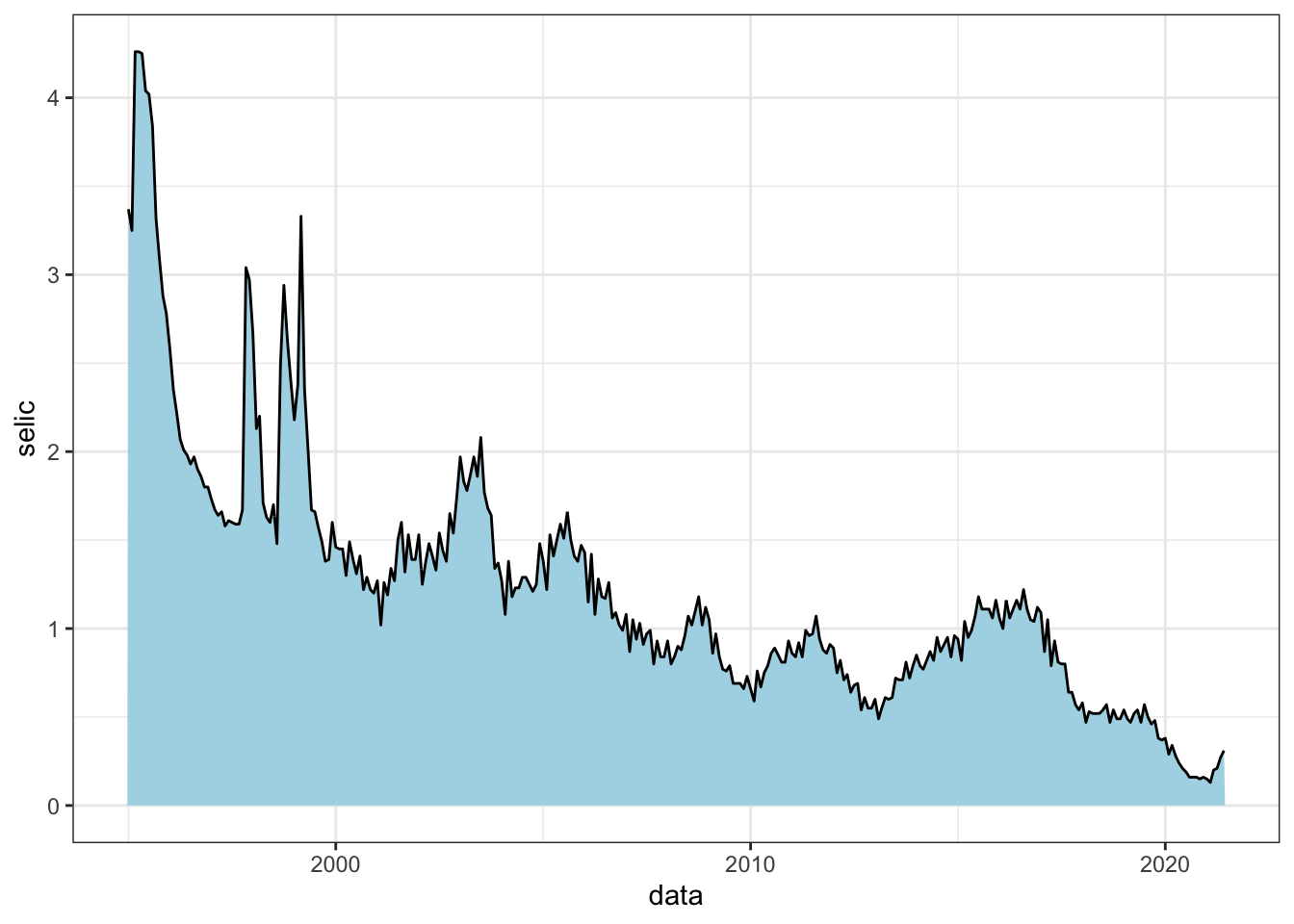
Em alguns contextos, é interessante apresentar o gráfico de linhas preenchido.
#Criando um gráfico de área para um período específicobase_BR |>filter(data >=dmy("01-01-1995")) |>ggplot(mapping =aes(x = data, y = selic)) +geom_area(fill="lightblue", color="black")
Em muitos casos, esses gráficos são usados para comparar diferentes grupos ao longo do tempo.
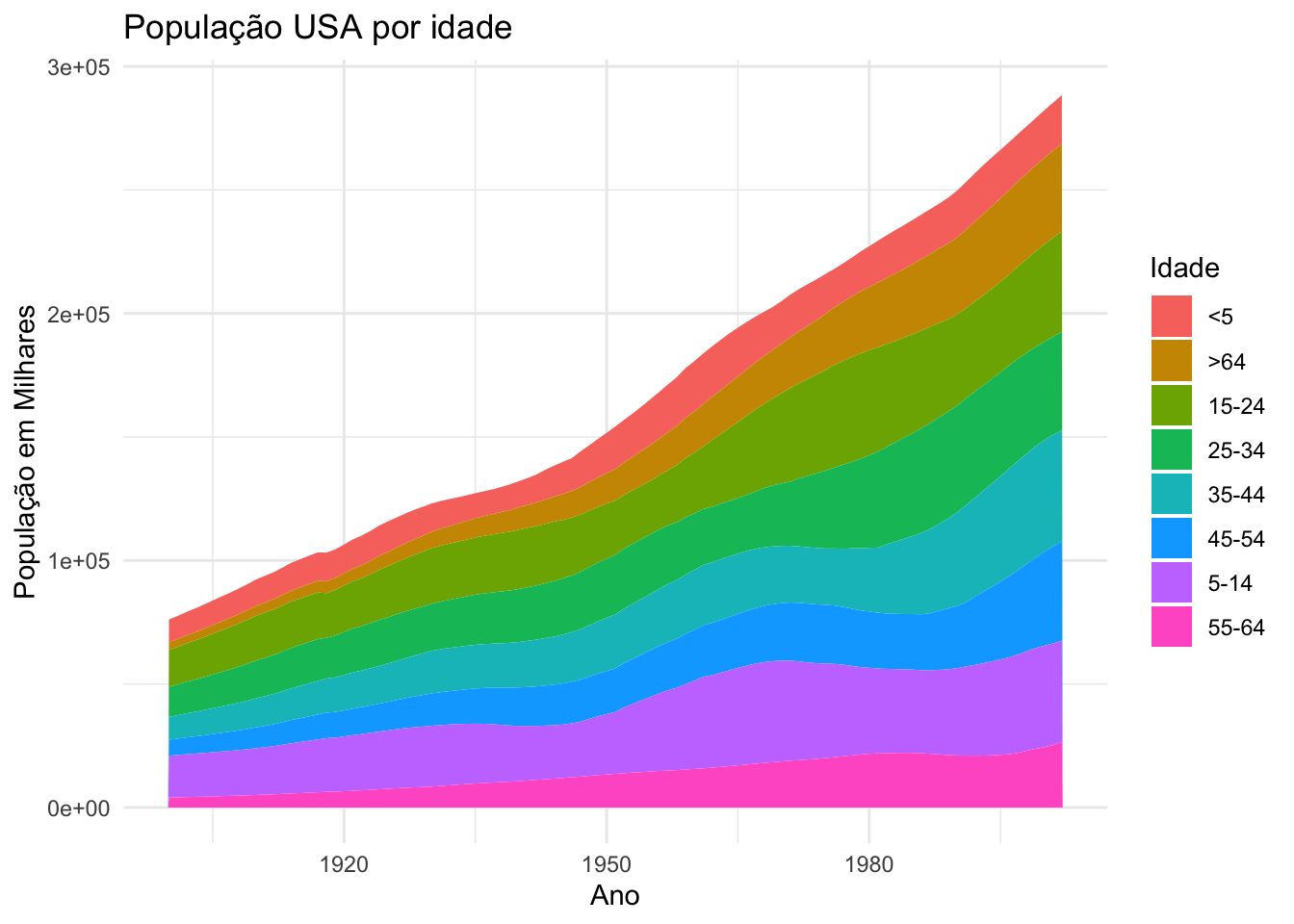
Atividade: Importe o arquivo base_populacao_americana.csv e armazene-o em um objeto chamado base_pop_USA.
A base de dados possui variáveis referentes a evolução do quantitativo da população americana por grupos de faixa etária:
#Criando gráfico de área por grupos de faixas etáriasbase_pop_USA |>ggplot(mapping =aes(x = Ano,y = Pop_milhares, fill = Idade)) +geom_area() +labs(title ="População USA por idade",x ="Ano",y ="População em Milhares") +theme_minimal()
Atividade: O gráfico acima tem um problema. Qual o problema do gráfico acima? Corrija o problema! Além disso, tente modificar a escala do eixo y para que a mesma não apareça em notação científica.
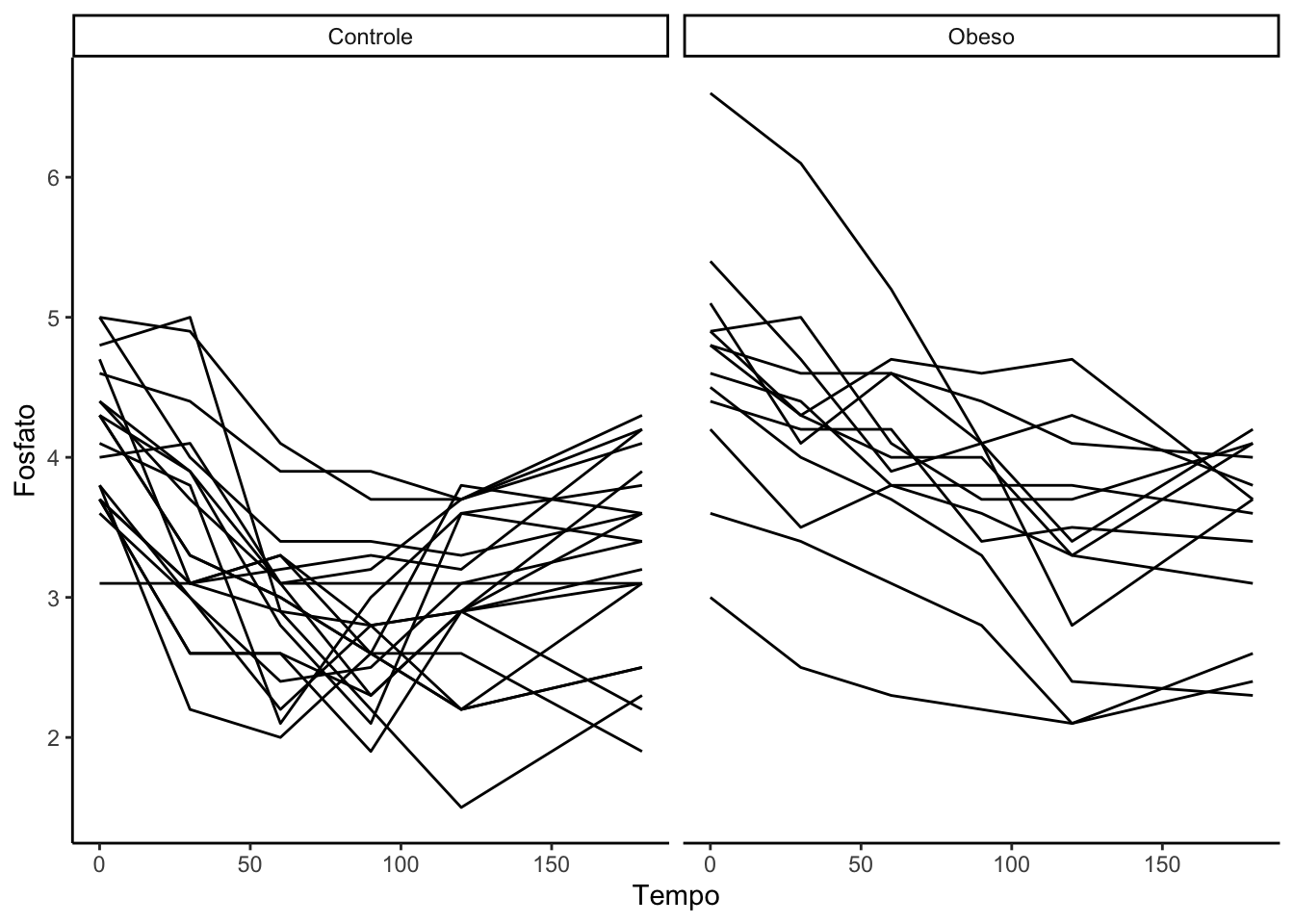
8.5Spaghetti plot
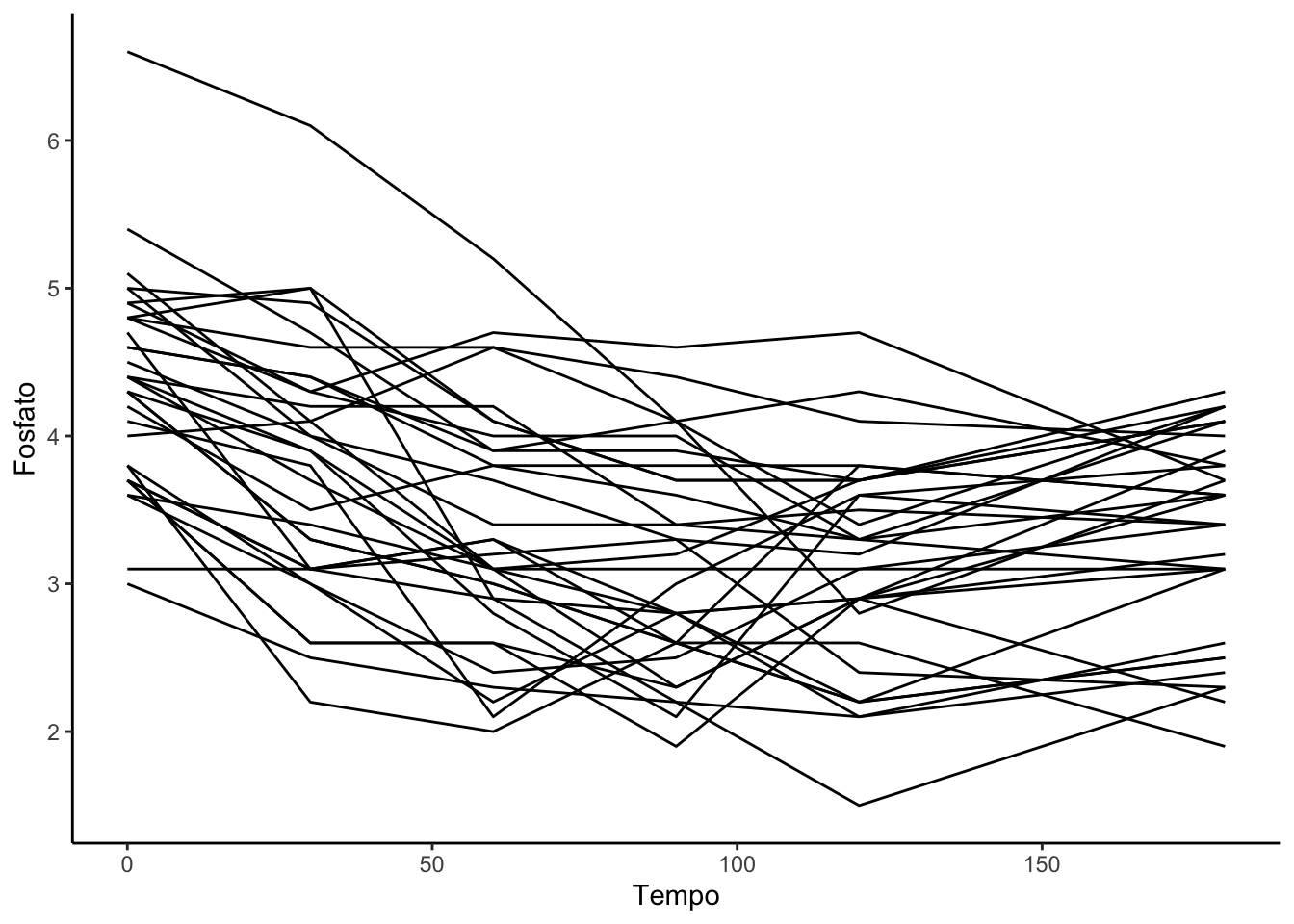
Um “spaghetti plot” é uma representação gráfica usada em estatísticas e visualização de dados para exibir múltiplas trajetórias ou séries temporais em um único gráfico. O nome “spaghetti plot” deriva da semelhança visual das linhas entrelaçadas no gráfico, que se assemelham a um monte de espaguete.
Os spaghetti plots são frequentemente usados quando se deseja comparar várias séries de dados ao longo do tempo ou em uma dimensão contínua. Eles são úteis para identificar tendências, padrões, variações e discrepâncias nas diferentes séries, especialmente quando se trata de dados longitudinais, como séries temporais climáticas, financeiras ou médicas.
No entanto, a complexidade de um spaghetti plot pode tornar a interpretação desafiadora quando há muitas séries representadas. Para tornar a leitura mais clara, é comum usar cores diferentes, etiquetas ou legendas para identificar cada série. Além disso, em alguns casos, pode ser útil suavizar as linhas para destacar tendências gerais.
Em resumo, o spaghetti plot é uma ferramenta visual que permite a comparação e análise de múltiplas séries de dados ao longo do tempo ou em uma dimensão contínua, mas deve ser usado com cuidado para garantir que as informações sejam comunicadas de forma clara e eficaz.
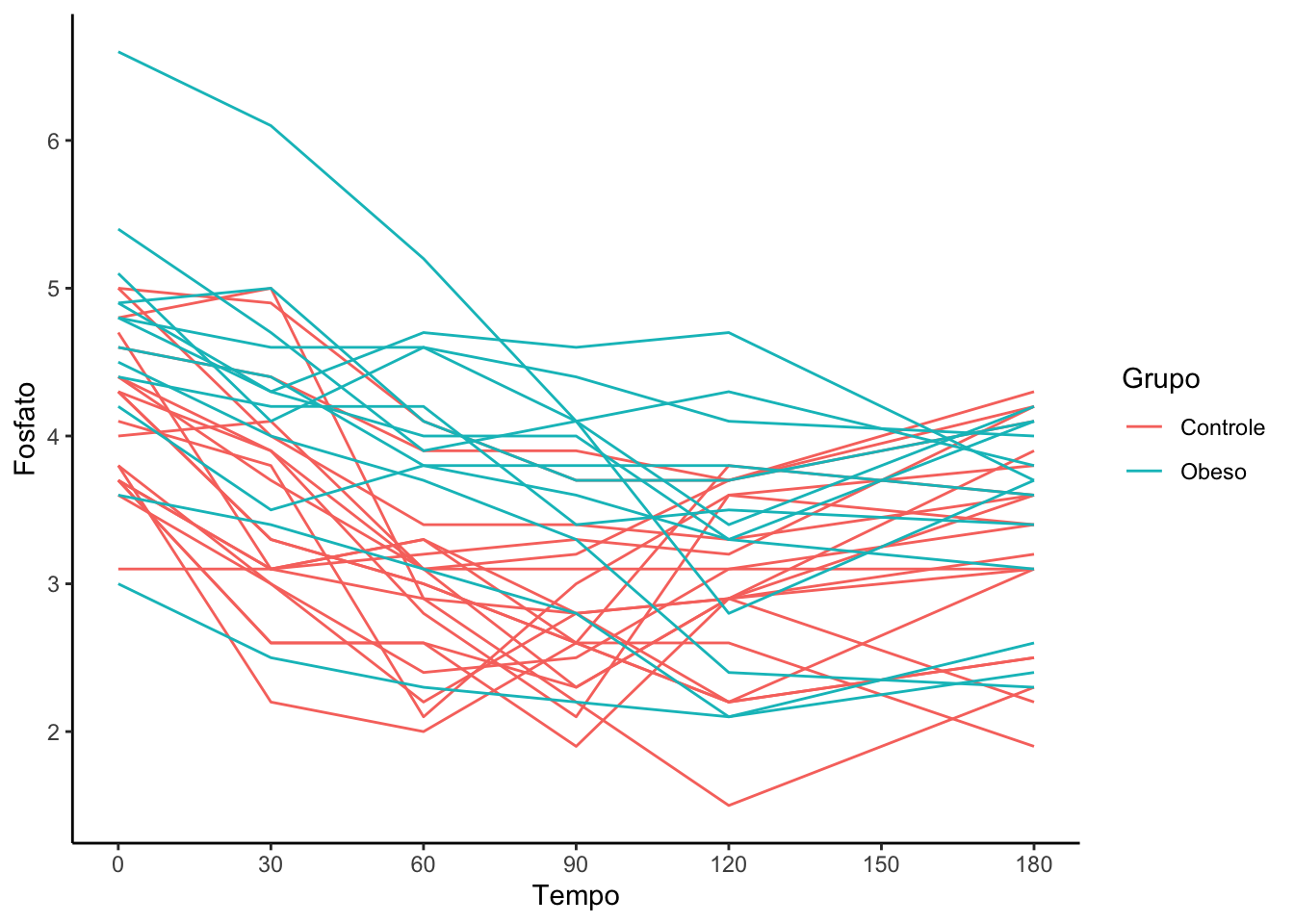
Atividade: Importe o arquivo fosfato.dta.
A base de dados possui variáveis referentes a evolução da quantidade de fostato em indivíduos dos grupos controle e obeso em seis períodos de tempo: 0, 30, 60, 90, 120 e 150. quantitativo da população americana por grupos de faixa etária:
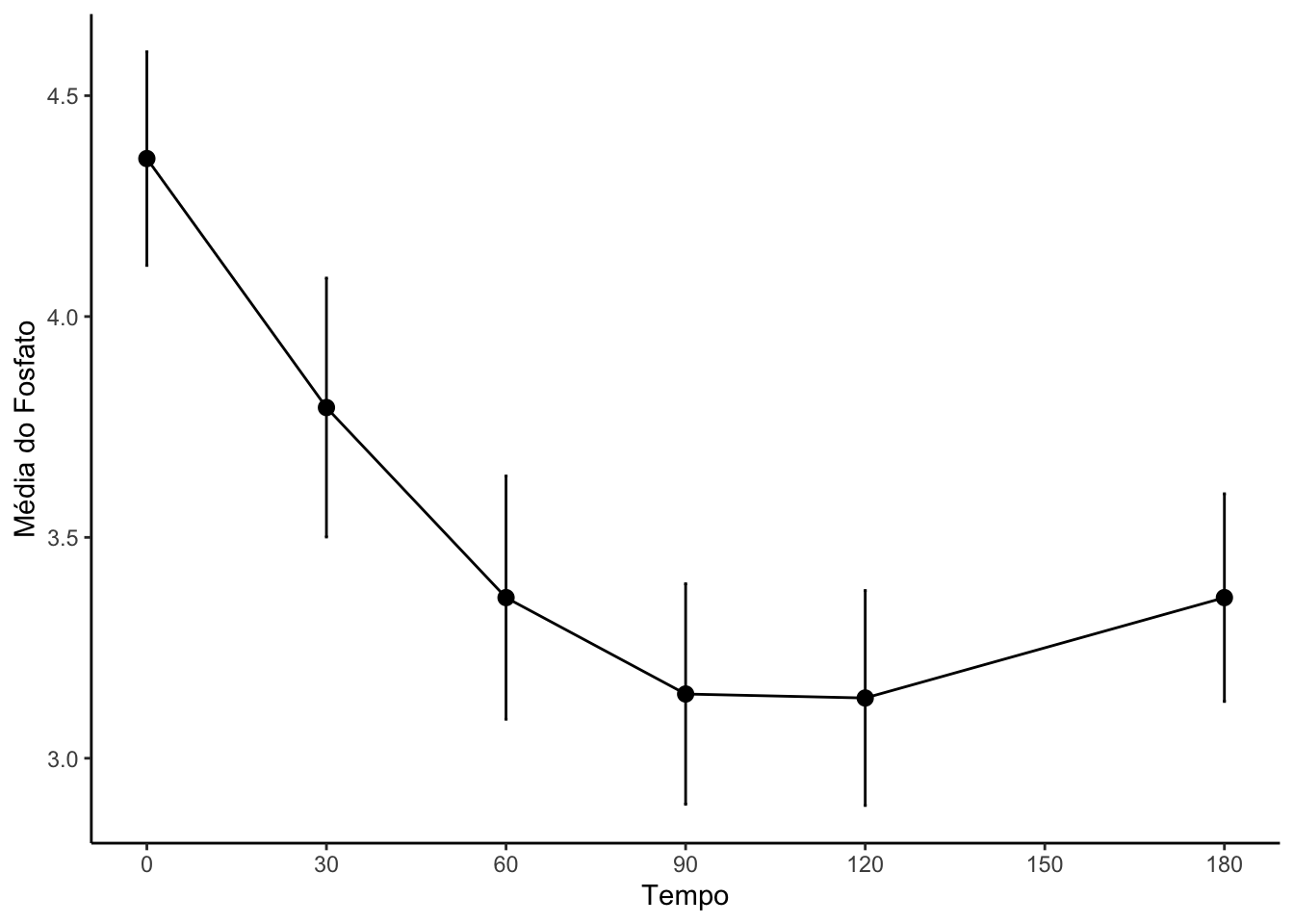
#Criando uma variável tempo numérica no objeto resumoGeralresumoGeral = resumoGeral |>mutate(tempo_num =c(0,30,60,90,120,180))#Gráfico com os perfis de médias por tempoperfil_media =ggplot(data = resumoGeral, mapping =aes(x = tempo_num, y = media)) +geom_line() +geom_point(size =2.5) +labs(x ="Tempo", y ="Média do Fosfato") +geom_errorbar(mapping =aes(ymin = IC_LI, ymax = IC_LS), width =0.5) +scale_x_continuous(breaks =seq(0,180,30)) +theme_classic()perfil_media
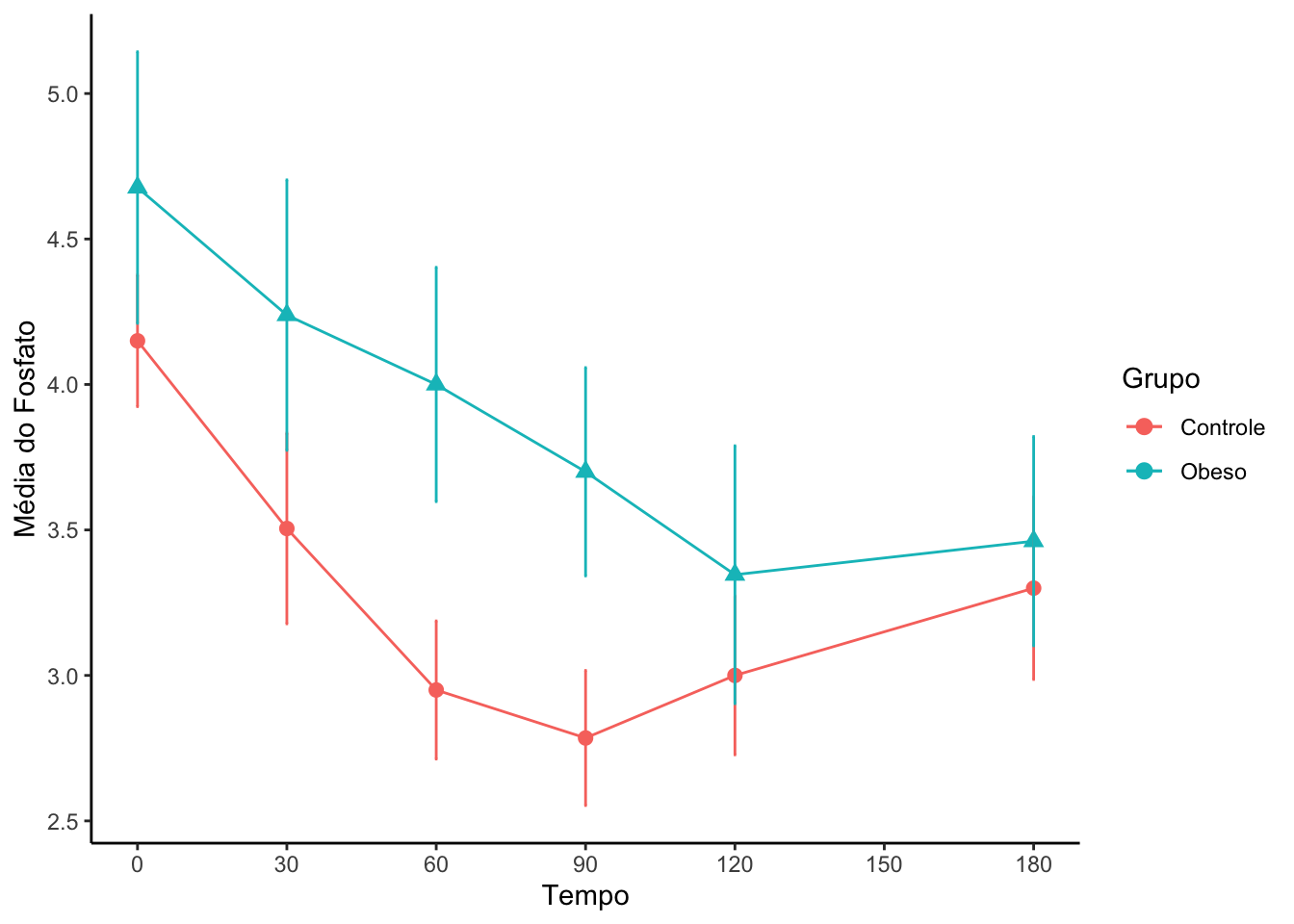
Também é possível criar os perfis médios por grupo.
#Descrevendo os padrões longitudinais por gruposresumoGrupo = base_empilhada |>group_by(grupo,Tempo) |>summarise(n_obs =n(),media =mean(Fosfato, na.rm =TRUE),d_p =sd(Fosfato, na.rm =TRUE),minimo =min(Fosfato, na.rm =TRUE),maximo =max(Fosfato, na.rm =TRUE),erro_padrao = d_p/sqrt(n_obs),IC_LI = media -1.96*erro_padrao,IC_LS = media +1.96*erro_padrao) |>ungroup()
`summarise()` has grouped output by 'grupo'. You can override using the
`.groups` argument.
#Criando uma variável tempo numérica no objeto resumoGruporesumoGrupo = resumoGrupo |>mutate(tempo_num =c(c(0,30,60,90,120,180),c(0,30,60,90,120,180)))#Gráfico com os perfis de médias por tempo e por grupoperfil_media_grupo =ggplot(data = resumoGrupo, mapping =aes(x = tempo_num, y = media,color = grupo,shape = grupo)) +geom_line() +geom_point(size =2.5) +labs(x ="Tempo", y ="Média do Fosfato",color ="Grupo") +geom_errorbar(mapping =aes(ymin = IC_LI, ymax = IC_LS), width =0.5) +scale_x_continuous(breaks =seq(0,180,30)) +guides(shape =FALSE) +theme_classic()
Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.
perfil_media_grupo
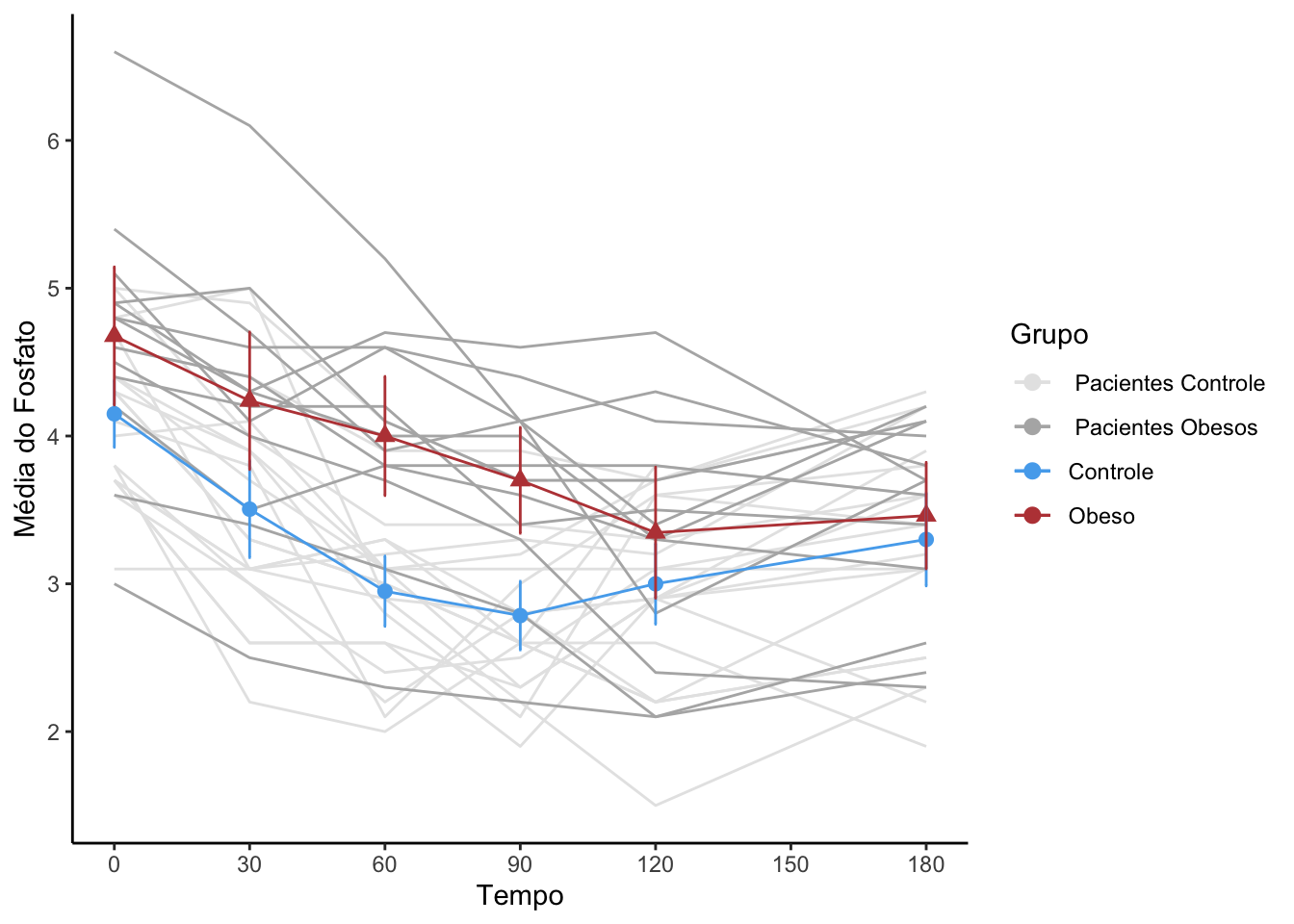
E ainda colocar os perfis médios sobre o spaghetti plot.
#Gráfico com os perfis de médias por tempo e por grupo com o spaghettiperfil_media_grupo_spag =ggplot(data = resumoGrupo, mapping =aes(x = tempo_num, y = media,color = grupo,shape = grupo)) +geom_line(data = base_empilhada |>filter(grupo =="Controle"),mapping =aes(x = Tempo_num, y = Fosfato, group = id, color=" Pacientes Controle")) +geom_line(data = base_empilhada |>filter(grupo =="Obeso"),mapping =aes(x = Tempo_num, y = Fosfato, group = id, color=" Pacientes Obesos")) +geom_line() +geom_point(size =2.5) +labs(x ="Tempo", y ="Média do Fosfato",color ="Grupo") +geom_errorbar(mapping =aes(ymin = IC_LI, ymax = IC_LS), width =0.5) +scale_x_continuous(breaks =seq(0,180,30)) +scale_color_manual(values =c("grey90", "grey70", "#55acee", "#bb4444")) +guides(shape=FALSE) +theme_classic()perfil_media_grupo_spag