A escolha da “melhor” visualização de dados depende do público alvo e do objetivo desejado. Naturalmente, existem alguns pontos que são chaves para a escolha da melhor visualização, um deles é o tipo da variável, isto é, existem gráficos apropriados para variáveis qualitativas (sexo, faixa etária, estado cívil, etc) e quantitativas (idade, peso, índice de massa corporal, etc).
A seguir, iremos discutir alguns gráficos básicos para se fazer análises univariadas. Estas análises visam em geral apresentar a distribuição dos dados.
A seguir serão apresentados os principais gráficos para visualizar a distribuição de uma única variável qualitativa. Discutiremos como manipular os argumentos das funções no ggplot para melhorar/modificar os gráficos.
4.1 Gráficos para variáveis qualitativas
Atividade:Crie um projeto chamado Analise survey. Após abra o Script Cap4. Use o espaço em branco no início do script para importar o arquivo survey85.csv e armazene-o em um objeto chamado survey.
A base de dados possui variáveis referentes a uma pesquisa survey realizada em 1985 contendo remuneração e outras características de trabalhadores, tais como:
salário por hora em dólares (remuneracao);
número de anos de educação (educacao);
sexo;
é hispânico? (hispanico);
é do sul? (sul);
é casado? (casado);
tempo de experiência de trabalho (exper);
idade;
setor de trabalho (setor).
#Visualizando o objetosurvey
# A tibble: 533 × 10
remuneracao educacao raca sexo hispanico sul casado exper idade setor
<dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 8.44 12 Branco F N N N 4 22 vend…
2 5.72 12 Branco F N N S 29 47 admi…
3 2.93 16 Branco F N N S 27 49 admi…
4 8.34 12 Branco F N N S 5 23 serv…
5 5.21 12 Branco F N N S 14 32 vend…
6 9.07 17 Não Bran… F N N S 32 55 admi…
7 3.92 14 Branco F N N N 15 35 admi…
8 4.27 12 Branco F N N S 38 56 serv…
9 5.55 12 Branco F N N N 7 25 serv…
10 5.28 17 Branco F N N N 5 28 prof
# ℹ 523 more rows
Atividade:Crie uma variável chamada remun_cat, que assume Muito Baixa, Baixa, Satisfatória e Alta se a remuneração pertence ao interval0 (0,4], (4, 8], (8, 15] e [15, 100), respectivamente.
Após criarmos a variável a base ficará da seguinte forma:
#Visualizando o objetosurvey
# A tibble: 533 × 11
remuneracao educacao raca sexo hispanico sul casado exper idade setor
<dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 8.44 12 Branco F N N N 4 22 vend…
2 5.72 12 Branco F N N S 29 47 admi…
3 2.93 16 Branco F N N S 27 49 admi…
4 8.34 12 Branco F N N S 5 23 serv…
5 5.21 12 Branco F N N S 14 32 vend…
6 9.07 17 Não Bran… F N N S 32 55 admi…
7 3.92 14 Branco F N N N 15 35 admi…
8 4.27 12 Branco F N N S 38 56 serv…
9 5.55 12 Branco F N N N 7 25 serv…
10 5.28 17 Branco F N N N 5 28 prof
# ℹ 523 more rows
# ℹ 1 more variable: remun_cat <fct>
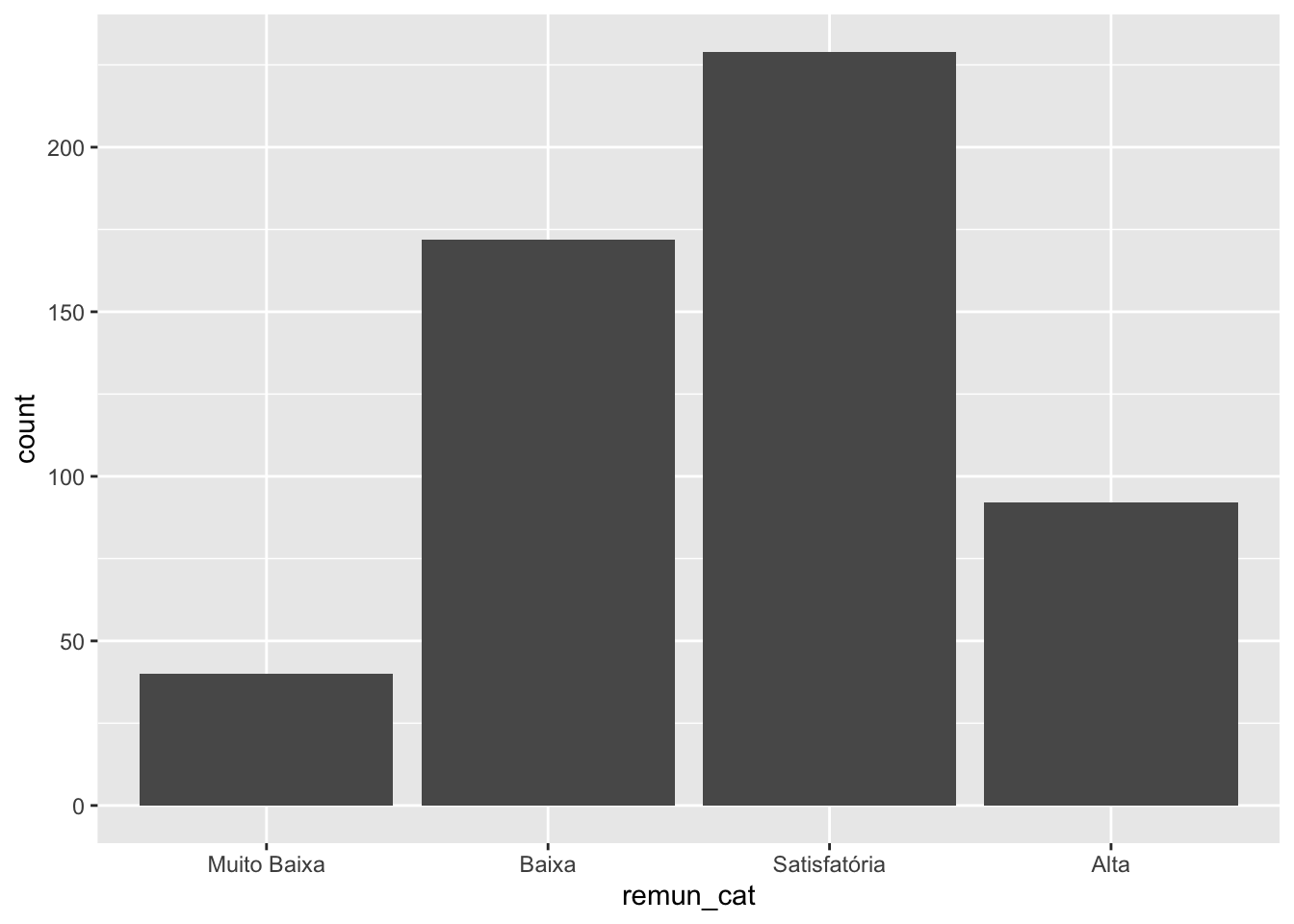
4.1.1Gráfico de barras
O gráfico de barras/colunas são utilizados para fazer comparações entre as categorias da variável qualitativa. Trata-se de um gráfico de simples interpretação.
A seguir apresentamos como construir um gráfico de barras para a variável remuneração categorizada.
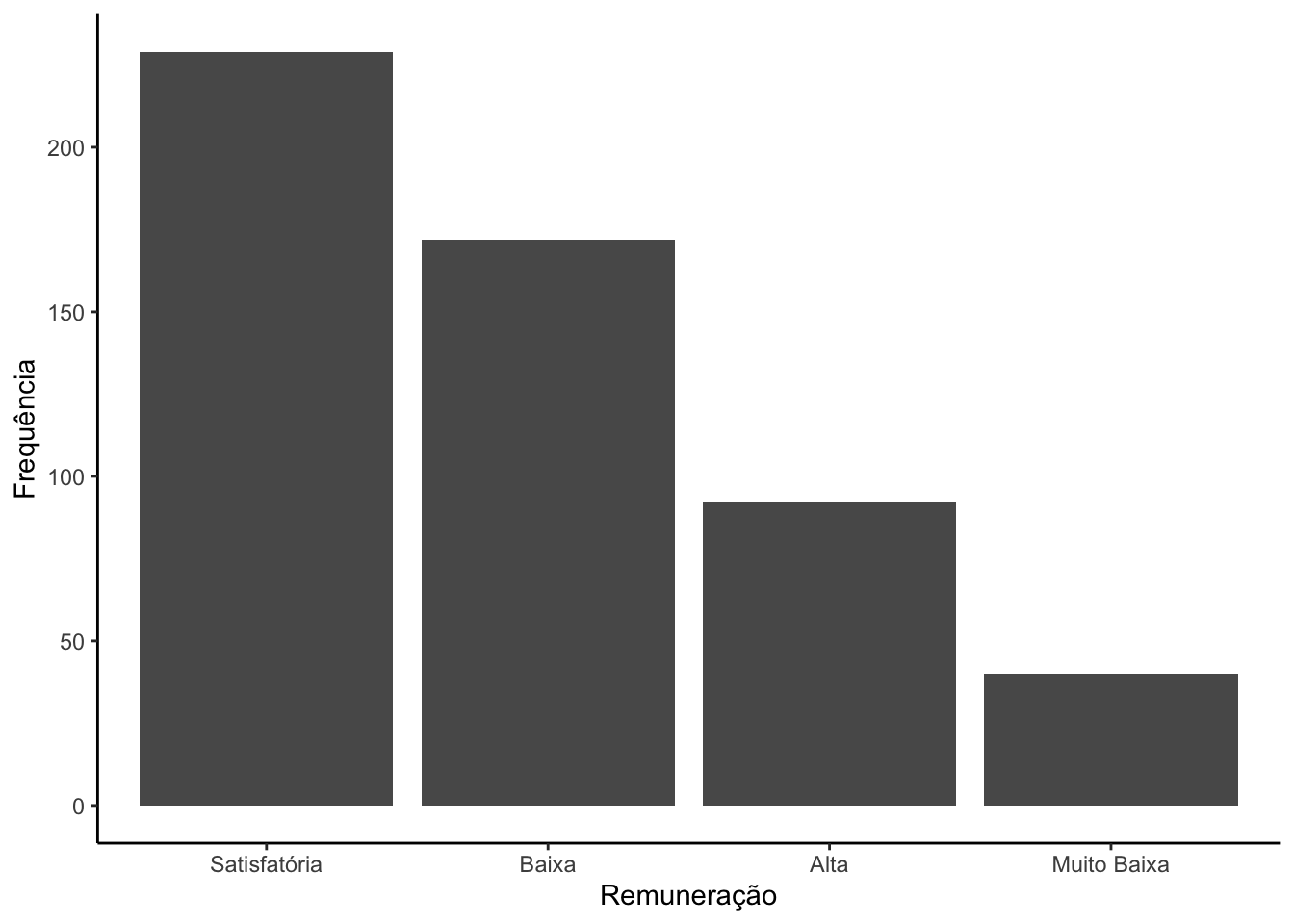
# Carregando pacoteslibrary(ggplot2)# Criando um gráfico de barras para a remuneração categorizada.survey |>ggplot(mapping =aes(x = remun_cat)) +#definindo o mapeamento, indicando a variável do eixo xgeom_bar() #definindo a geometria do gráfico
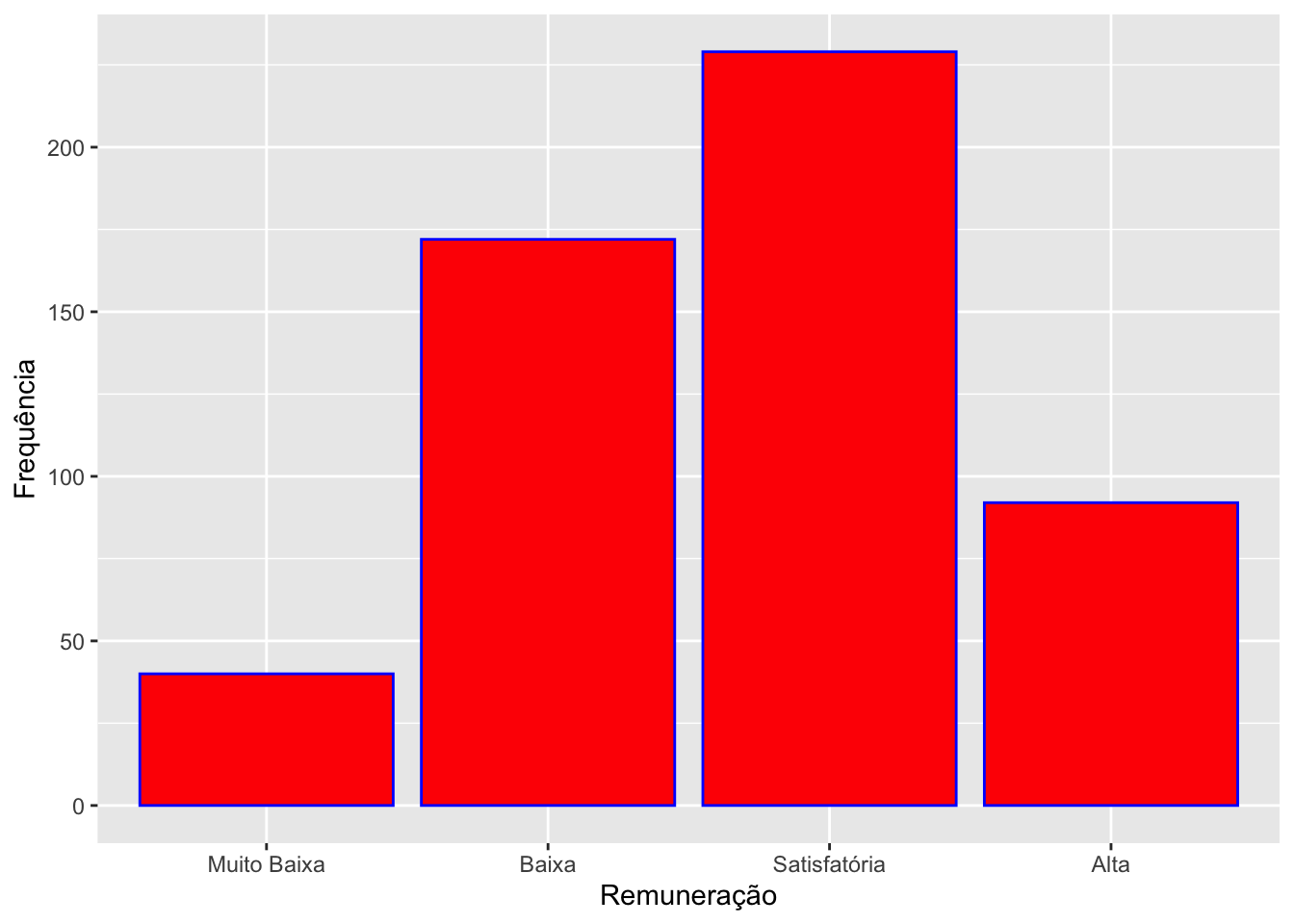
Podemos definir várias especificações na função geom_bar como fill e color . Eles controlam a cor da barra e do contorno da barra, respectivamente. Também vamos usar o labs para tratar os rótulos do gráfico.
# Modificando as cores e os rótulos.survey |>ggplot(mapping =aes(x = remun_cat)) +#definindo o mapeamento, indicando a variável do eixo xgeom_bar(fill ="Red", #defininfo a cor das barrascolor ="Blue") +#definindo a cor do contorno das barraslabs(x ="Remuneração", #modificando o rótulo do eixo xy ="Frequência") #modificando o rótulo do eixo y
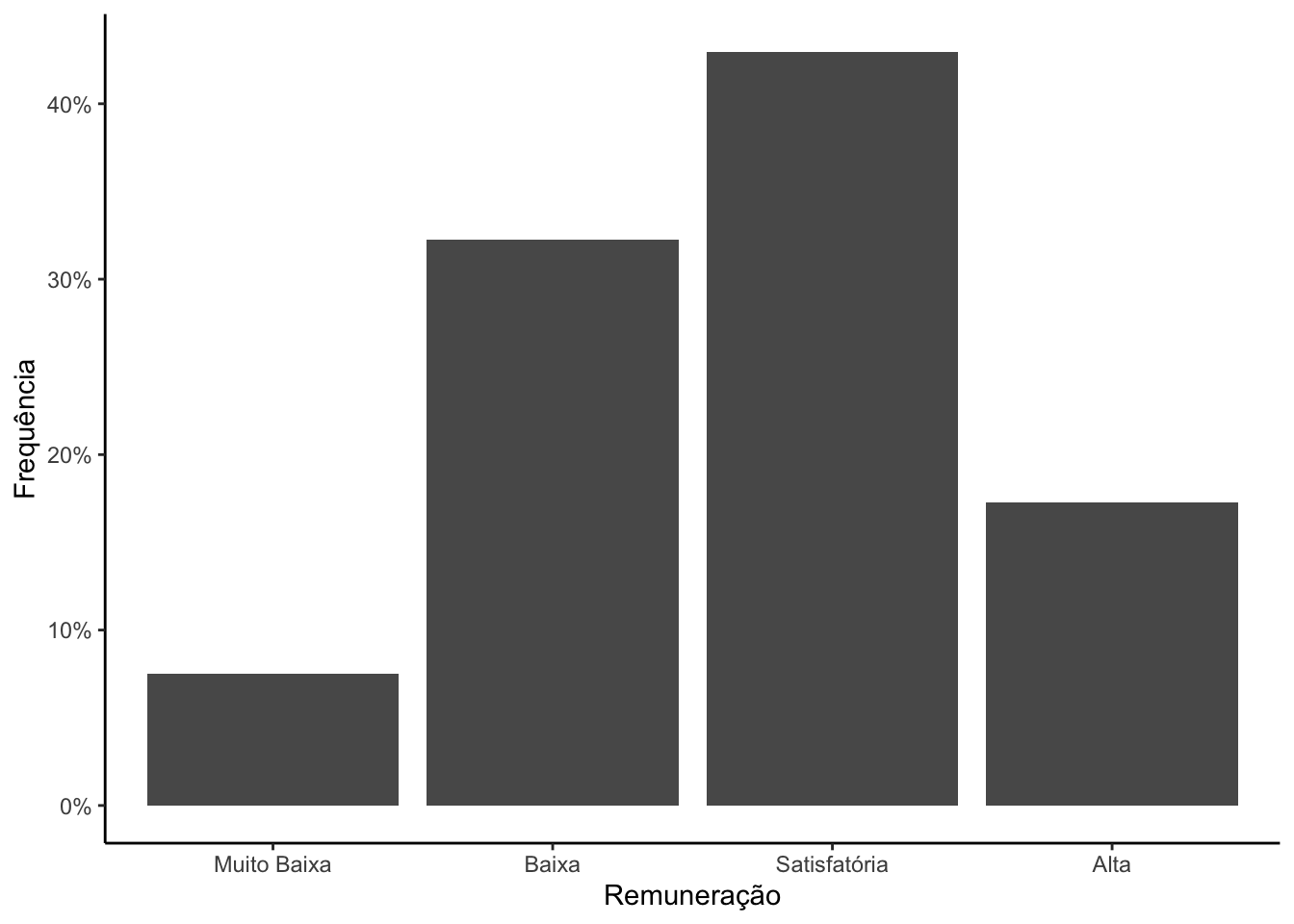
Suponha que o nosso desejo seja apresentar as porcentagens e não as frequências de cada categoria. Para executarmos esta ação, precisamos modificar no mapeamento da função ggplot o que será apresentado no eixo y. No exemplo abaixo, utilizamos o artifício de calcular as frequências relativas expressas por ..count../sum(..count..) e por meio da função scale_y_continuous apresentar o eixo y em porcentagem.
# Carregando pacoteslibrary(scales)
Attaching package: 'scales'
The following object is masked from 'package:readr':
col_factor
# Apresentando o gráfico em porcentagens.survey |>ggplot(mapping =aes(x = remun_cat, #definindo a variável do eixo xy = ..count../sum(..count..))) +#definindo a que será apresentado no eixo ygeom_bar() +#definindo a geometria do gráficolabs(x ="Remuneração", #modificando o rótulo do eixo xy ="Frequência") +#modificando o rótulo do eixo yscale_y_continuous(labels = percent) +#indicando que o eixo y será apresentado em porcentagemtheme_classic() #definindo um tema para o grádico
Warning: The dot-dot notation (`..count..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(count)` instead.
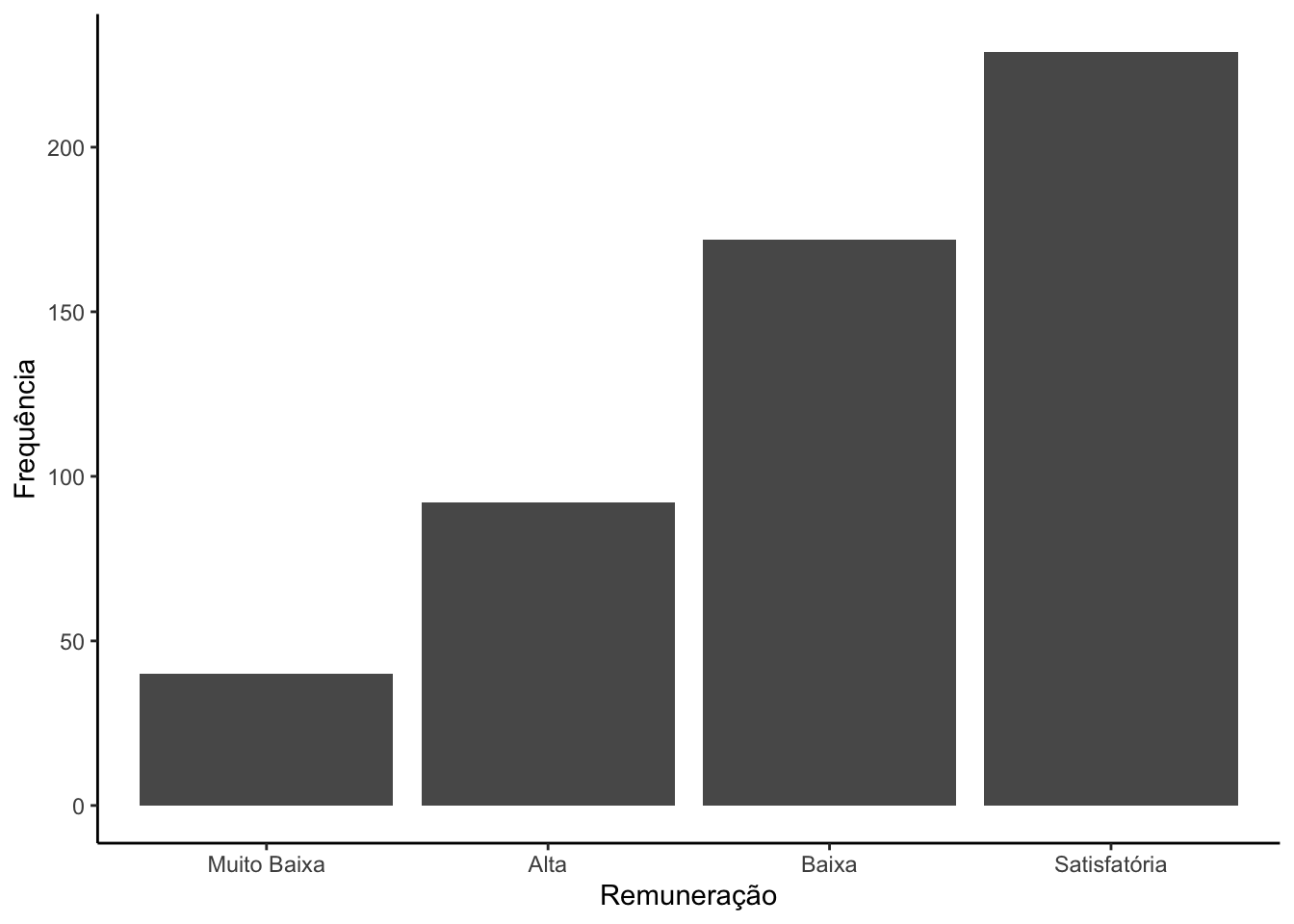
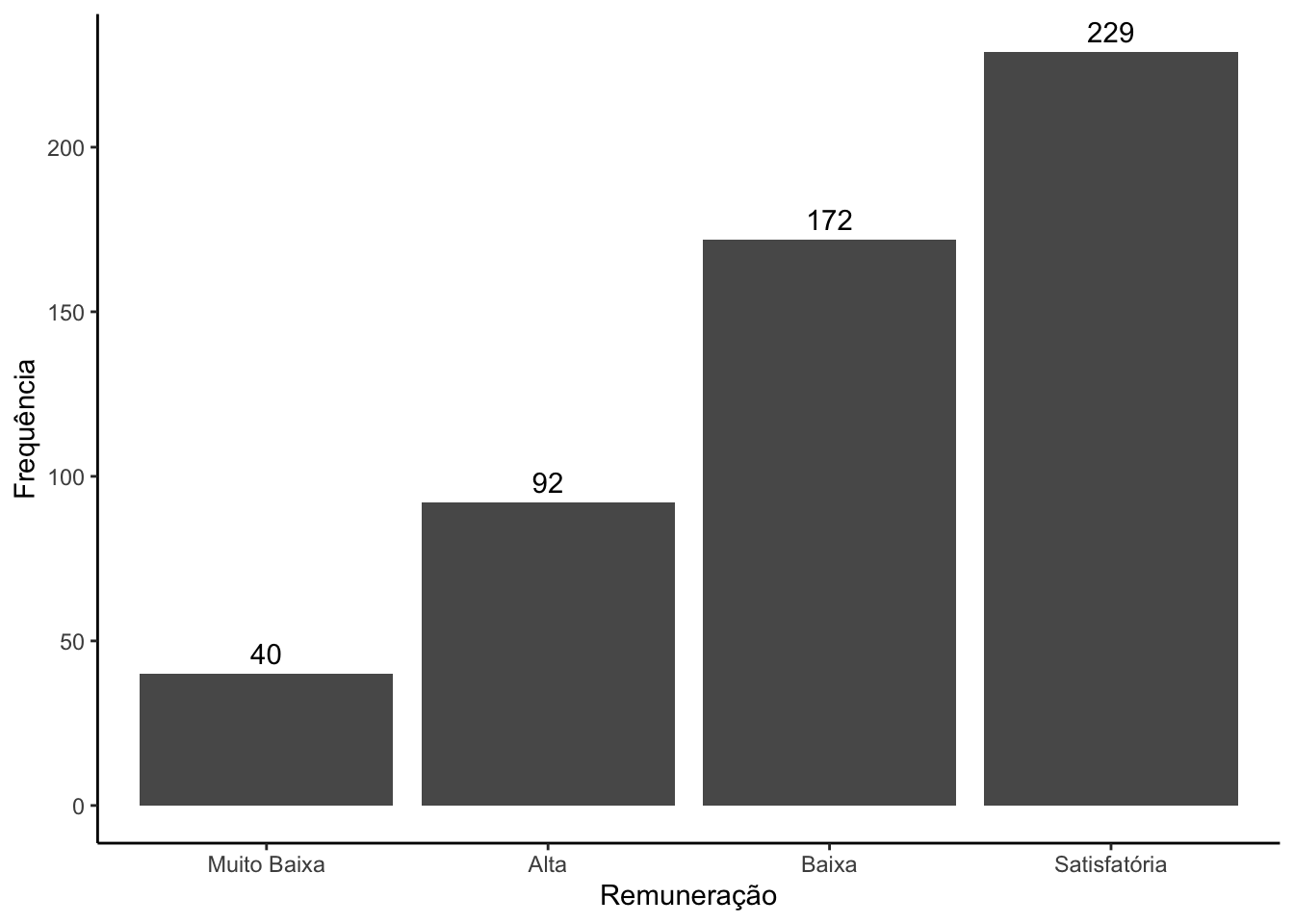
Como apresentar o gráfico de barras, segundo a ordenação das frequências? Existem algumas formas de executar esta tarefa. A seguir, apresetamos uma forma de ordenar de forma crescente ou decrescente
# Calculando o número de pessoaos em cada categoria de reuneraçãocont_remun <- survey |>count(remun_cat)# Visualizando o objeto criadocont_remun
# A tibble: 4 × 2
remun_cat n
<fct> <int>
1 Muito Baixa 40
2 Baixa 172
3 Satisfatória 229
4 Alta 92
# Criando o gráfico em ordem crescente.cont_remun |>ggplot(mapping =aes(x =reorder(remun_cat, n),y = n)) +geom_bar(stat ="identity") +labs(x ="Remuneração",y ="Frequência") +theme_classic()
# Criando o gráfico em ordem crescente.cont_remun |>ggplot(mapping =aes(x =reorder(remun_cat, -n),y = n)) +geom_bar(stat ="identity") +labs(x ="Remuneração",y ="Frequência") +theme_classic()
Para a contrução do gráfico foi preciso criar um tibble com as frequências das categorias da variável remuneração categorizada, usando a função count, e usá-lo para a construção do gráfico. A ordenação das categorias é feita no mapeamento do eixo x, por meio da função reorder, ou seja, no mapeamento colocamos no eixo x a coluna remun_cat ordenadas segundo os valores da coluna n e no eixo y os valores da coluna n. Além disso, é preciso modificar o stat de count para identity.
Para incluir os valores observados nas barras, usamos o geom_text, que é utilizado de forma geral para incluir uma camada de texto em um gráfico do ggplot. No mapeamento do geom_text foi incluído como rótulo os valores de n e o vjust controla o alinhamento vertical.
Atividade:Crie o código necessário para construir o gráfico abaixo.
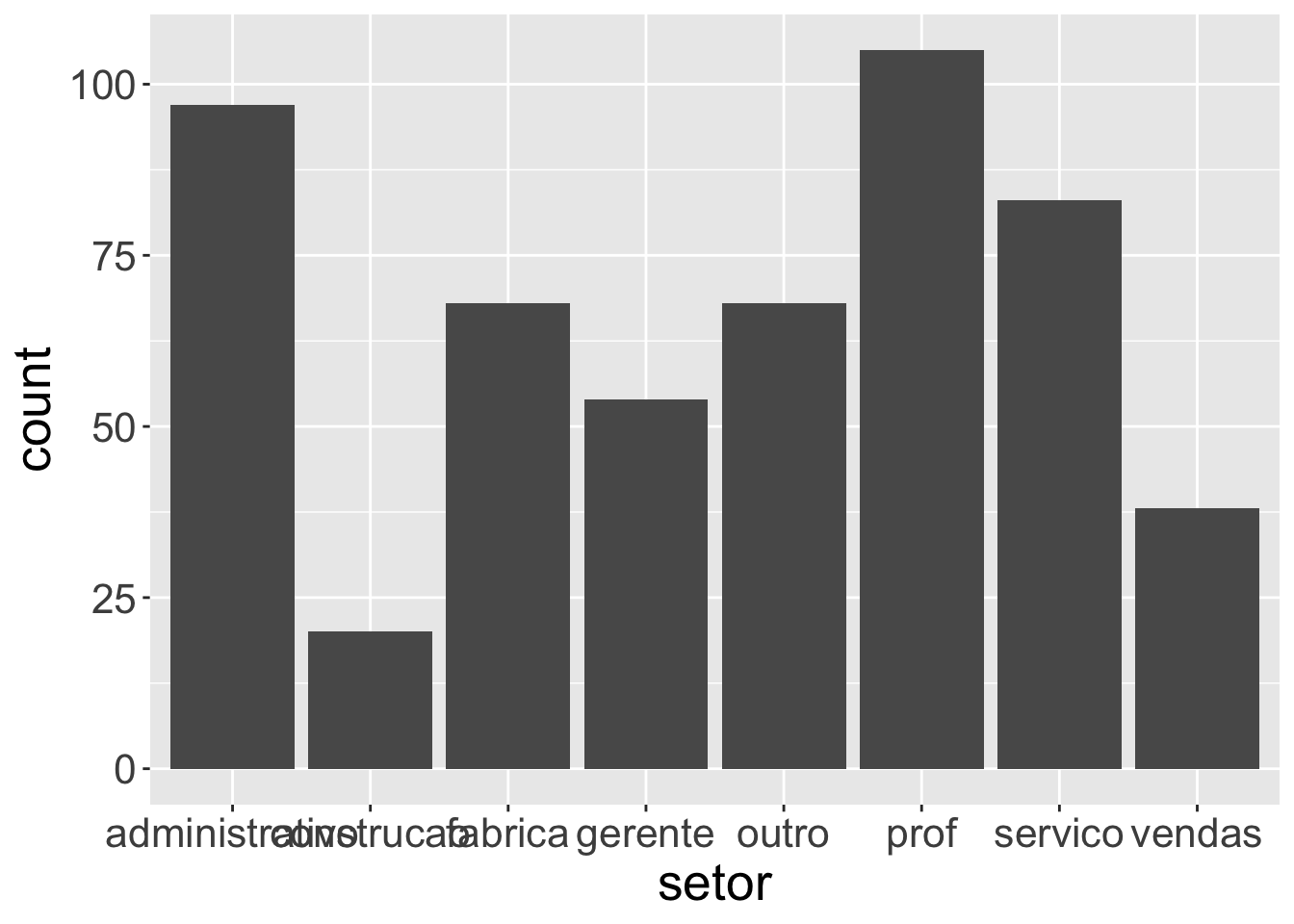
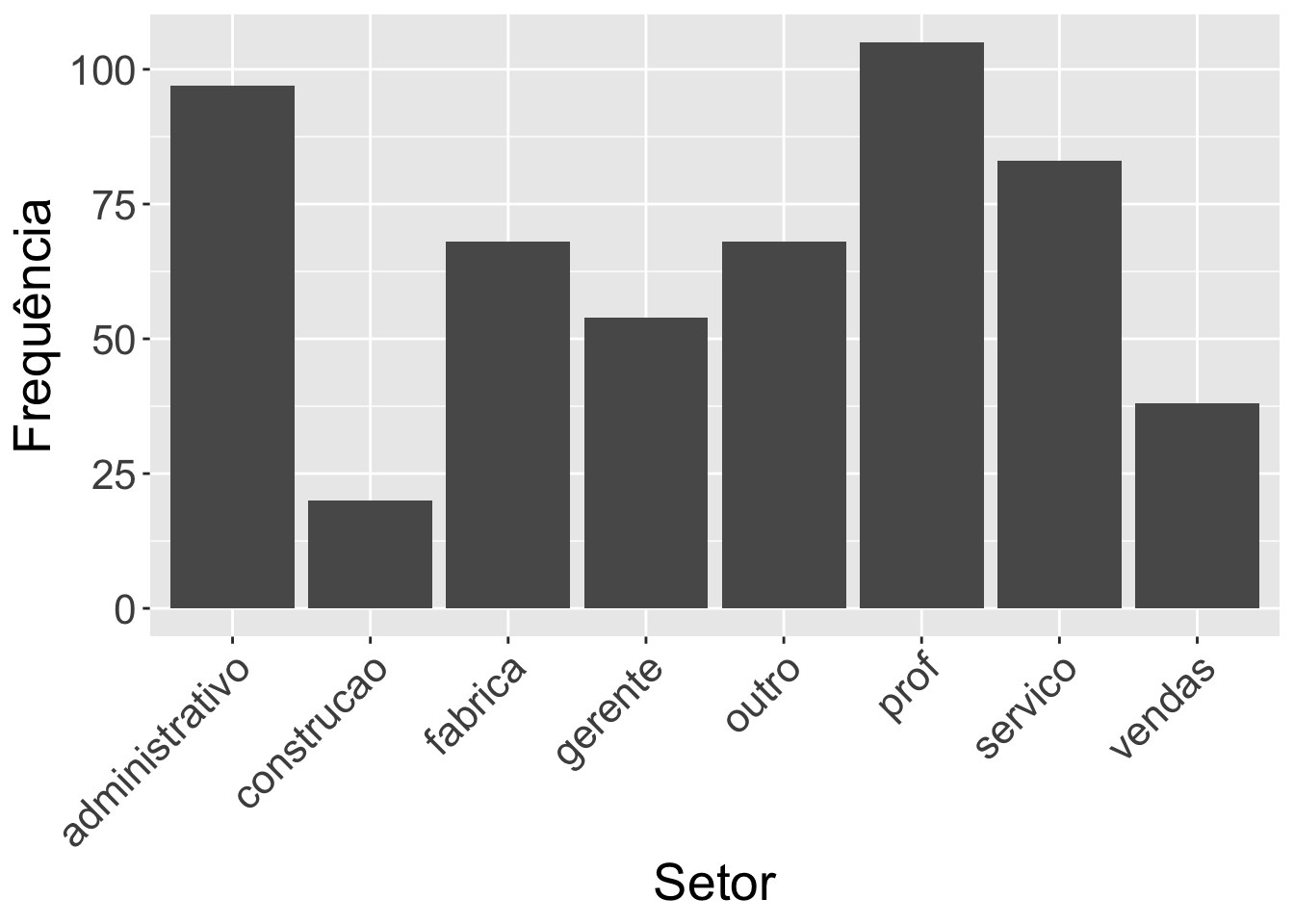
A seguir, apresentamos um gráfico de barras com o cuidado de aumentar o tamanho da letra dos rótulos das categorias dos setores para melhorar a visualização. Este tratamento é extremamente necessário em diversas situações para que as pessoas consigam entender melhor o gráfico.
# Aumentando o tamanho dos rótulos das categoriassurvey |>ggplot(mapping =aes(x = setor)) +geom_bar() +theme(text =element_text(size=20))
Entretanto, isso nos causou um problema, certo? Como resolver o problema de rótulos sobrepostos? A seguir, serão apresentadas 3 formas de melhorar a visualização sob esse aspecto.
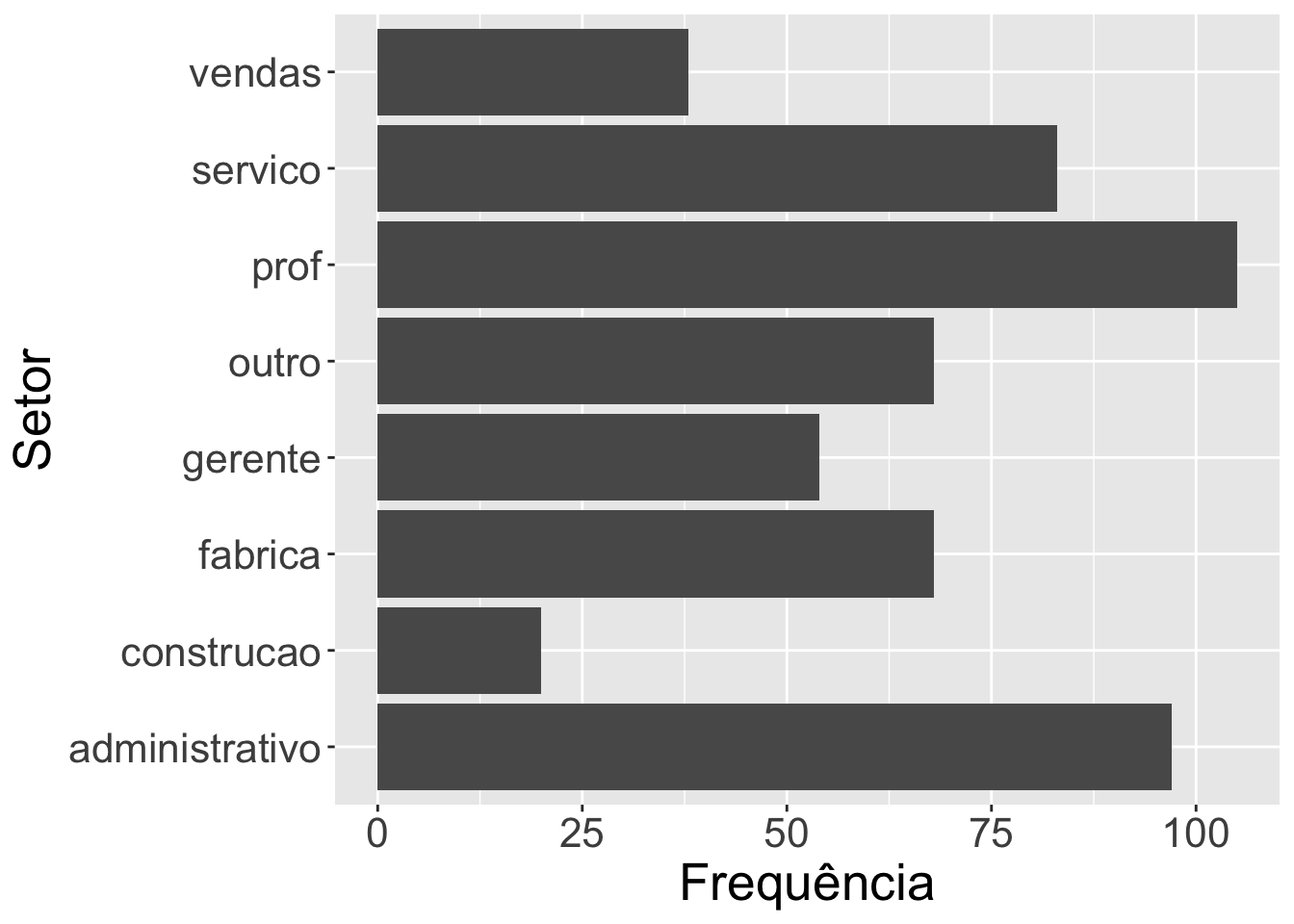
A primeira solução é simplesmente fazer uma inversão dos eixos. Isso é feito de forma simples no ggplot2 usando o a função coord_flip.
# Invertendo os rótulos x e ysurvey |>ggplot(mapping =aes(x = setor)) +geom_bar() +labs(y ="Frequência",x ="Setor") +theme(text =element_text(size=20)) +coord_flip()
Outra forma de resolver problema seria modificar o ângulo do texto no eixo x. É possível fazer essa modificação usando a função theme (é uma poderosa função para customizar componentes no gráfico).
# Modificando o ângulo do texto no eixo y survey |>ggplot(mapping =aes(x = setor)) +geom_bar() +labs(y ="Frequência",x ="Setor") +theme(text =element_text(size=20),axis.text.x =element_text(angle =45, hjust =1))
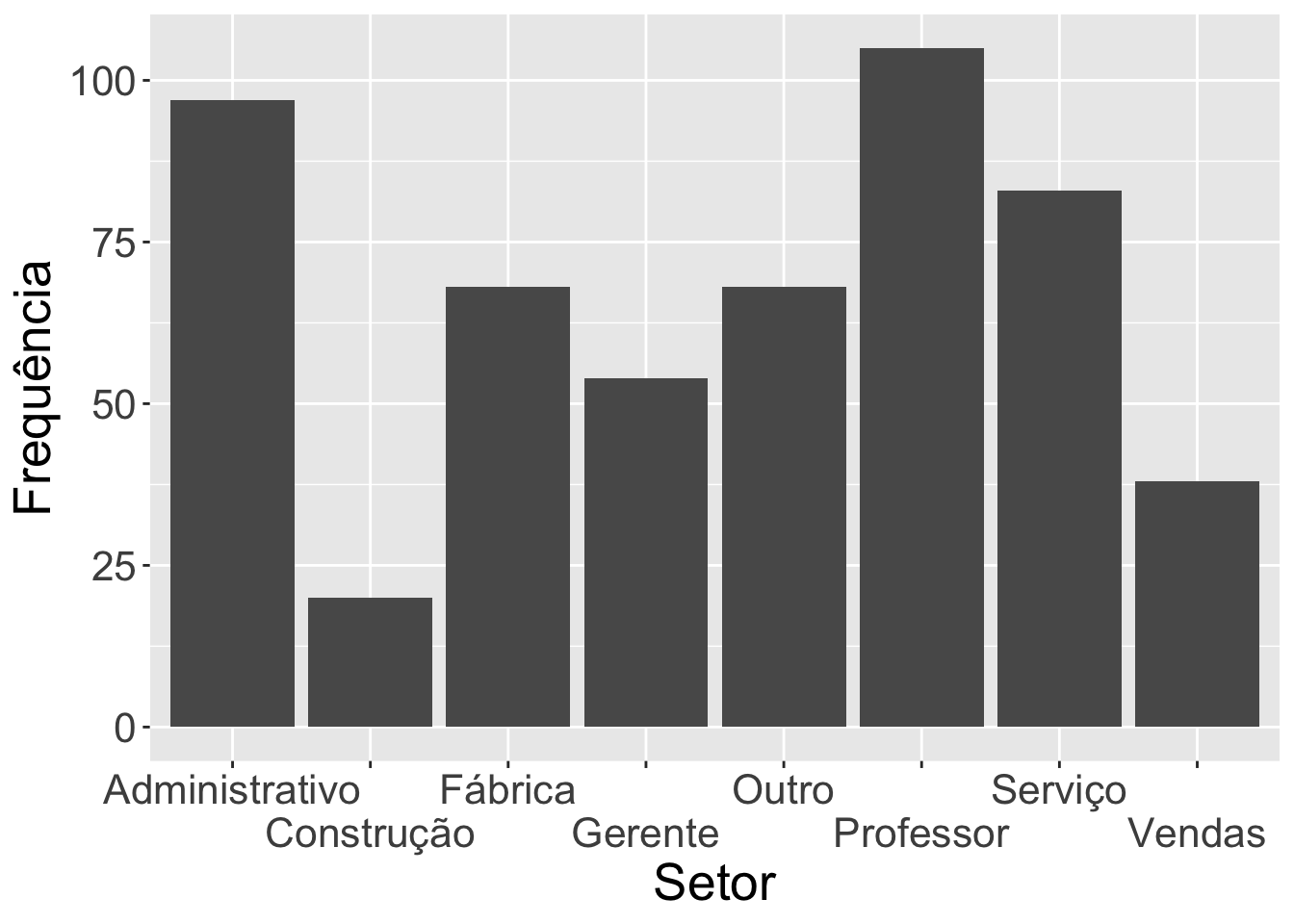
Por fim, a função scale_x_discrete por meio do componente guide nos permite fazer um tipo de escalonamento dos rótulos, resolvendo o problema da sobreposição. Nesta mesma função, usamos o componente labels para melhorar os rótulos das categorias da variável remuneração. Percebam que a base de dados continua intacta, as modificações foram realizadas na visualização.
# Escalonando e modificando os nomes das categorias da variável setorsurvey |>ggplot(mapping =aes(x = setor)) +geom_bar() +labs(y ="Frequência",x ="Setor") +theme(text =element_text(size=20)) +scale_x_discrete(guide =guide_axis(n.dodge =2),labels =c("vendas"="Vendas","servico"="Serviço","prof"="Professor","outro"="Outro","gerente"="Gerente","fabrica"="Fábrica","construcao"="Construção","administrativo"="Administrativo"))
4.1.2Gráfico de setores
O gráfico de setores (pizza) é bastante controverso quando se trata de visualização de dados. Se seu objetivo e comparar frequência das categorias de uma variável qualitativa, a visualização discutida anteriormente (gráfico de barras) é mais eficiente. Entretanto, se o seu objetivo é comparar cada categoria com o todo (por exemplo, que parte dos participantes possuem com salários altos em comparação com todos os entrevistados) e o número de categorias é pequeno, o gráfico de setores pode funcionar.
Fica um aviso, a quantidade de código para produzir um gráfico de setores interessante no R é grande.
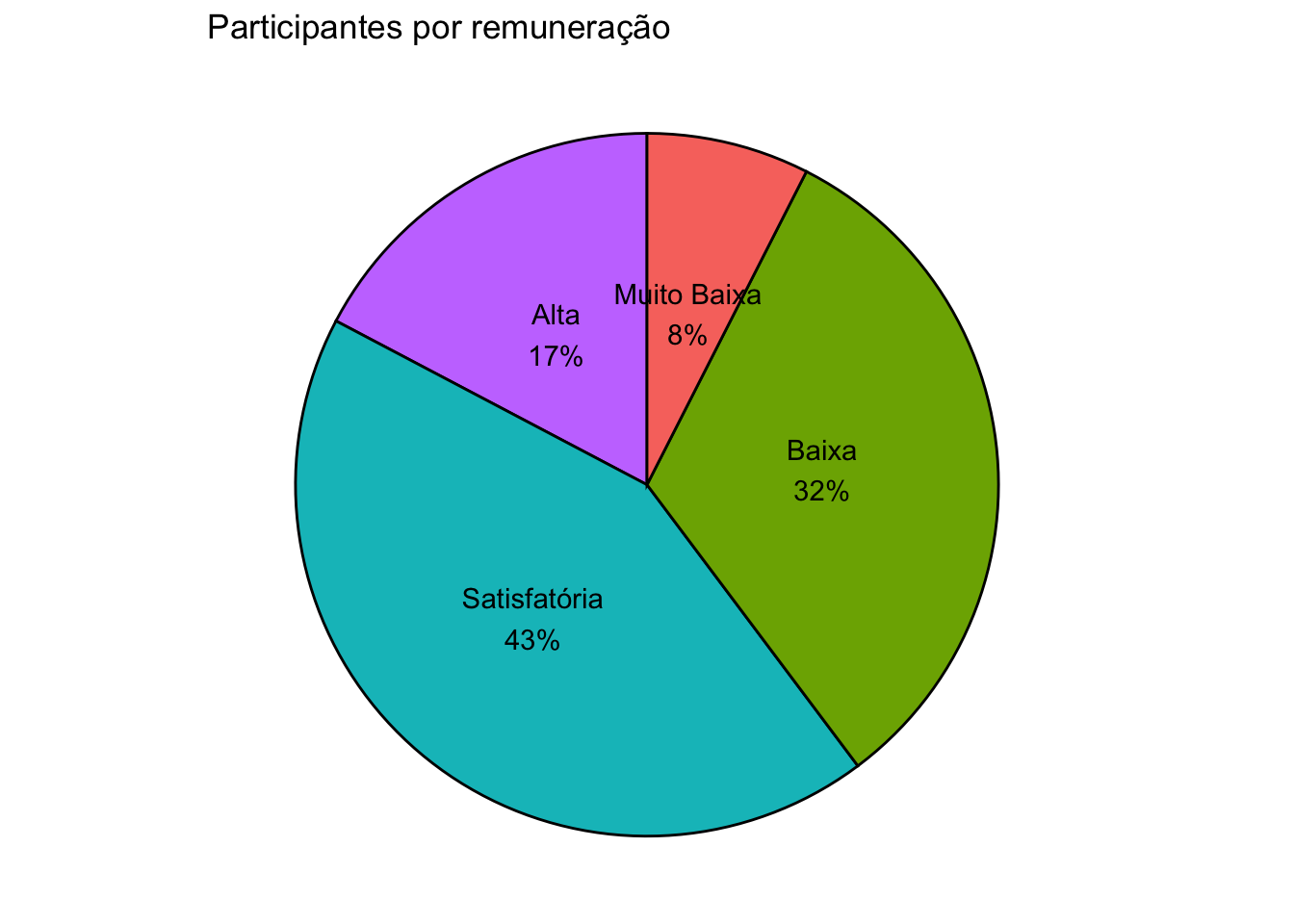
# Criando o objeto com as proporçõescont_remun <- survey |>count(remun_cat) |>arrange(desc(remun_cat)) |>mutate(prop =round(n*100/sum(n), 1),rot.ypos =cumsum(prop) -0.5*prop)# Visualizandocont_remun
# A tibble: 4 × 4
remun_cat n prop rot.ypos
<fct> <int> <dbl> <dbl>
1 Alta 92 17.3 8.65
2 Satisfatória 229 43 38.8
3 Baixa 172 32.3 76.4
4 Muito Baixa 40 7.5 96.4
# Adicionando os rótulos que irão aparecer no gráficocont_remun$rotulo <-paste0(cont_remun$remun_cat, "\n",round(cont_remun$prop), "%")# Criando um gráfico de setores com rótulosggplot(data = cont_remun, mapping =aes(x ="",y = prop, fill = remun_cat)) +geom_bar(width =1, stat ="identity", color ="black") +geom_text(mapping =aes(y = rot.ypos, label = rotulo), color ="black") +coord_polar("y", start =0, direction =-1) +theme_void() +theme(legend.position ="FALSE") +labs(title ="Participantes por remuneração")
Se tirarmos as funções geom_text e o theme o gráfico vira um gráfico de setores usual, com uma legenda indicando as categorias pelas cores.
4.1.3Tree map
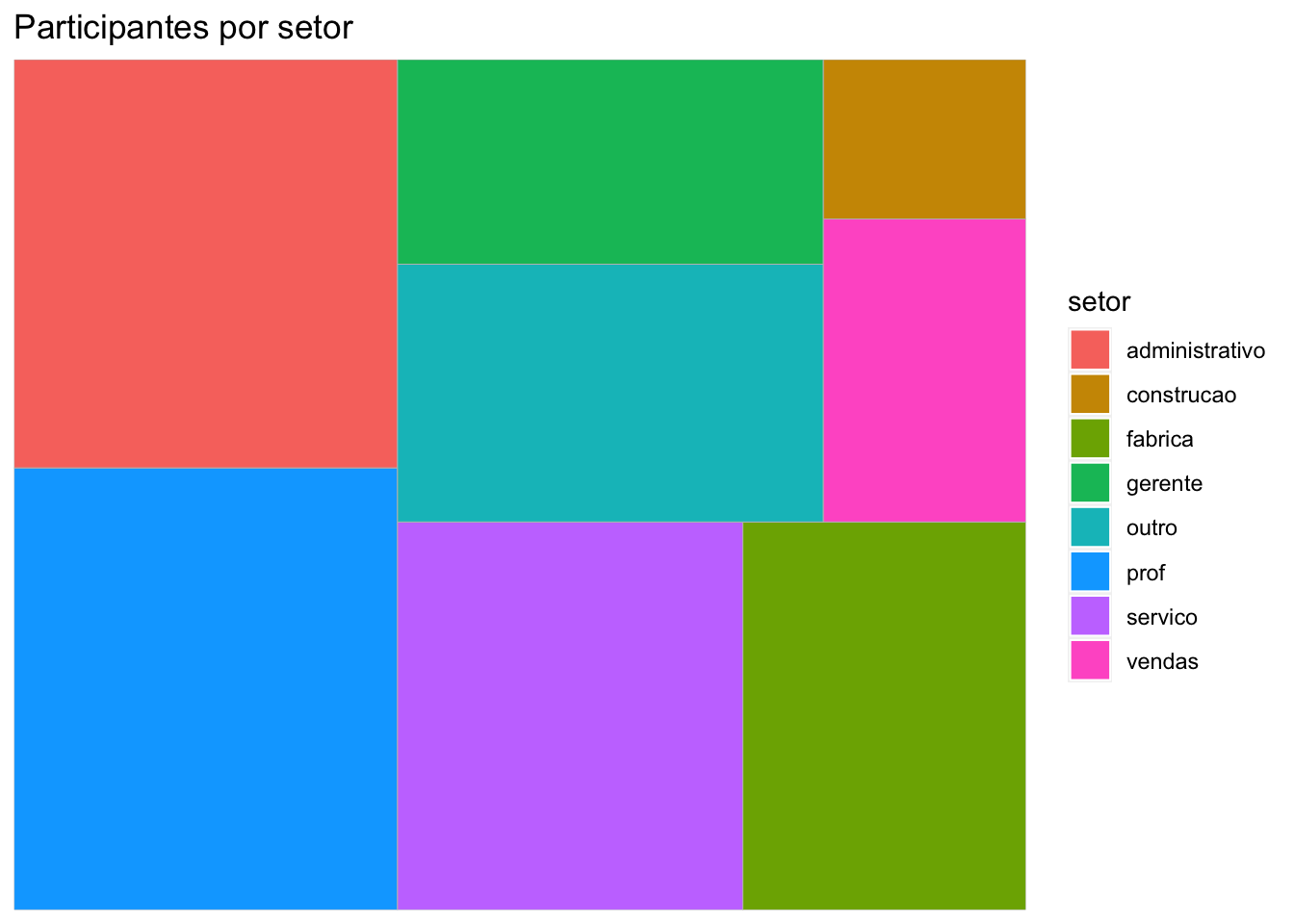
Uma alternativa para uma variável qualitativa com muitas categorias é o tree map.
# Carregando pacotelibrary(treemapify)# Calculando as frequências dos setorescont_setor <- survey |>count(setor)# Visualizandocont_setor
# Criando um treemap dos setoresggplot(data = cont_setor, mapping =aes(fill = setor,area = n)) +geom_treemap() +labs(title ="Participantes por setor")
# Incluindo os rótulos no tree mapggplot(data = cont_setor, mapping =aes(fill = setor,area = n,label = setor)) +geom_treemap() +geom_treemap_text(colour ="white", place ="centre") +labs(title ="Participantes por setor") +theme(legend.position ="none")
4.2Gráficos para variáveis quantitativas
A seguir serão apresentados os principais gráficos para visualizar a distribuição de uma única variável quantitativa. Discutiremos como manipular os argumentos das funções no ggplot para melhorar/modificar os gráficos.
4.2.1Histograma
O histograma é uma representação gráfica que mostra o formato da distribuição de uma variável. Ele apresenta a frequência de ocorrências de valores da variável em intervalos de classe.
# Histograma da idadesurvey |>ggplot(mapping =aes(x = idade)) +geom_histogram() +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
A modificações de cores é feita da mesma forma que no gráfico de barras.
# Histograma da idadesurvey |>ggplot(mapping =aes(x = idade)) +geom_histogram(fill ="Red",color ="White") +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Se quisermos controlar o número de intervalos, podemos fazer isso por meio do argumento bins. O default da função é um total de 30 intervalos, mas as vezes vale a pena reduzirmos esse número para termos uma melhor noção do formato da distribuição.
# Definindo o número de intervalos de classesurvey |>ggplot(mapping =aes(x = idade)) +geom_histogram(fill ="Red",color ="White",bins =15) +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")
Uma forma alternativa para controlar os intervalos de classe é definir as amplitudes dos intervalos. O argumento que faz esse controle é o binwidth.
# Definindo o tamanho da amplitude dos intervalos de classessurvey |>ggplot(mapping =aes(x = idade)) +geom_histogram(fill ="Red",color ="White",binwidth =5) +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")
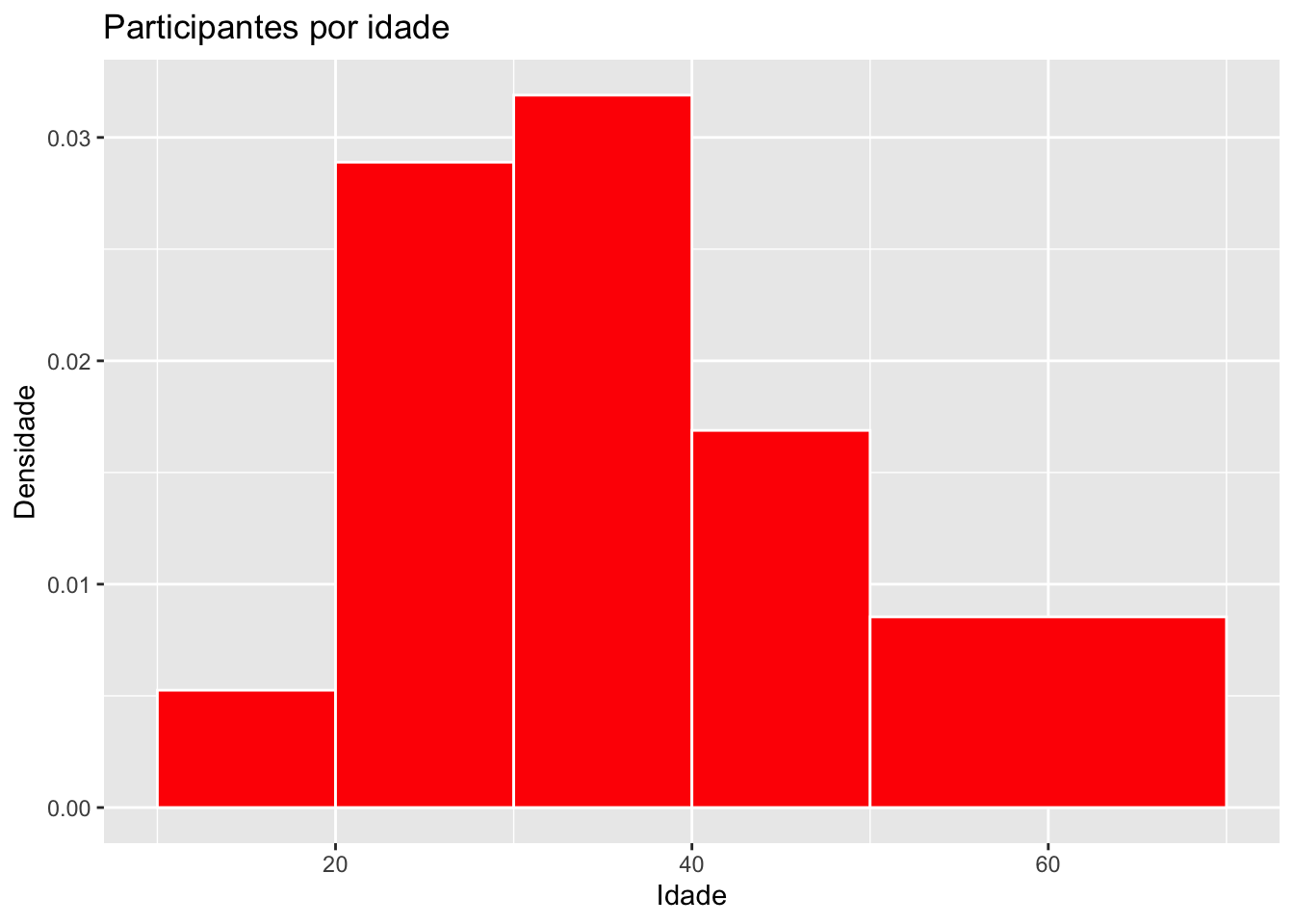
Para trabalharmos com histogramas com classes de amplitudes diferentes, precisamos lembrar que o histograma não é mais apresentado na escala de frequência e sim na de densidade. A seguir, apresentamos um exemplo para a variável idade.
# Criando intervalos de classes com amplitudes diferentessurvey |>ggplot(mapping =aes(x = idade,y =after_stat(density))) +geom_histogram(fill ="Red",color ="White",breaks =c(10,20,30,40,50,70)) +labs(title ="Participantes por idade",x ="Idade",y ="Densidade")
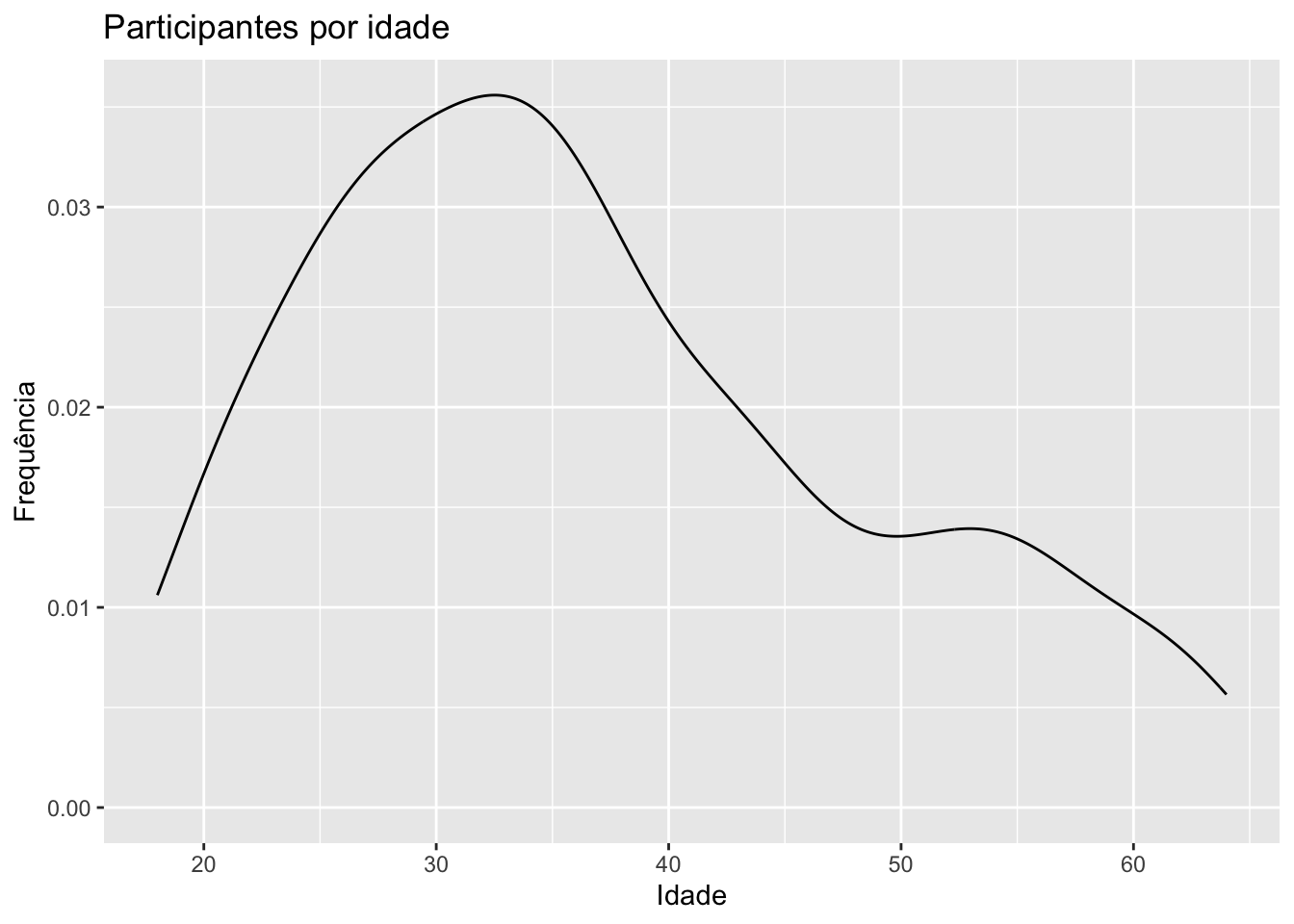
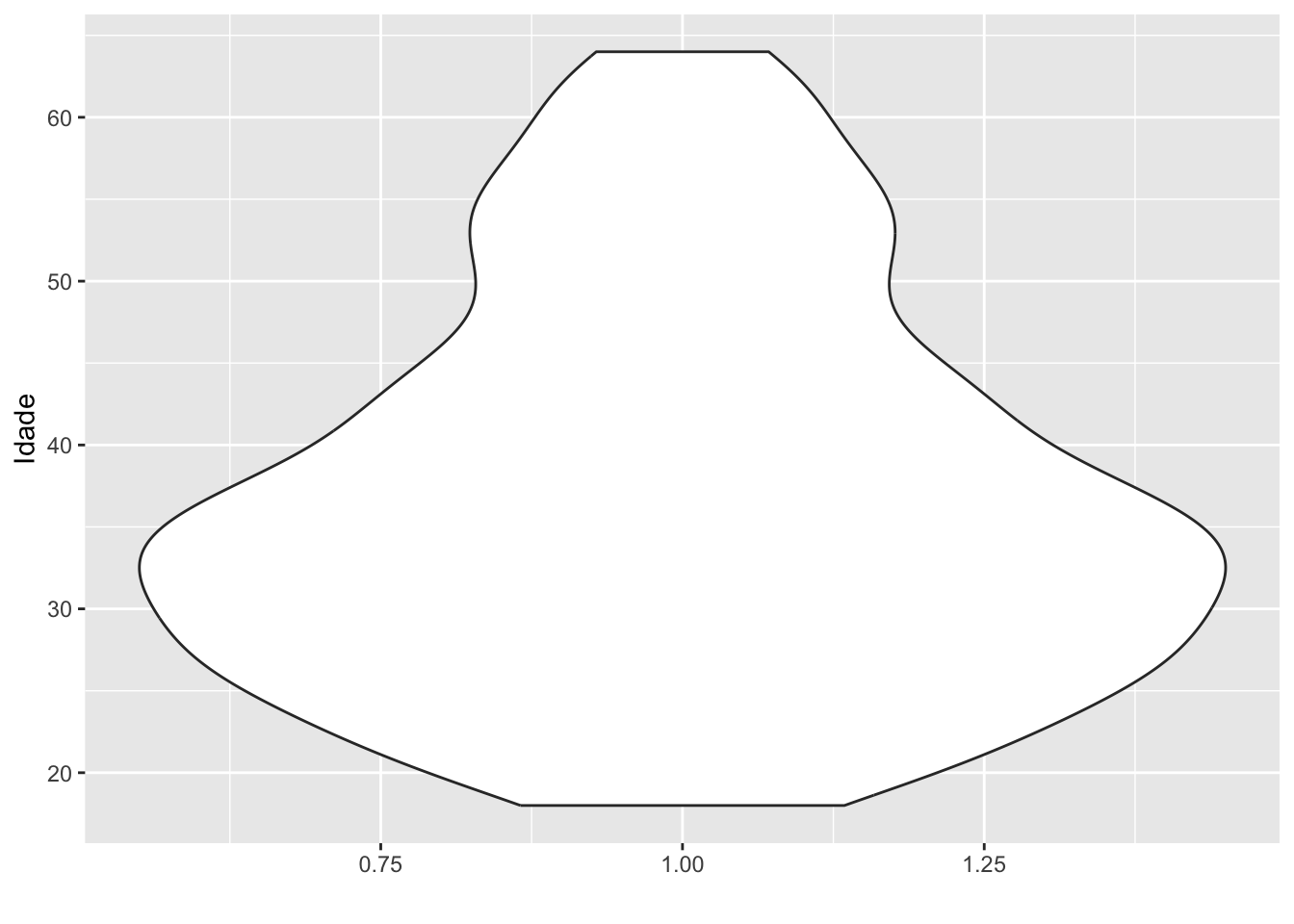
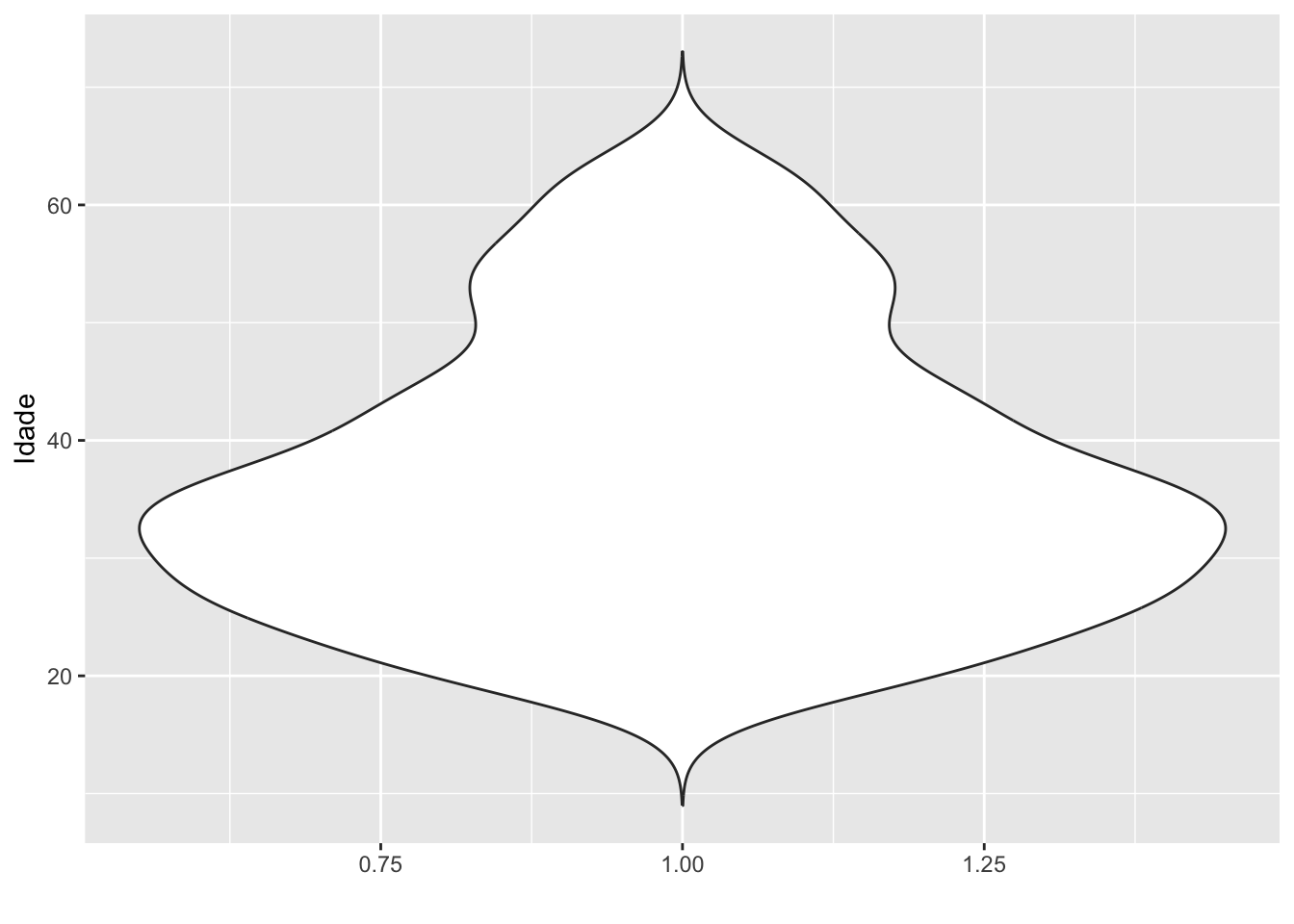
4.2.2Densidade
O gráfico da densidade é um alisamento do histograma. Sendo assim, útil também para entender o formato da distribuição dos dados.
# Densidade da idadesurvey |>ggplot(mapping =aes(x = idade)) +geom_density() +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")
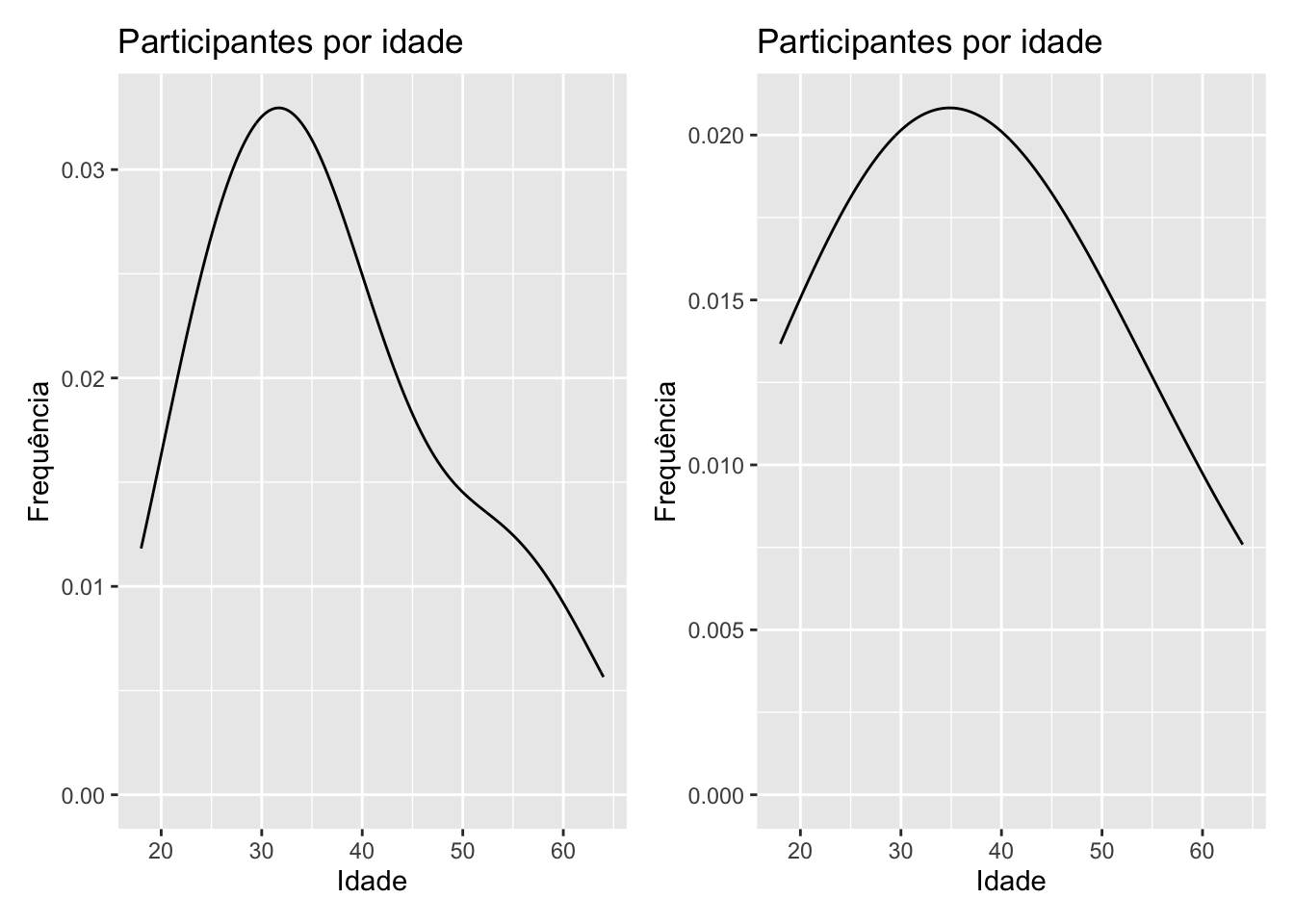
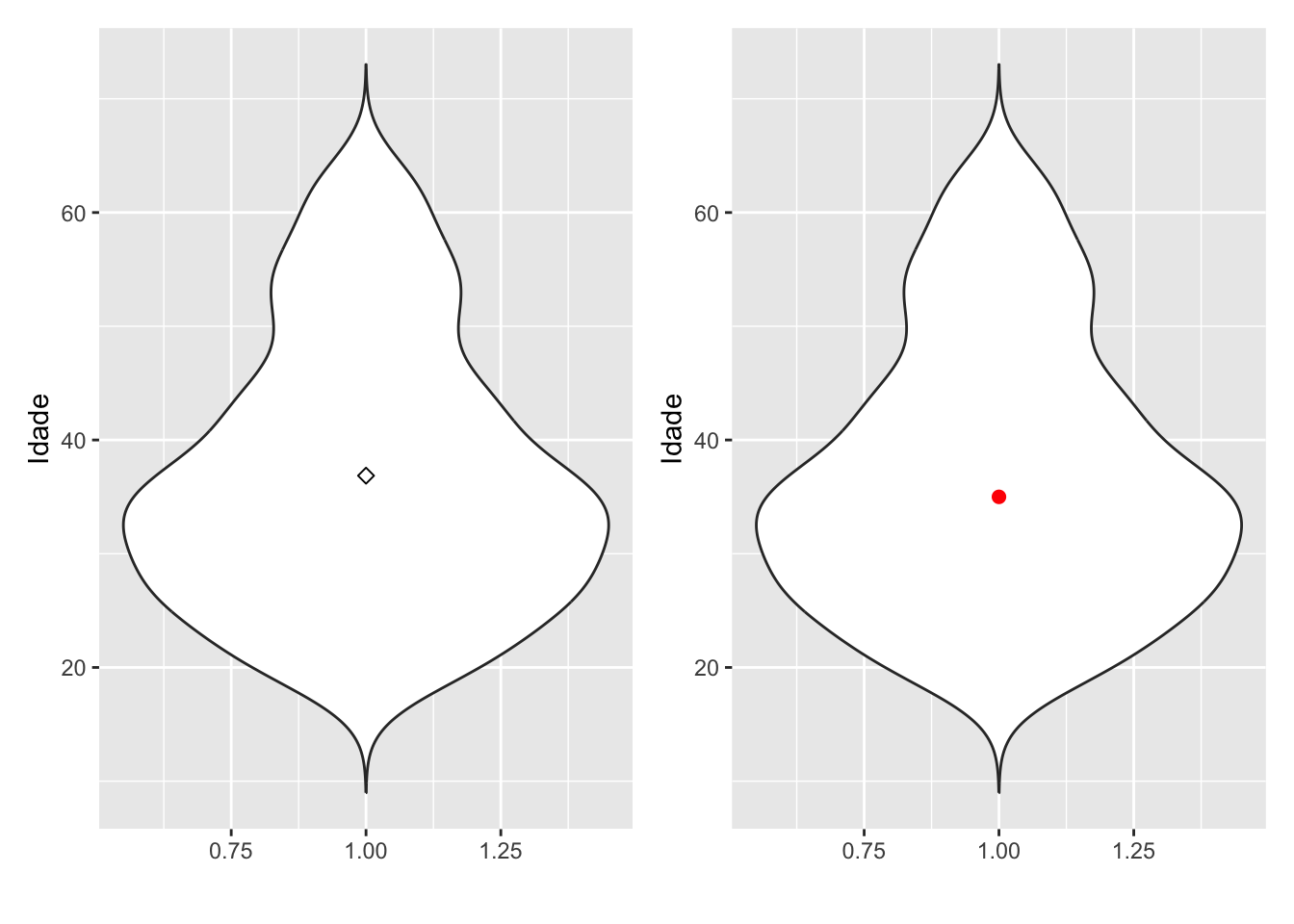
# Densidade da idadedens1 = survey |>ggplot(mapping =aes(x = idade)) +geom_density(bw =5) +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")dens2 = survey |>ggplot(mapping =aes(x = idade)) +geom_density(bw =15) +labs(title ="Participantes por idade",x ="Idade",y ="Frequência")#Ativando pacotelibrary(patchwork)dens1 + dens2
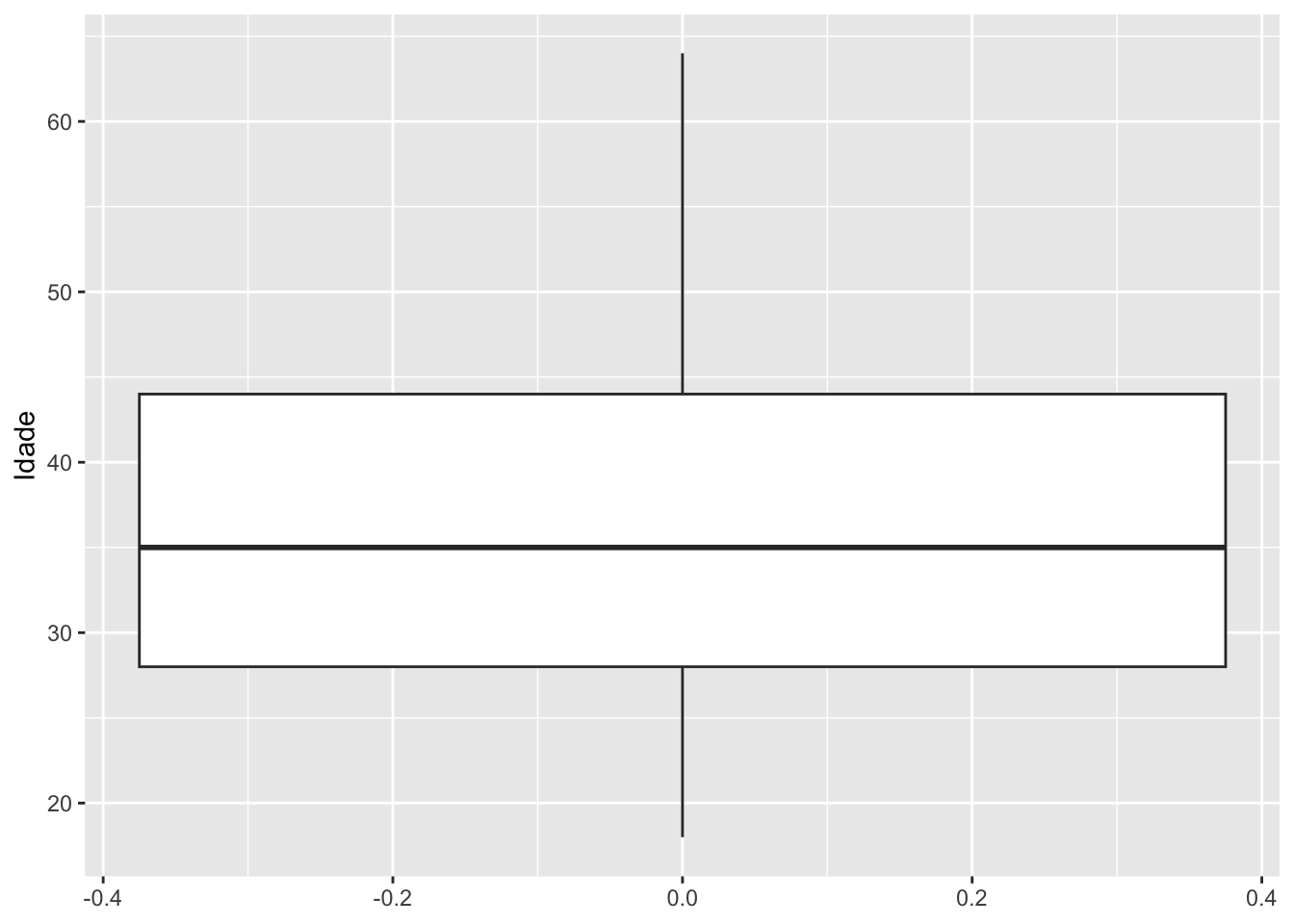
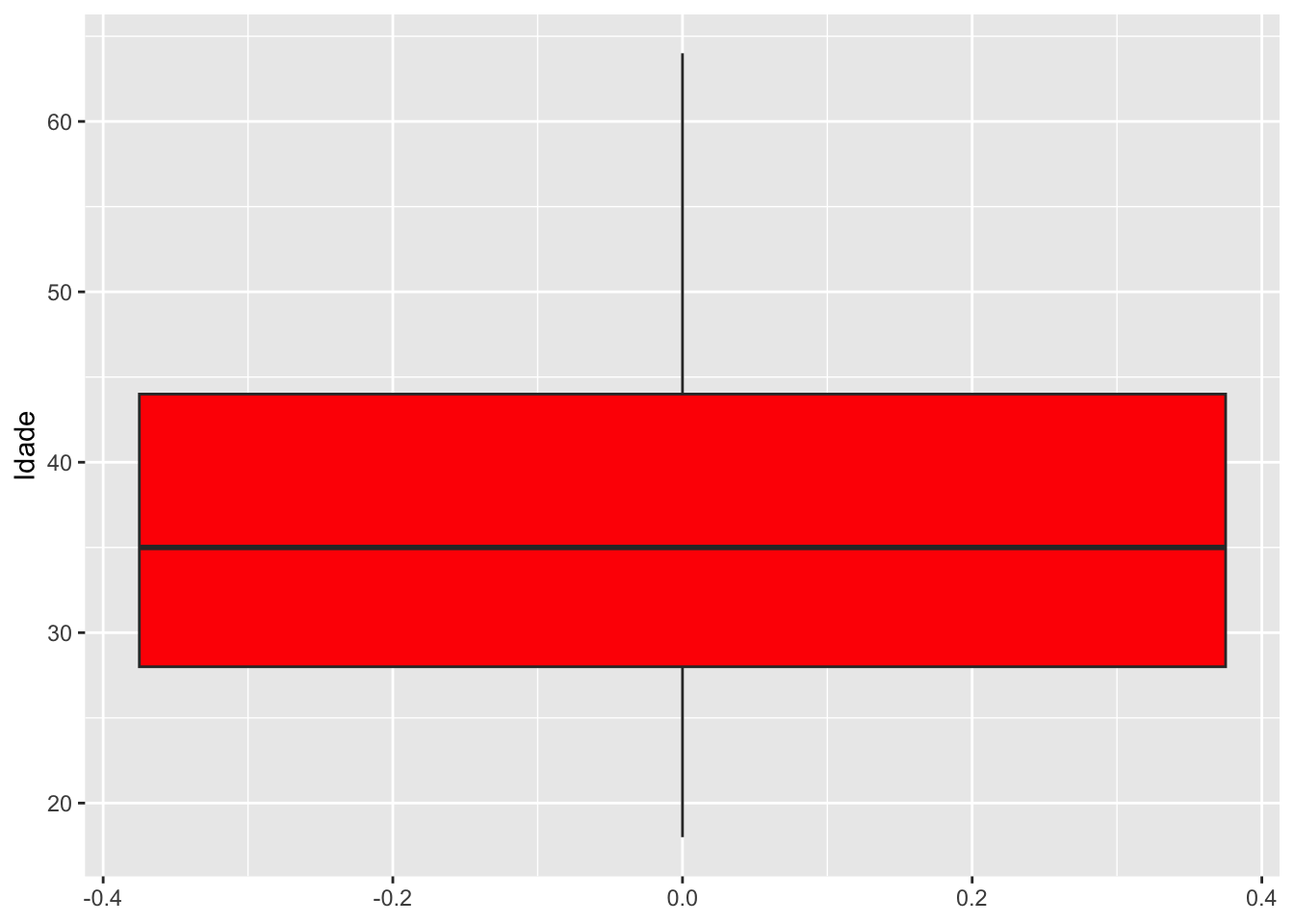
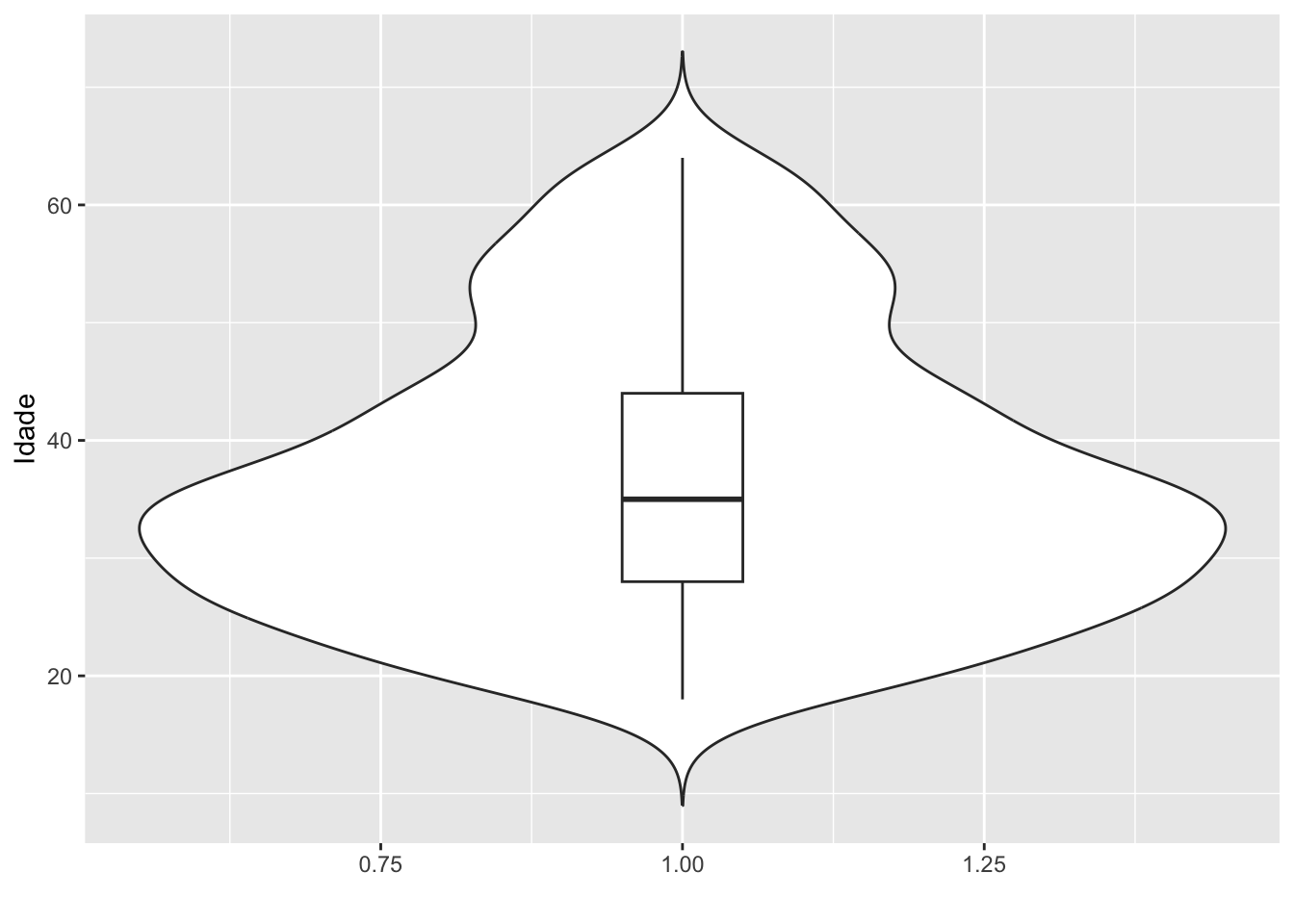
4.2.3Boxplot
O boxplot é uma representação usada para verificar a distribuição de uma variável por meio de seus quantis. Aqui é possível verificar os valores de mínimo, máximo e os quartis. Além disso, indica a existência de valores discrepantes.
A função geom_boxplot é responsável pela geometria de um boxplot no ggplot2.