#Criando um vetor x
x = c(2, 5, 7, 1, 8, 3)
#Calculando a média dos elementos de x com 2 casas decimais
x |>
mean() |>
round(digits = 2)[1] 4.33Para que possamos construir uma boa visualização de dados, precisamos inicialmente conseguir trabalhar/manipular os dados no nosso ambiente de trabalho (R). Estamos falando principalmente sobre importação e limpeza de dados.
De maneira simples, um projeto pode ser comparado a uma pasta em seu computador que contém todos os arquivos relacionados à análise que está sendo realizada. Essa funcionalidade é altamente benéfica para a organização e deve ser considerada uma prática recomendada para qualquer cientista de dados.
Para iniciar a criação de um projeto chamado de Análise1, siga estes passos: vá ao menu File \(\longrightarrow\) New Project. Em seguida, você pode optar por criar o projeto em um novo diretório específico para hospedar seu projeto ou usar um diretório existente. Para criar um novo diretório, clique em New Directory.
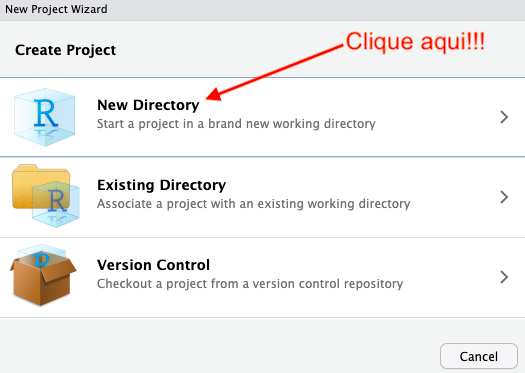
Na próxima janela, você terá a opção de escolher o tipo de projeto que deseja criar. Para prosseguir, clique em New Project.
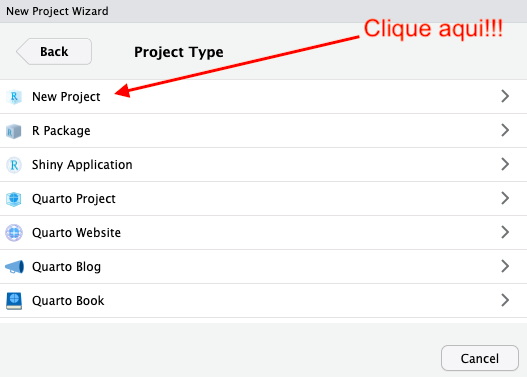
A próxima janela permite que você escolha o nome da pasta que abrigará o projeto e o diretório onde ela será armazenada.
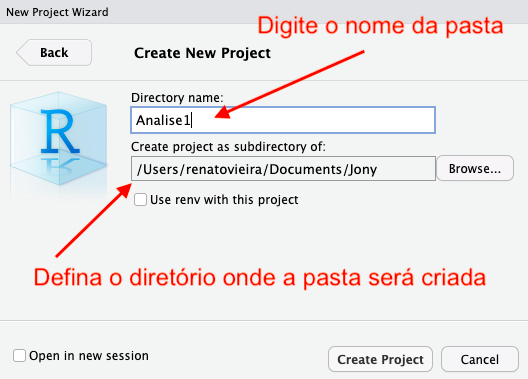
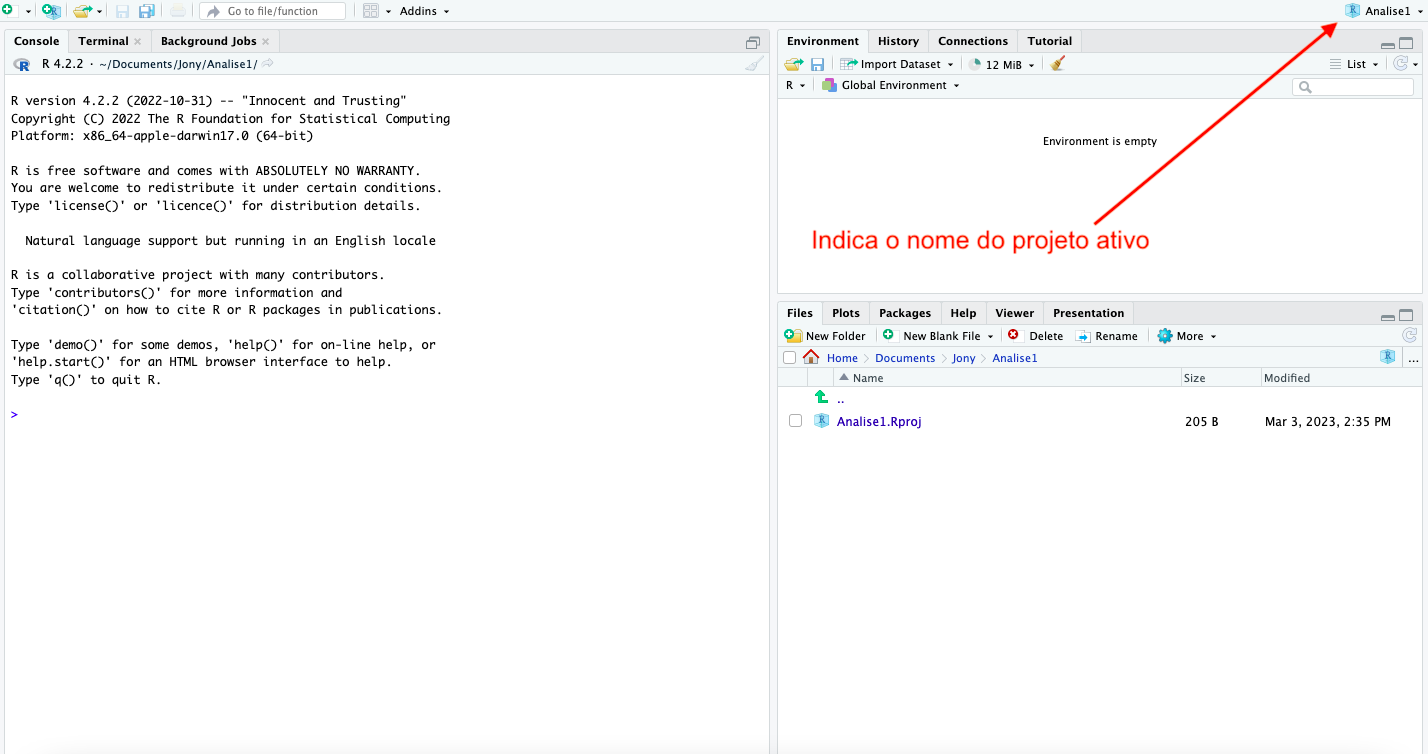
Após a criação do projeto, o RStudio indicará qual projeto está ativo, como ilustrado na figura abaixo.

Pipes são ferramentas extremamente poderosas para clarear (decodificar) uma sequência de múltiplas operações.
Podemos apontar o operador pipe como uma das grandes revoluções dos último tempos no R, pois torna a leitura de uma sequência de códigos muito mais lógica, fácil e compreensível.
O |> é um operador nativo do R, que encontraremos disponível a partir da versão 4.1.
Basicamente, o operador |> usa o resultado do seu lado esquerdo como primeiro argumento da função do lado direito. Só isso!!!
No código abaixo, para termos acesso ao |> vamos carregar o pacote tidyverse (que carrega diversos pacotes).
#Criando um vetor x
x = c(2, 5, 7, 1, 8, 3)
#Calculando a média dos elementos de x com 2 casas decimais
x |>
mean() |>
round(digits = 2)[1] 4.33Com o código descrito acima, enviamos o objeto x como o primeiro argumento da função mean e, em seguida, enviamos o resultado da expressão mean(x) como o primeiro argumento da função round, que diferentemente da função mean, necessita de dois argumentos, o valor a ser arredondado e o número de casas decimais, no caso digits = 2.
Mas qual foi o ganho? Se escrevermos os comandos na forma usual temos:
#Calculando a media de x com 2 casas decimais na forma usual
round(x = mean(x),
digits = 2)[1] 4.33Aparentemente, o ganho não foi tão grande que justifique essa euforia com o operador. Isso ocorreu por que o exemplo acima usou apenas duas funções. Agora pense que precisamos executar 10 funções aninhadas! O uso do |> vai permitir transformar um código confuso e difícil em algo simples e intuitivo.
Retiramos o exemplo abaixo do Curso-r (2022), e ele se refere a seguinte situação problema: “vamos imaginar que precisamos escrever uma receita de um bolo usando o R, e cada passo da receita é uma função”:
#Receita do bolo
esfrie(asse(coloque(bata(acrescente(recipiente(rep("farinha", 2), "água", "fermento", "leite", "óleo"), "farinha", ate = "macio"), duracao = "3min"), lugar = "forma", tipo = "grande", untada = TRUE), duracao = "50min"), "geladeira", "20min")Entenderam????? Imaginamos que não!
|> no código:
#Receita do bolo com |>
recipiente(rep("farinha", 2), "água", "fermento", "leite", "óleo") |>
acrescente("farinha", ate = "macio") |>
bata(duracao = "3min") |>
coloque(lugar = "forma", tipo = "grande", untada = T) |>
asse(duracao = "50min") |>
esfrie("geladeira", "20min")Agora o código realmente parece uma receita de bolo, certo?
Já estão apaixonados pelo tidyverse?

Para você ativar o atalho Ctrl + Shift + m no Windows ou Cmd + Shift + m no Mac, precisamos ativar esta opção. Basta irmos no menu Tools \(\longrightarrow\) Global Options \(\longrightarrow\) Code e ativar a caixa como especificado abaixo (é preciso ter uma versão igual ou superior a 4.1 do R):
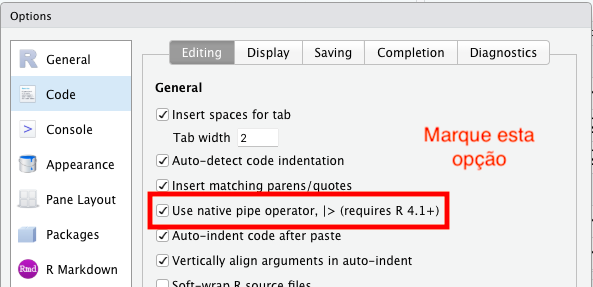
Aqueles que forem usuários do %>% do pacote magrittr, poderão perceber que existe grande semelhança entre o operador pipe nativo da linguagem com o pipe do pacote. Existem sim, algumas diferenças que não são tão importantes neste momento. Para aqueles que estiverem conhecendo o operador pipe pela primeira vez, sugiro fortemente o uso do pipe nativo |>.
readr
Este pacote tem como objetivo facilitar de maneira rápida e amigável a importação de dados tabulares, tais como arquivos .txt, .csv, .tsv e .fwd.
As principais funções deste pacote para importação de dados incluem:
read_table: usada para importar arquivos em que as colunas são separadas por um ou mais espaços em branco.
read_csv: usada para importar arquivos delimitados por vírgula.
read_csv2: usada para importar arquivos separados por ponto e vírgula (comum em países que utilizam a vírgula como separador decimal).
read_tsv: usada para importar arquivos separados por tabulação.
read_delim: uma função mais flexível que engloba tanto read_csv quanto read_tsv, permitindo maior personalização na importação de arquivos.
Vamos usar a função read_delim para importarmos arquivos com extensão .txt. Os principais argumentos da função são:
file - o arquivo a ser importado;
delim - o caracter usado para separar as variáveis;
col_names - um argumento lógico indicando se o arquivo possui ou não os nomes das variáveis (default = TRUE);
na - qual a codificação usada para dado faltante (default = NA);
skip - número de linhas a serem puladas no momento da importação (default = 0);
locale - controla vários aspectos como decimal, enconding, entre outros.
Crie um projeto chamado Saude! Abra o Script Cap2.
Após especificarmos a pasta de trabalho, precisamos ativar o pacote readr e utilizarmos a função read_delim como a seguir.
#Ativando o pacote readr
library(readr)
#Importando o arquivo Base saude.txt
base_saude = read_delim(file = "Base saude.txt")Rows: 200 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (2): Codigo, Datacol
dbl (6): Sexo, Idade, HIV, Escol, DST, Tipo
num (2): Peso, Estatura
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_saude# A tibble: 200 × 10
Codigo Datacol Sexo Idade Peso Estatura HIV Escol DST Tipo
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AB01 14/10/15 1 20 612 16 1 3 1 2
2 AB02 09/02/16 0 30 60 155 0 5 0 9
3 AB03 01/03/10 0 50 80 183 1 2 1 3
4 AB04 04/05/13 0 43 83 19 1 9 1 2
5 AB05 20/05/14 0 22 753 175 0 2 1 3
6 AB06 30/01/11 1 15 702 17 1 6 0 9
7 AB07 05/08/15 1 22 60 165 1 5 1 3
8 AB08 08/12/13 1 25 62 155 0 1 0 2
9 AB09 03/11/10 1 32 61 162 1 4 1 1
10 AB10 10/10/10 1 33 55 155 1 5 1 9
# ℹ 190 more rowsAo usarmos as funções do pacote readr para importarmos arquivo, a primeira coisa que percebemos é que são apresentadas a forma como cada variável foi coletada. Ao pedirmos para visualizarmos o objeto, percebemos que ele é um tibble.
A importação foi realizada de maneira correta?
Avaliem a variável Peso e Estatura no arquivo original. O que tem de diferente dos valores apresentados na tela do R?
Suponham que o responsável pela digitação dos dados nos informou que ele utilizou o código 9 como dado faltante.
Isso significa que precisamos modificar alguns argumentos da função para que a mesma possa realizar a importação de forma adequada, considerando o 9 como dado faltante e a “,” como decimal.
#Visualizando os argumentos da função locale
args(locale)function (date_names = "en", date_format = "%AD", time_format = "%AT",
decimal_mark = ".", grouping_mark = ",", tz = "UTC", encoding = "UTF-8",
asciify = FALSE)
NULLFazendo as modificações necessárias.
#Importando o arquivo Base saude.txt
base_saude = read_delim(file = "Base saude.txt", #indicando o arquivo a ser importado
na = "9", #informando o código usado para dado faltante
locale = locale(decimal_mark = ",")) #informando que o decimal é uma vírgulaRows: 200 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (2): Codigo, Datacol
dbl (8): Sexo, Idade, Peso, Estatura, HIV, Escol, DST, Tipo
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_saude# A tibble: 200 × 10
Codigo Datacol Sexo Idade Peso Estatura HIV Escol DST Tipo
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AB01 14/10/15 1 20 61.2 1.6 1 3 1 2
2 AB02 09/02/16 0 30 60 1.55 0 5 0 NA
3 AB03 01/03/10 0 50 80 1.83 1 2 1 3
4 AB04 04/05/13 0 43 83 1.9 1 NA 1 2
5 AB05 20/05/14 0 22 75.3 1.75 0 2 1 3
6 AB06 30/01/11 1 15 70.2 1.7 1 6 0 NA
7 AB07 05/08/15 1 22 60 1.65 1 5 1 3
8 AB08 08/12/13 1 25 62 1.55 0 1 0 2
9 AB09 03/11/10 1 32 61 1.62 1 4 1 1
10 AB10 10/10/10 1 33 55 1.55 1 5 1 NA
# ℹ 190 more rowsA forma com que o pacote enxergou cada variável (character, double, integer, factor) nas importações realizadas anteriormente não foram especificados pelo usuário. O pacote faz alguns testes em função dos valores observados para cada variável e define o que parece mais apropriado. Entretanto, é possível que o usuário defina o tipo da variável na importação.
Suponha que o nosso interesse seja que a variável Sexo seja um character que assume os valores 0 e 1. Podemos fazer essa definição na importação da base usando o argumento col_types.
#Importando o arquivo Base saude.txt
base_saude = read_delim(file = "Base saude.txt", #indicando o arquivo a ser importado
na = "9", #informando o código usado para dado faltante
locale = locale(decimal_mark = ","), #informando que o decimal é uma vírgula
col_types = cols(Sexo = col_character())) #informandfo que a variável Sexo deve ser importada como um character#Visualizando o objeto
base_saude# A tibble: 200 × 10
Codigo Datacol Sexo Idade Peso Estatura HIV Escol DST Tipo
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AB01 14/10/15 1 20 61.2 1.6 1 3 1 2
2 AB02 09/02/16 0 30 60 1.55 0 5 0 NA
3 AB03 01/03/10 0 50 80 1.83 1 2 1 3
4 AB04 04/05/13 0 43 83 1.9 1 NA 1 2
5 AB05 20/05/14 0 22 75.3 1.75 0 2 1 3
6 AB06 30/01/11 1 15 70.2 1.7 1 6 0 NA
7 AB07 05/08/15 1 22 60 1.65 1 5 1 3
8 AB08 08/12/13 1 25 62 1.55 0 1 0 2
9 AB09 03/11/10 1 32 61 1.62 1 4 1 1
10 AB10 10/10/10 1 33 55 1.55 1 5 1 NA
# ℹ 190 more rowsAtividade: Agora importem o arquivo Base saude modificada.txt (suponham que ele possui as mesmas características do arquivo base saude.txt) e guardem em um objeto chamado base_saude2.
Rows: 7 Columns: 1
── Column specification ────────────────────────────────────────────────────────
Delimiter: " "
chr (1): CodigotDaTaColetSexotIdadetPesotEsTaTuratHIVtEscoltDSTtTipo
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_saude2# A tibble: 7 × 1
CodigotDaTaColetSexotIdadetPesotEsTaTuratHIVtEscoltDSTtTipo
<chr>
1 AB01t14/10/15t1t20t61,2t1,6t1t3t1t2
2 AB02t09/02/16t0t30t60t1,55t0t5t0t9
3 AB03t01/03/10t0t50t80t1,83t1t2t1t3
4 AB04t04/05/13t0t43t83t1,9t1t9t1t2
5 AB05t20/05/14t0t22t75,3t1,75t0t2t1t3
6 AB06t30/01/11t1t15t70,2t1,7t1t6t0t9
7 AB07t05/08/15t1t22t60t1,65t1t5t1t3 Obviamente problemático, mas como resolvemos isso? Com a função read_delim! Reparem que o separador utilizado na base modificada é a letra t, a função read_delim recebe um argumento delim, ou seja, o delimitador entre as células.
#Importando o arquivo Base saude.txt
base_saude3 = read_delim(file = "Base saude modificada.txt", #indicando o arquivo a ser importado
na = "9", #informando o código usado para dado faltante
locale = locale(decimal_mark = ","), #informando que o decimal é uma vírgula
delim = "t") #informando que o delimitador é o tRows: 7 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: "t"
chr (2): Codigo, DaTaCole
dbl (8): Sexo, Idade, Peso, EsTaTura, HIV, Escol, DST, Tipo
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_saude3# A tibble: 7 × 10
Codigo DaTaCole Sexo Idade Peso EsTaTura HIV Escol DST Tipo
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AB01 14/10/15 1 20 61.2 1.6 1 3 1 2
2 AB02 09/02/16 0 30 60 1.55 0 5 0 NA
3 AB03 01/03/10 0 50 80 1.83 1 2 1 3
4 AB04 04/05/13 0 43 83 1.9 1 NA 1 2
5 AB05 20/05/14 0 22 75.3 1.75 0 2 1 3
6 AB06 30/01/11 1 15 70.2 1.7 1 6 0 NA
7 AB07 05/08/15 1 22 60 1.65 1 5 1 3Se o nosso interesse é importar arquivos com extensão .csv, podemos usar a função read_delim, mas existem opções melhores, pois não nos preocuparemos em definir o delimitador.
As funções read_csv e read_csv2 leem dados em arquivos .csv.
CSV (comma separeted values)
Principais argumentos da função read_csv2:
file - o arquivo a ser importado;
col_names - um argumento lógico indicando se o arquivo possui ou não os nomes das variáveis (default = TRUE);
na - qual a codificação usada para dado faltante (default =c(““, NA));
skip - número de linhas a serem puladas no momento da importação (default = 0);
locale - controla vários aspectos como decimal, enconding, entre outros.
#Fazendo a leitura do arquivo Base saude.csv
base_saude4 = read_csv2(file = "Base saude.csv",
na = '9')ℹ Using "','" as decimal and "'.'" as grouping mark. Use `read_delim()` for more control.Rows: 200 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: ";"
chr (2): Codigo, Datacol
dbl (8): Sexo, Idade, Peso, Estatura, HIV, Escol, DST, Tipo
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_saude4# A tibble: 200 × 10
Codigo Datacol Sexo Idade Peso Estatura HIV Escol DST Tipo
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AB01 14/10/15 1 20 61.2 1.6 1 3 1 2
2 AB02 09/02/16 0 30 60 1.55 0 5 0 NA
3 AB03 01/03/10 0 50 80 1.83 1 2 1 3
4 AB04 04/05/13 0 43 83 1.9 1 NA 1 2
5 AB05 20/05/14 0 22 75.3 1.75 0 2 1 3
6 AB06 30/01/11 1 15 70.2 1.7 1 6 0 NA
7 AB07 05/08/15 1 22 60 1.65 1 5 1 3
8 AB08 08/12/13 1 25 62 1.55 0 1 0 2
9 AB09 03/11/10 1 32 61 1.62 1 4 1 1
10 AB10 10/10/10 1 33 55 1.55 1 5 1 NA
# ℹ 190 more rows
A função read_excel importa dados em arquivos .xls e .xlsx.
Principais argumentos da função read_excel:
- path - o arquivo a ser importado;
- sheet - a planilha a ser importada;
- col_names - um argumento lógico indicando se o arquivo possui ou não os nomes das variáveis (default = TRUE);
- skip - número de linhas a serem puladas no momento da importação (default = 0);
- na - qual a codificação usada para dado faltante (default = NA).
#Ativando o pacote readxl
library(readxl)
#Fazendo a leitura do arquivo Base saude.xlsx
base_saude5 = read_excel(path = "Base saude.xlsx",
sheet = 1,
na = "9")#Visualizando o objeto
base_saude5# A tibble: 200 × 10
Codigo Datacol Sexo Idade Peso Estatura HIV Escol DST Tipo
<chr> <dttm> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AB01 2015-10-14 00:00:00 1 20 61.2 1.6 1 3 1 2
2 AB02 2016-02-09 00:00:00 0 30 60 1.55 0 5 0 9
3 AB03 2010-03-01 00:00:00 0 50 80 1.83 1 2 1 3
4 AB04 2013-05-04 00:00:00 0 43 83 1.9 1 9 1 2
5 AB05 2014-05-20 00:00:00 0 22 75.3 1.75 0 2 1 3
6 AB06 2011-01-30 00:00:00 1 15 70.2 1.7 1 6 0 9
7 AB07 2015-08-05 00:00:00 1 22 60 1.65 1 5 1 3
8 AB08 2013-12-08 00:00:00 1 25 62 1.55 0 1 0 2
9 AB09 2010-11-03 00:00:00 1 32 61 1.62 1 4 1 1
10 AB10 2010-10-10 00:00:00 1 33 55 1.55 1 5 1 9
# ℹ 190 more rowsO Pacote haven possui funções que permitem importar arquivos de diversos outros softwares estatísticos com extensões .dta, .sav, .sas7bdat, etc.
Outro aspecto importante antes de realizarmos a visualização de dados é o processo de limpeza/organização/manipulação de seus dados. Esta tarefa pode ser a parte mais demorada de qualquer análise de dados. Consideraremos a seguir, algumas etapas importantes. Embora existam muitas abordagens, aquelas que usam os pacotes dplyr e tidyr estão entre as mais rápidas e fáceis de aprender.

A seguir serão apresentadas o uso das funções citadas acima utilizando o arquivo basePNUD.csv.
Atividade: Importe o arquivo PNUD.csv e guarde em um objeto chamado basePNUD.
Rows: 16694 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): muni, uf, regiao
dbl (11): ano, idhm, idhm_e, idhm_l, idhm_r, espvida, rdpc, gini, pop, lat, lon
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
basePNUD# A tibble: 16,694 × 14
ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1991 ALTA… RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835
2 1991 ARIQ… RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57 55018
3 1991 CABI… RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846
4 1991 CACO… RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534
5 1991 CERE… RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030
6 1991 COLO… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070
7 1991 CORU… RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59 10737
8 1991 COST… RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65 6902
9 1991 ESPI… RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63 22505
10 1991 GUAJ… RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6 31240
# ℹ 16,684 more rows
# ℹ 2 more variables: lat <dbl>, lon <dbl>selectEsta função seleciona coluna (variáveis).
É possível fazer essa seleção utilizando nomes, índices, intervalos de variáveis ou utilizar as funções starts_with(x), ends_with, contains(x), matches(x), one_of(x) para selecionar subconjunto de variáveis de forma esperta.
#Ativando o pacote
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, union#Selecionando todas as variáveis entre ano e região e a variável rdpc
basePNUD |>
select(ano:regiao,rdpc)# A tibble: 16,694 × 5
ano muni uf regiao rdpc
<dbl> <chr> <chr> <chr> <dbl>
1 1991 ALTA FLORESTA D'OESTE RO Norte 198.
2 1991 ARIQUEMES RO Norte 319.
3 1991 CABIXI RO Norte 116.
4 1991 CACOAL RO Norte 320.
5 1991 CEREJEIRAS RO Norte 240.
6 1991 COLORADO DO OESTE RO Norte 225.
7 1991 CORUMBIARA RO Norte 81.4
8 1991 COSTA MARQUES RO Norte 250.
9 1991 ESPIGÃO D'OESTE RO Norte 263.
10 1991 GUAJARÁ-MIRIM RO Norte 391.
# ℹ 16,684 more rows#Selecionando todas as variáveis com excessão de rdpc e regiao
basePNUD |>
select(-c(regiao, rdpc))# A tibble: 16,694 × 12
ano muni uf idhm idhm_e idhm_l idhm_r espvida gini pop lat lon
<dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1991 ALTA… RO 0.329 0.112 0.617 0.516 62.0 0.63 22835 -11.9 -62.0
2 1991 ARIQ… RO 0.432 0.199 0.684 0.593 66.0 0.57 55018 -9.91 -63.0
3 1991 CABI… RO 0.309 0.108 0.636 0.43 63.2 0.7 5846 -13.5 -60.5
4 1991 CACO… RO 0.407 0.171 0.667 0.593 65.0 0.66 66534 -11.4 -61.4
5 1991 CERE… RO 0.386 0.167 0.629 0.547 62.7 0.6 19030 -13.2 -60.8
6 1991 COLO… RO 0.376 0.151 0.658 0.536 64.5 0.62 25070 -13.1 -60.5
7 1991 CORU… RO 0.203 0.039 0.572 0.373 59.3 0.59 10737 -13.0 -60.9
8 1991 COST… RO 0.425 0.22 0.629 0.553 62.8 0.65 6902 -12.4 -64.2
9 1991 ESPI… RO 0.388 0.159 0.653 0.561 64.2 0.63 22505 -11.5 -61.0
10 1991 GUAJ… RO 0.468 0.247 0.662 0.625 64.7 0.6 31240 -10.8 -65.3
# ℹ 16,684 more rows#Selecionando a variável ano e todas as variáveis que comecem com idhm e salvando no objeto baseIDH
baseIDH = basePNUD |>
select(ano, starts_with('idhm'))
baseIDH# A tibble: 16,694 × 5
ano idhm idhm_e idhm_l idhm_r
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1991 0.329 0.112 0.617 0.516
2 1991 0.432 0.199 0.684 0.593
3 1991 0.309 0.108 0.636 0.43
4 1991 0.407 0.171 0.667 0.593
5 1991 0.386 0.167 0.629 0.547
6 1991 0.376 0.151 0.658 0.536
7 1991 0.203 0.039 0.572 0.373
8 1991 0.425 0.22 0.629 0.553
9 1991 0.388 0.159 0.653 0.561
10 1991 0.468 0.247 0.662 0.625
# ℹ 16,684 more rows#É possível ordenar as variáveis na base com a função select
basePNUD |>
select(muni, ano, everything())# A tibble: 16,694 × 14
muni ano uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
<chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ALTA… 1991 RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835
2 ARIQ… 1991 RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57 55018
3 CABI… 1991 RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846
4 CACO… 1991 RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534
5 CERE… 1991 RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030
6 COLO… 1991 RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070
7 CORU… 1991 RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59 10737
8 COST… 1991 RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65 6902
9 ESPI… 1991 RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63 22505
10 GUAJ… 1991 RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6 31240
# ℹ 16,684 more rows
# ℹ 2 more variables: lat <dbl>, lon <dbl>A função select também serve para ordenar as variáveis na base, uma vez que ela monta a nova base em função do ordenamento das variáveis selecionadas. Aqui a função everything usada em select permite com que não seja digitada o nome das demais variáveis. Deste modo, o comando acima, serviu para fazer com que as variáveis muni e ano fossem as primeiras variáveis da base e em seguida as demais viesem na ordem que já se encontravam.
filterEssa função serve para filtrar linhas (selecionar linhas segundo algum critério).
#Selecionando somente as linhas do estado do CE
basePNUD |>
filter(uf == 'CE')# A tibble: 552 × 14
ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1991 ABAI… CE Norde… 0.286 0.103 0.6 0.377 61 83.3 0.44 7826
2 1991 ACAR… CE Norde… 0.349 0.179 0.537 0.443 57.2 126. 0.45 11155
3 1991 ACAR… CE Norde… 0.277 0.089 0.534 0.449 57.0 131. 0.51 44505
4 1991 ACOP… CE Norde… 0.254 0.077 0.514 0.413 55.8 104. 0.58 48912
5 1991 AIUA… CE Norde… 0.256 0.081 0.574 0.36 59.4 75.0 0.62 13125
6 1991 ALCÂ… CE Norde… 0.285 0.122 0.49 0.386 54.4 88.5 0.47 8551
7 1991 ALTA… CE Norde… 0.288 0.122 0.512 0.381 55.7 85.9 0.62 4658
8 1991 ALTO… CE Norde… 0.304 0.097 0.661 0.438 64.7 122. 0.48 12748
9 1991 AMON… CE Norde… 0.241 0.062 0.619 0.366 62.2 77.9 0.5 24910
10 1991 ANTO… CE Norde… 0.309 0.129 0.561 0.409 58.7 102. 0.55 4988
# ℹ 542 more rows
# ℹ 2 more variables: lat <dbl>, lon <dbl>#Selecionando as variáveis ano, região, uf e idhm e em seguida filtrando as linhas que são dos estados do CE ou RJ no ano de 2010.
basePNUD |>
select(ano,regiao,uf,idhm) |>
filter(uf %in% c('CE', 'RJ') , ano == 2010)# A tibble: 275 × 4
ano regiao uf idhm
<dbl> <chr> <chr> <dbl>
1 2010 Nordeste CE 0.628
2 2010 Nordeste CE 0.606
3 2010 Nordeste CE 0.601
4 2010 Nordeste CE 0.595
5 2010 Nordeste CE 0.569
6 2010 Nordeste CE 0.6
7 2010 Nordeste CE 0.602
8 2010 Nordeste CE 0.601
9 2010 Nordeste CE 0.606
10 2010 Nordeste CE 0.599
# ℹ 265 more rowsPercebemos que no resultado final foram apresentadas somente as variáveis selecionadas e as linhas que satisfaziam a condição especificada: ser um município do estado do RJ ou CE no ano de 2010.
mutateFunção que permite criar/modificar variáveis na base de dados existente.
#Selecionando as variáveis muni, rdpc, pop, idhm_l e espvida e em seguida criando as variáveis renda, razao e renda2
basePNUD |>
select(muni,rdpc,pop,idhm_l,espvida) |>
mutate(renda = rdpc * pop,
razao = idhm_l / espvida,
renda2 = renda/razao)# A tibble: 16,694 × 8
muni rdpc pop idhm_l espvida renda razao renda2
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ALTA FLORESTA D'OESTE 198. 22835 0.617 62.0 4531834. 0.00995 4.55e8
2 ARIQUEMES 319. 55018 0.684 66.0 17576600. 0.0104 1.70e9
3 CABIXI 116. 5846 0.636 63.2 680357. 0.0101 6.76e7
4 CACOAL 320. 66534 0.667 65.0 21306848. 0.0103 2.08e9
5 CEREJEIRAS 240. 19030 0.629 62.7 4569103 0.0100 4.56e8
6 COLORADO DO OESTE 225. 25070 0.658 64.5 5636237. 0.0102 5.52e8
7 CORUMBIARA 81.4 10737 0.572 59.3 873777. 0.00964 9.06e7
8 COSTA MARQUES 250. 6902 0.629 62.8 1726052. 0.0100 1.72e8
9 ESPIGÃO D'OESTE 263. 22505 0.653 64.2 5919490. 0.0102 5.82e8
10 GUAJARÁ-MIRIM 391. 31240 0.662 64.7 12226399. 0.0102 1.20e9
# ℹ 16,684 more rowsA função mutate permite criar novas variáveis na base de dados ao mesmo tempo, inclusive nos permite usar uma das variáveis que estão sendo criadas para criar uma outra nova variável.
group_by e summariseEstas funções são utilizadas, usualemnte, para obter sumários de variáveis da base.
#Calculando o número de municípios por região e a média da espectativa de vida para todas as regiões em todos os anos e ordenando o resultando em ordem decrescente pelo valor da espectativa de vida
basePNUD |>
group_by(ano, regiao) |>
summarise(n = n(),
media_espvida = mean(espvida,
na.rm = TRUE)) |>
arrange(regiao,desc(media_espvida)) |>
ungroup()`summarise()` has grouped output by 'ano'. You can override using the `.groups`
argument.# A tibble: 15 × 4
ano regiao n media_espvida
<dbl> <chr> <int> <dbl>
1 2010 Centro-Oeste 465 74.3
2 2000 Centro-Oeste 465 70.0
3 1991 Centro-Oeste 465 65.1
4 2010 Nordeste 1794 70.3
5 2000 Nordeste 1794 64.2
6 1991 Nordeste 1794 58.5
7 2010 Norte 449 71.8
8 2000 Norte 449 66.4
9 1991 Norte 457 61.6
10 2010 Sudeste 1667 74.7
11 2000 Sudeste 1667 70.8
12 1991 Sudeste 1667 66.6
13 2010 Sul 1187 75.1
14 2000 Sul 1187 71.6
15 1991 Sul 1187 67.9A função n seria equivalente a função length. Pelo resultado final, percebemos que no ano de 2010 existiam 465 municípios na região Centro-oeste e a expectativa de vida média dos municípios era de 74,3 anos.
A função summarise será extremamente útil para calcularmos medidas resumos de interesse para subgrupos da base de dados.
spreadEsta função pertence ao pacote tidyr. A função spread transforma um par de colunas chave:valor em um conjunto de colunas organizadas.
Principais argumentos da função spread:
- data - o data frame que será reorganizado;
- key - o nome da coluna chave (que será transformada em várias colunas);
- value - o nome da coluna que alimentará as colunas que serão criadas a partir da chave.
Atividade: Importe a planilha pop_casos do arquivo Base_pais.xlsx e guarde em um objeto chamado base_pais_1.
#Visualizando o objeto
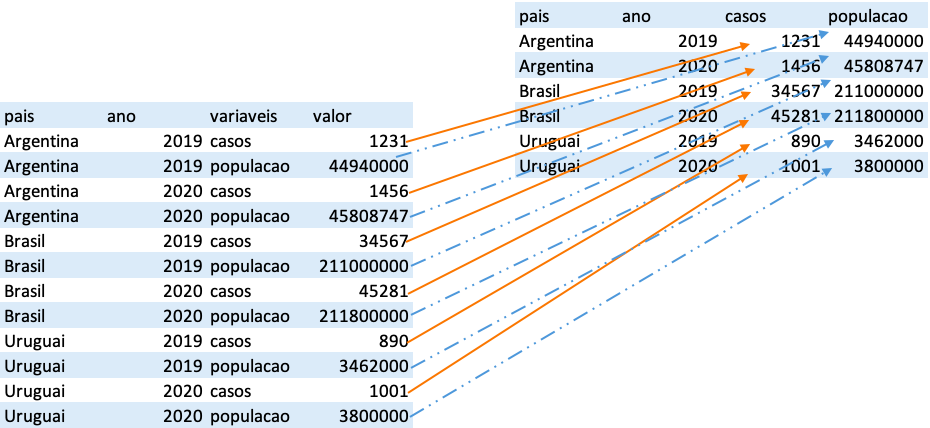
base_pais_1# A tibble: 12 × 4
pais ano variaveis valor
<chr> <dbl> <chr> <dbl>
1 Brasil 2019 casos 34567
2 Brasil 2019 populacao 211000000
3 Brasil 2020 casos 45281
4 Brasil 2020 populacao 211800000
5 Argentina 2019 casos 1231
6 Argentina 2019 populacao 44940000
7 Argentina 2020 casos 1456
8 Argentina 2020 populacao 45808747
9 Uruguai 2019 casos 890
10 Uruguai 2019 populacao 3462000
11 Uruguai 2020 casos 1001
12 Uruguai 2020 populacao 3800000# Ativando o pacote tidyr
library(tidyr)
#Fazendo a leitura do arquivo Base saude.xlsx
base_pais_1_reorg = base_pais_1 |>
spread(key = variaveis,
value = valor)
base_pais_1_reorg# A tibble: 6 × 4
pais ano casos populacao
<chr> <dbl> <dbl> <dbl>
1 Argentina 2019 1231 44940000
2 Argentina 2020 1456 45808747
3 Brasil 2019 34567 211000000
4 Brasil 2020 45281 211800000
5 Uruguai 2019 890 3462000
6 Uruguai 2020 1001 3800000A figura abaixo ilustra a operação que foi realizada.
gatherA função também pertence ao pacote tidyr. A função gather faz o reverso da função spread, isto é, ela armazena um conjunto de colunas em uma coluna chave.
Principais argumentos da função gather:
- data - o data frame que será reorganizado;
- key - o nome que será dado a coluna chave (que armazenará os nomes das colunas das variáveis que serão agrupadas);
- value - o nome da que será dado a coluna na qual ficarão os valores das colunas das variáveis que serão agrupadas.
Atividade: Importe a planilha casos do arquivo Base_pais.xlsx e guarde em um objeto chamado base_pais_2.
#Visualizando o objeto
base_pais_2# A tibble: 3 × 3
pais `2019` `2020`
<chr> <dbl> <dbl>
1 Brasil 34567 45281
2 Argentina 1231 1456
3 Uruguai 890 1001#Reorganizando a base de dados
base_pais_2_reorg = base_pais_2 |>
gather(key = "ano",
value = "casos",
2:3)
base_pais_2_reorg# A tibble: 6 × 3
pais ano casos
<chr> <chr> <dbl>
1 Brasil 2019 34567
2 Argentina 2019 1231
3 Uruguai 2019 890
4 Brasil 2020 45281
5 Argentina 2020 1456
6 Uruguai 2020 1001