Dados faltantes quase sempre estão presentes nos dados que analisamos diariamente. Uma parte primordial da análise de dados é saber avaliar e explorar esses dados nos estágio iniciais. O material a seguir tenta discutir dois aspectos importantes sobre dados faltantes: como começar a olhar para esses dados e como explorar os mecanismos que os geraram.
6.1Como nós começamos a avaliar dados faltantes?
Quando importamos dados, usualmente, fazemos uma avaliação simples e rápida da base, usando funçoes como summary ou str. Estas funções servem, principalmente se o volume de dados disponível é pequeno. Quando lidamos com um volume maior, precisamos de funções que nos permitam avaliar melhor a presença de dados faltantes.
Atividade: Importe o arquivo base_domicilios.csv e armazene-o em um objeto chamado domicilio. Importe a variável matricula como um character.
A base de dados possui variáveis referentes a domicílios de todo o Brasil, contendo variáveis tais como:
código da matrícula do domicílio - todo numérico (matricula);
grande região do domicílio (GR);
número de moradores do domicílio (numero_moradores);
qual o sexo do chefe de família (chefe_famila).
# Visualizando o objetodomicilio
# A tibble: 150,000 × 4
matricula GR numero_moradores chefe_famila
<chr> <chr> <dbl> <chr>
1 366929 Sudeste 2 H
2 926090 Sudeste 3 H
3 278888 Sudeste 3 H
4 745838 Sudeste 9 H
5 517918 Sudeste 2 H
6 403363 Sudeste 4 H
7 716466 Sudeste 2 H
8 162367 Sudeste 3 H
9 664136 Sudeste 5 H
10 314922 Sudeste 2 H
# ℹ 149,990 more rows
6.1.1A função viss_miss
Um dos primeiros gráficos que usaremos para avaliar a presença de dados faltantes é a função viss_miss.
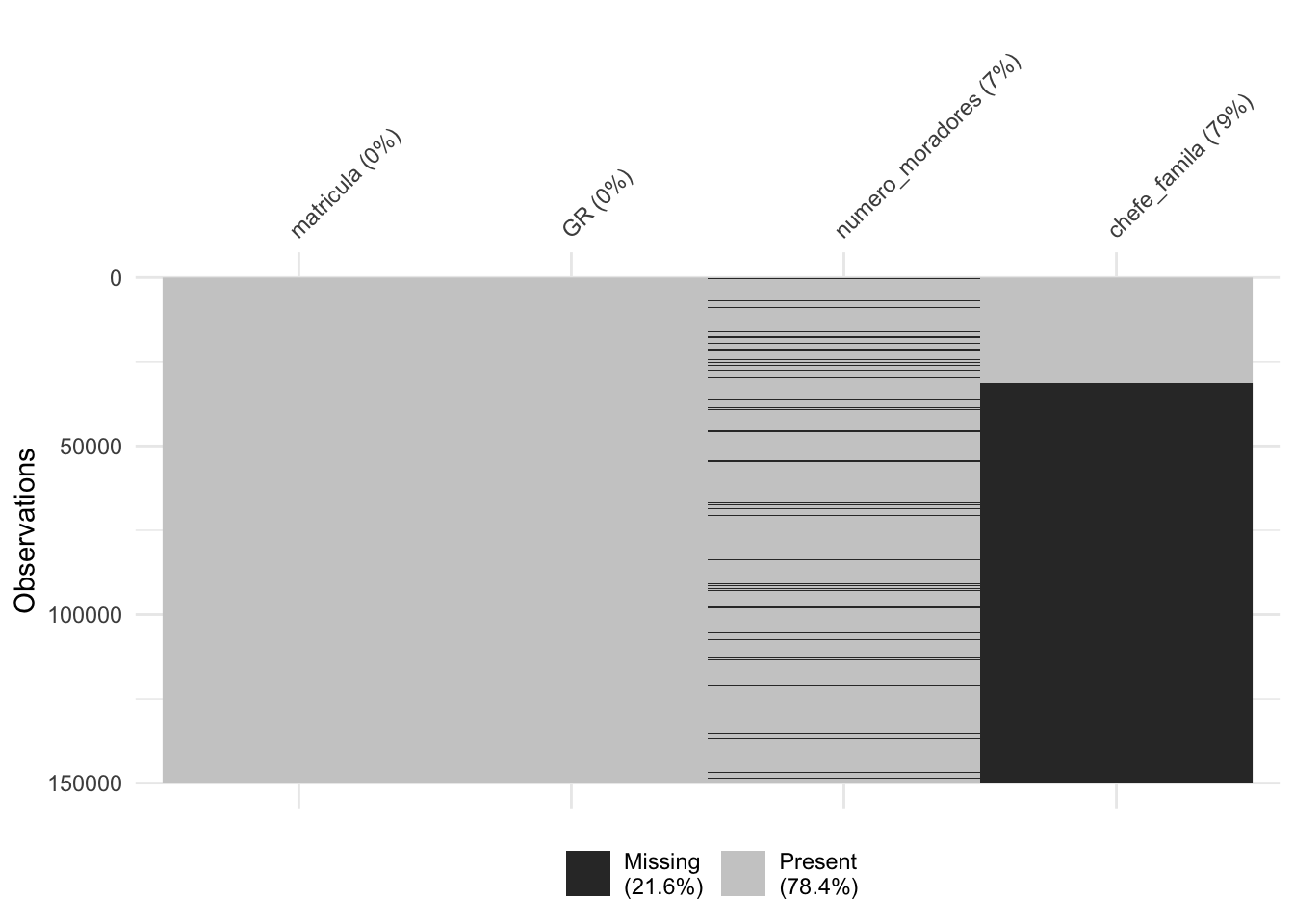
# carregando pacotelibrary(naniar)# uma análise inicial dos dados faltantesvis_miss(domicilio)
O gráfico acima nos fornece uma visualização específica da quantidade de dados faltantes, mostrando em preto a localização dos valores faltantes e também fornecendo informações sobre a porcentagem geral de valores faltantes em geral (apresentado na legenda) e em cada variável.
6.1.2A função gg_miss_var
Uma outra forma de avaliar os dados faltantes, visualmente é por meio da função gg_miss_var.
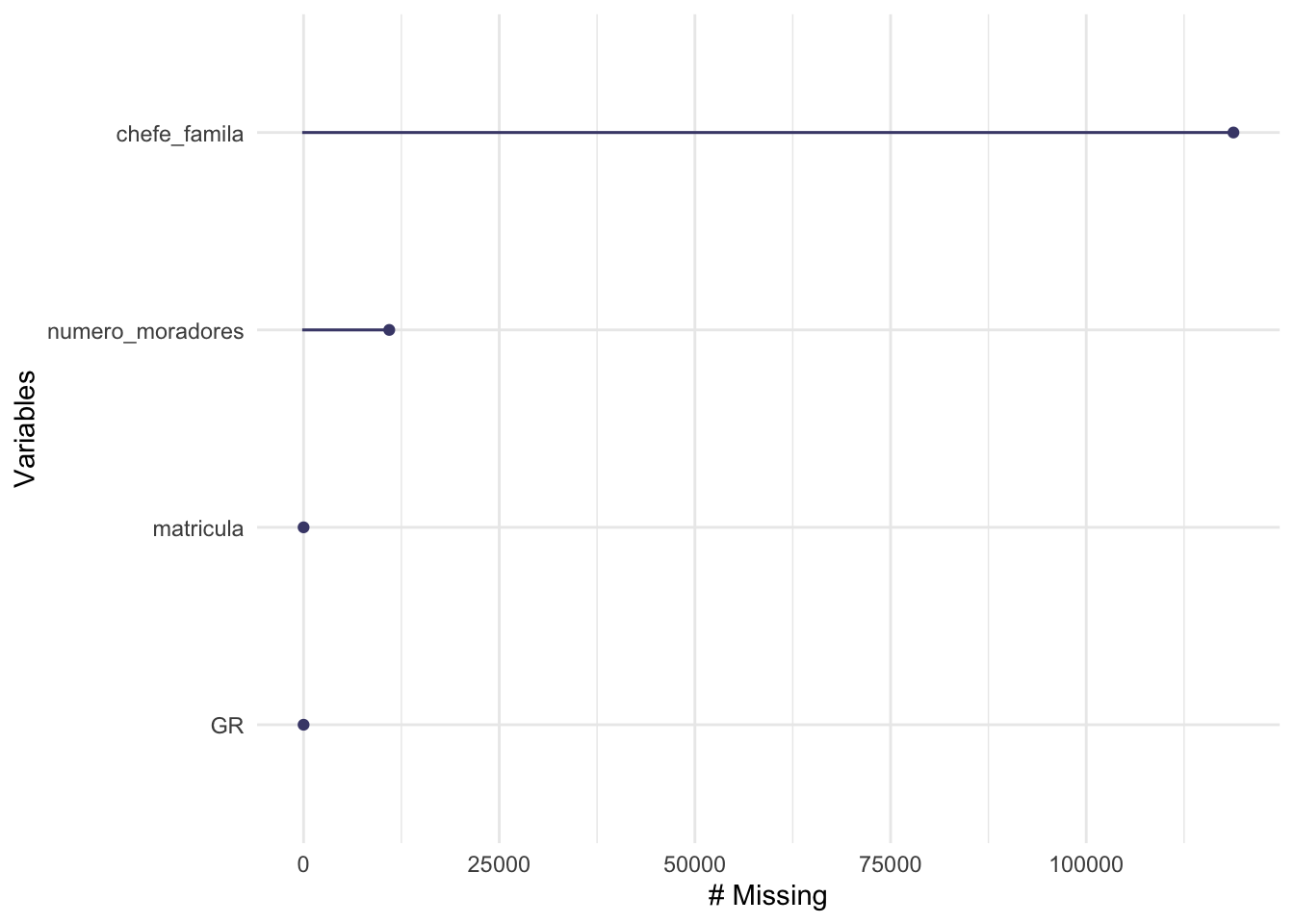
# uma outra visualização para dados faltantesgg_miss_var(domicilio)
É possível avaliar os percentuais por variáveis, usando esta visualização, basta modificarmos o argumento show_pct para TRUE.
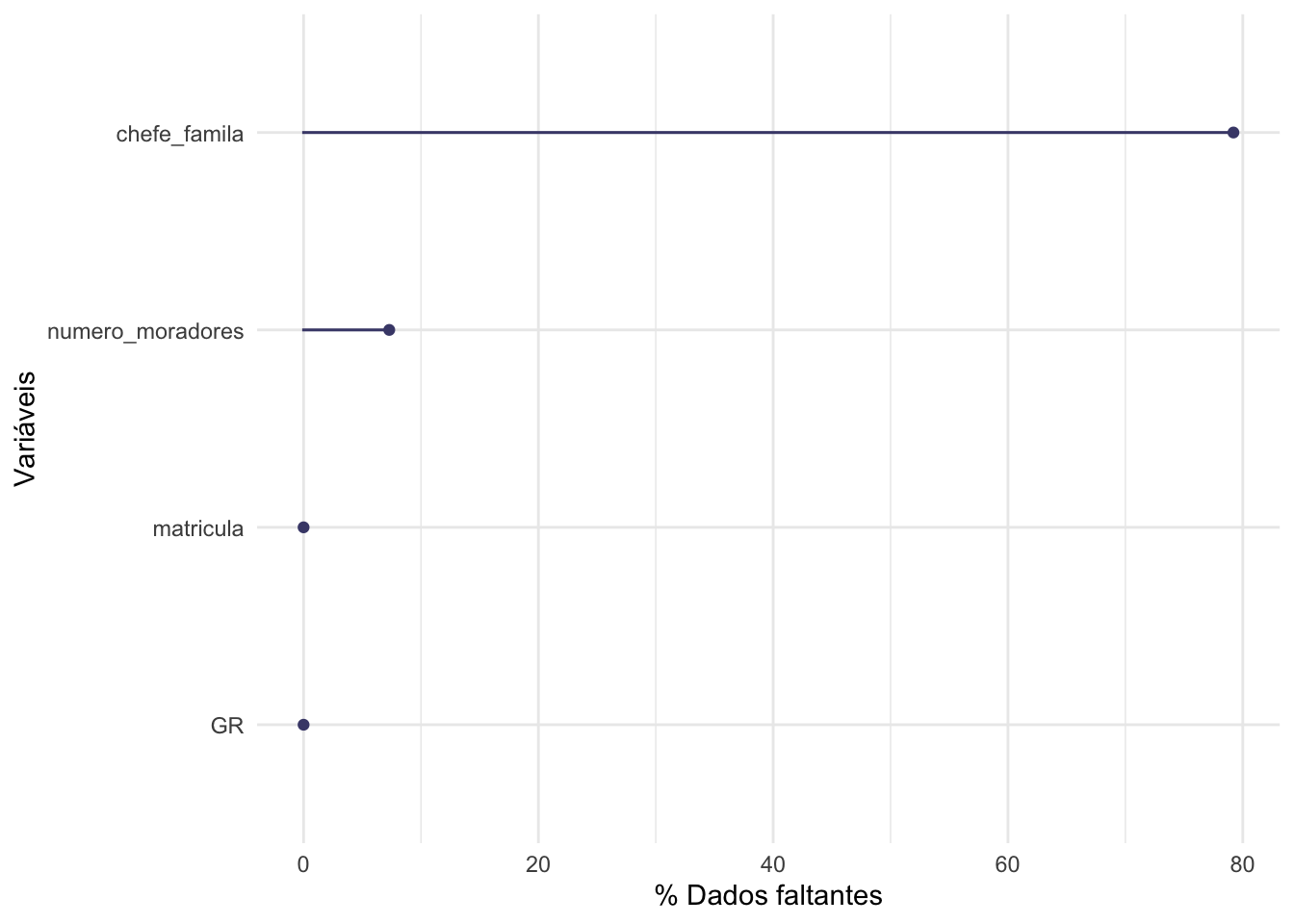
# carregando pacoteslibrary(ggplot2) # esse pacote foi carregado para paermitir usar a função labs# uma outra visualização para dados faltantesgg_miss_var(domicilio,show_pct =TRUE) +labs(x ="Variáveis",y ="% Dados faltantes")
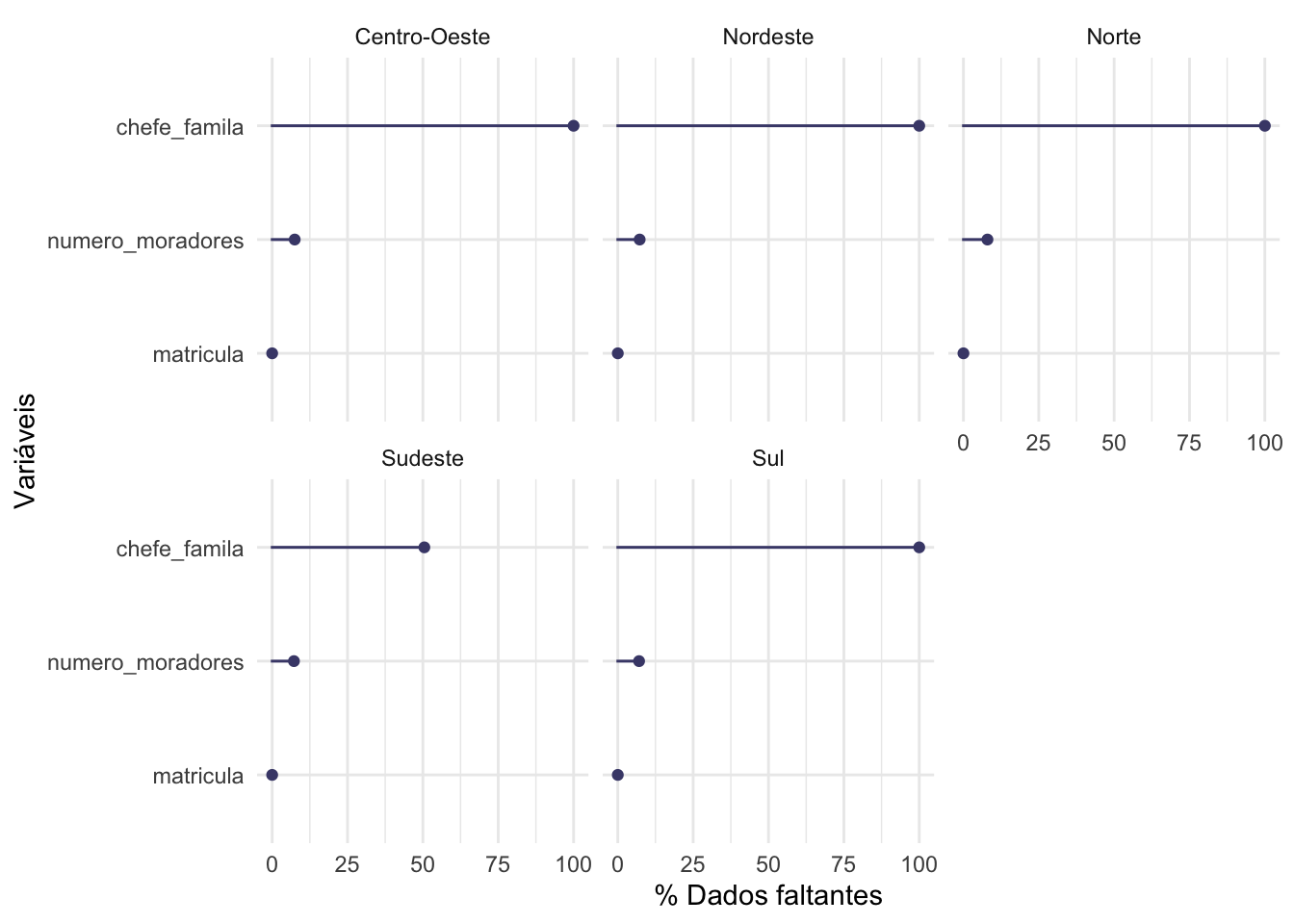
Nós também podemos avaliar os dados faltantes de acordo com as categorias de alguma variável.
# uma outra visualização para dados faltantesgg_miss_var(domicilio,show_pct =TRUE,facet = GR) +labs(x ="Variáveis",y ="% Dados faltantes")
6.2Explorando padrões de dados faltantes
Existem gráfico que nos permitem avaliar padrões de omissão de dados, isto é, possíveis combinações de omissões e interseções de omissões entre as variáveis.
6.2.1A função gg_miss_upset
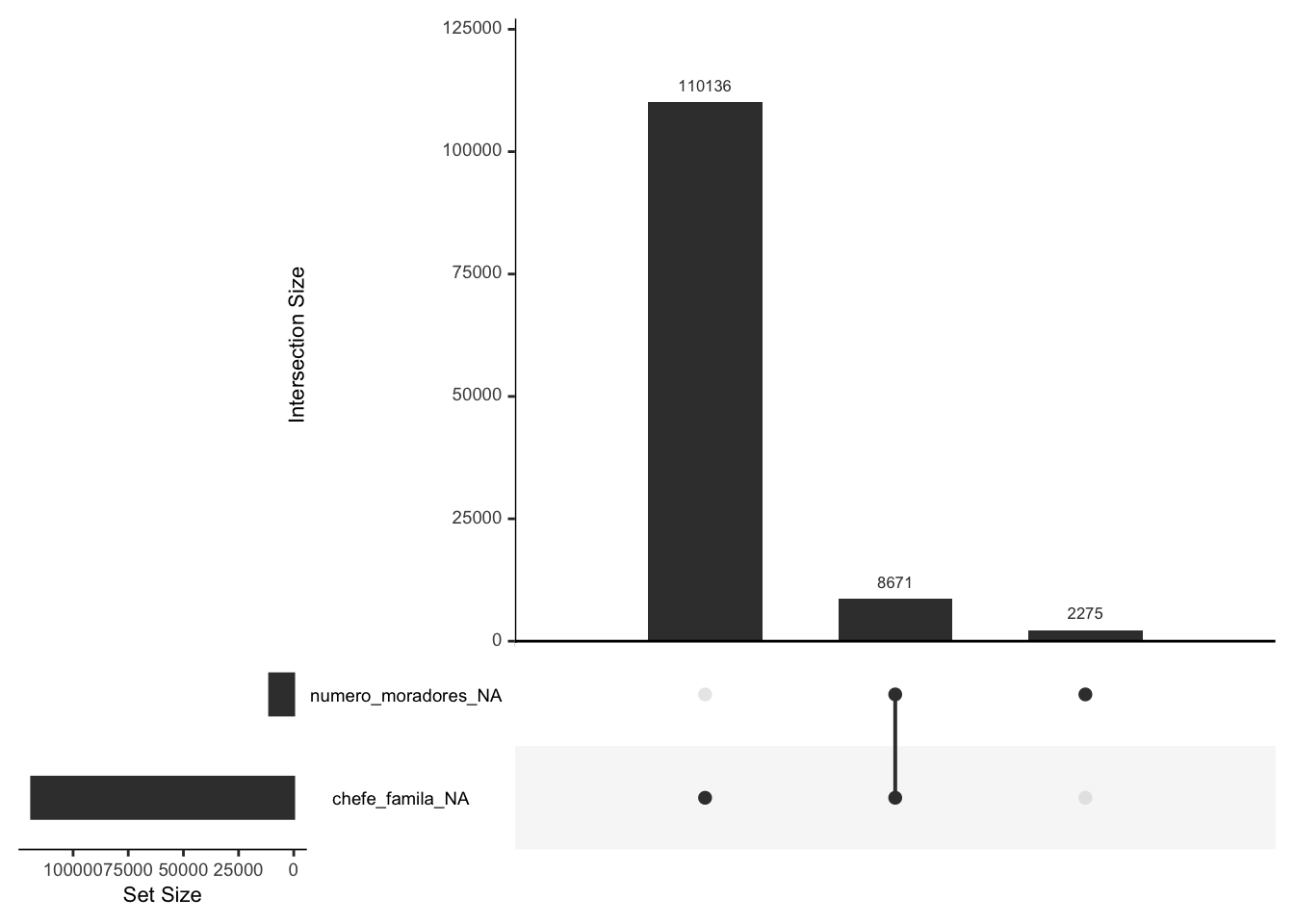
# avaliando interseções de dados faltantes entre variáveisgg_miss_upset(domicilio)
O gráfico nos diz que as variáveis número de moradores e chefe de família possuem dados faltantes. Ainda nos diz que a variável chefe de família é a que mais possui casos de dados faltantes. Além disso, nos diz que 8.671 domicílios possuem dados faltantes para as duas variáveis.
6.3Resumos numéricos para dados faltantes
A seguir, apresentamos duas formas de contabiliozar os dados faltantes.
#Identificando o número de unidades experimentais sem informação por variávelmiss_var_summary(domicilio)