A seguir, abordaremos a execução de uma análise exploratória e modelagem para o conjunto de dados toenail.dta disponível em Rabe-Hesketh and Skronda (2008). Estes dados são referentes a um estudo clínico randomizado duplo-cego para tratamento de infecção de unha (dermatophyte onychomycosis), causada por um fungo. Foram coletadas medidas do grau de deslocamento da unha em \(t = 0, 4, 8, 12, 24, 36, 48\) semanas.
Respota longitudinal: Grau de deslocamento da unha.
Variável resposta é binária (1 = moderada/severa e 0 = nenhuma/leve);
número de pacientes: 378
número de medidas repetidas por paciente (até 7) - dadosdesbalanceados;
Total de observações: 1908.
Grupos: Itraconazole e terbinafine.
2.1 Análise exploratória
Para prosseguir, vamos importar a base de dados (que se encontra no formato long e com extesnão .dta). Para tal, precisamos incluir a base de dados e o script no projeto criado, podemos executar os comandos a seguir.
#Ativando pacoteslibrary(haven)library(dplyr)#Importando o banco toenail.dtabase_unha =read_dta(file ="toenail.dta") #informar o nome do arquivo#Transformando as variáveis treatment e patiente em fatoresbase_unha = base_unha |>mutate(treatment =factor(x = treatment, #nome da variávellevels =c(0,1), #valores observados para a variávellabels =c("Itraconazole","Terbinafine")), #rótulos para os valores observadospatient =factor(patient))#Visualizando o objetobase_unha
Vamos incializar a análise entendendo um pouco mais sobre o nosso banco de dados! Quantas medidas temos por paciente? Qual o número mínimo de medidas observadas? E qual o número máximo?
#Contabilizando o número de visitas por pacientevisitas_paciente = base_unha |>group_by(patient) |>#indicar a variável que identifica o paciente no banco de dadossummarise(num_visitas =n()) |>ungroup() |> dplyr::select(num_visitas) #Ativando o pacotelibrary(janitor)#Tabela de frequências para o número de visitasvisitas_paciente |>tabyl(var1 = num_visitas) |>adorn_totals(where ="row") |>adorn_pct_formatting()
#Calculando medidas descritivas para o núemro de visitas por pacientevisitas_paciente |>summary()
num_visitas
Min. :1.00
1st Qu.:7.00
Median :7.00
Mean :6.49
3rd Qu.:7.00
Max. :7.00
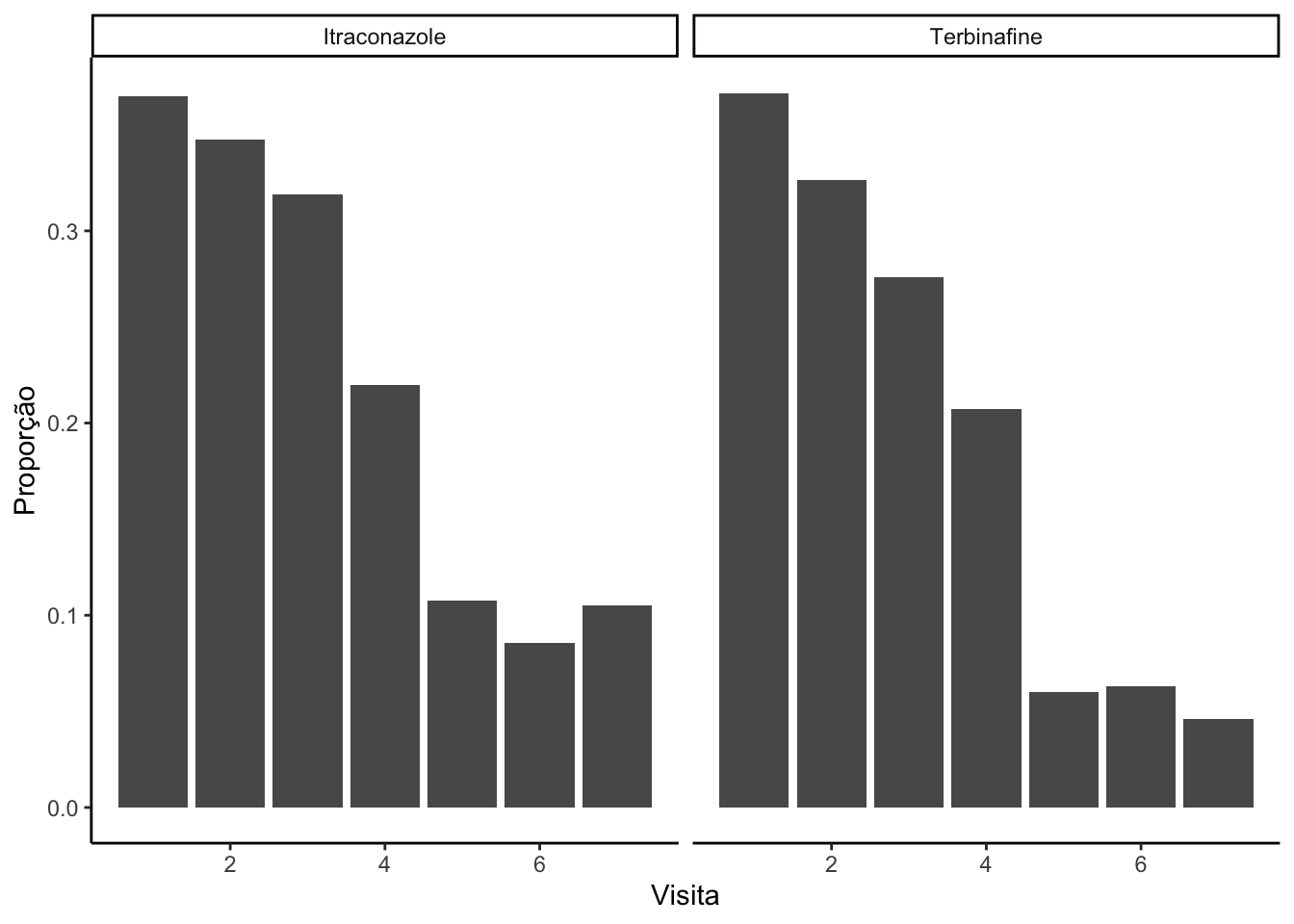
Agora, vamos contabilizar a proporção de casos moderados/severos em cada visita para cada grupo de tratamento e na sequência plotar essas proporções.
#Contabilizando as porporções de casos moderados/severos por visita para cada tratamentoprop_visita = base_unha |>group_by(treatment,visit) |>#indicar as variáveis associadas ao grupo e ao tempo (números inteiros indicando qual a visita)summarise(prop =mean(outcome, na.rm =TRUE)) |>#variável resposta (precisa estar ser binária (0 e 1))ungroup()prop_visita
#Ativando pacotelibrary(ggplot2)#Plotando as proporções contabilizadasprop_visita |>ggplot(mapping =aes(x = visit, #indicar a variável de tempoy = prop)) +geom_bar(stat ="identity") +labs(x ="Visita",y ="Proporção") +theme_classic() +facet_wrap(~treatment)
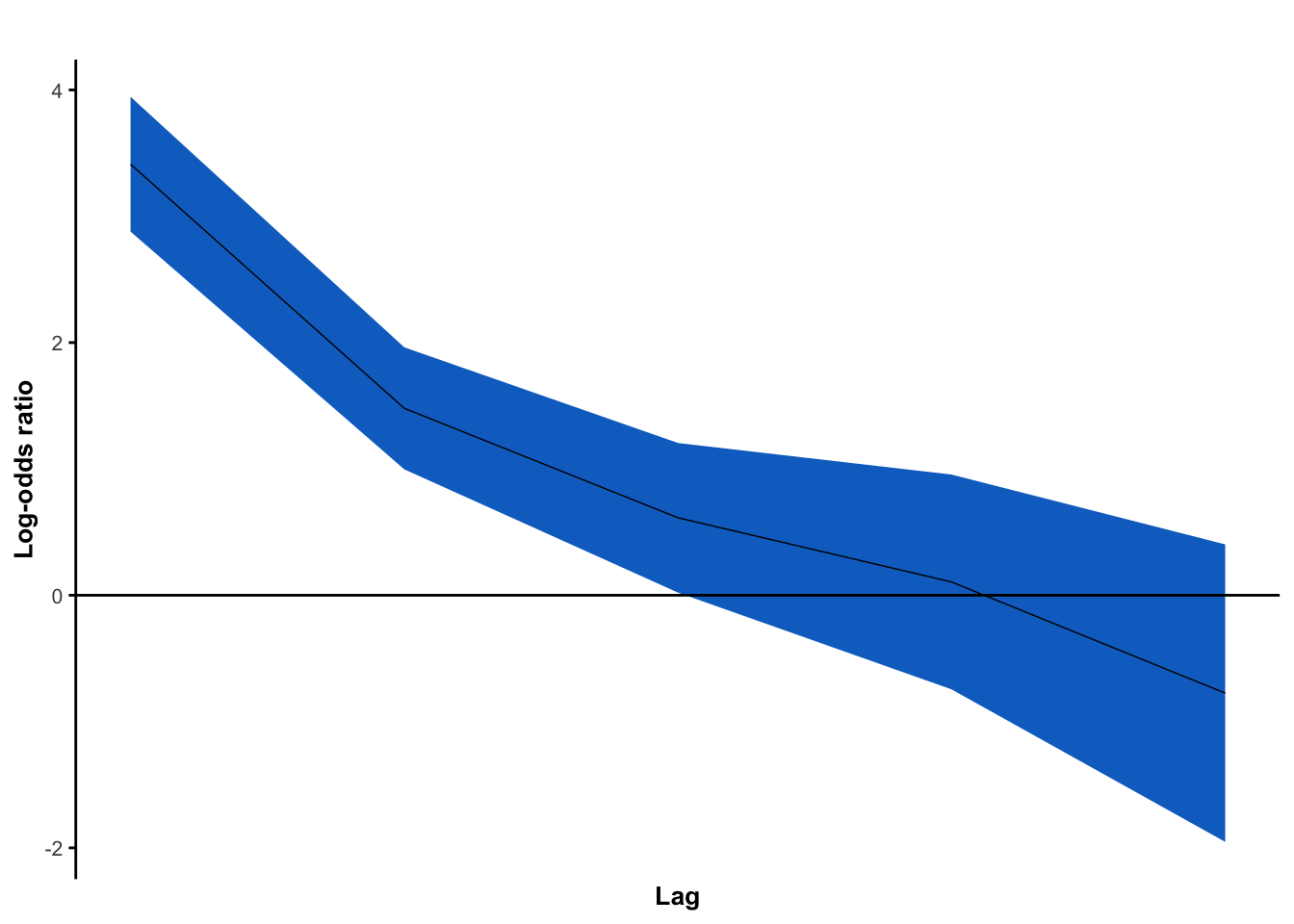
Agora, vamos fazer o lorelograma.
#Selecionando somente as variáveis que indicam o paciente, a visita e a variável respostabase_lorelogram = base_unha |> dplyr::select(patient,visit, outcome) #indique as variáveis que identificam: paciente, tempo e desfecho#Ativando o pacotelibrary(tidyr)library(lorelogram)#Transformando em uma base de dados balanceada base_lorelogram_balan = base_lorelogram |>complete(patient, visit) #indicar as variáveis que identificam: paciente e tempo#Criando o lorelogramalorelogram(data =as.data.frame(base_lorelogram_balan), data_format ="long")
Vamos iniciar construindo um modelo marginal: Equações de Estimação Generalizada (GEE). Para especificar o modelo é preciso defirnir:
a distribuição de probabilidade da variável resposta (família).
a função de ligação.
a estrutura de correlação.
#Ativando pacotelibrary(geepack)#Ajustando o modelo com estrutura de correlação exchangeablegeeEXC =geeglm(formula = outcome ~ treatment + visit, #indicar a variável resposta ~ indicar as variáveis explicativasid = patient, #variável que identifica os pacientesdata = base_unha, family =binomial(link ="logit"), #definição da variável resposta e função de ligaçãocorstr ="exchangeable") #definição da estrutura de correlaçãosummary(geeEXC)
#Ativando pacotelibrary(broom.mixed)#Calculando OR e seus intervalos de confiançatidy(geeEXC,conf.int=TRUE,exponentiate=TRUE) |> dplyr::select(estimate, conf.low, conf.high)
#Ajustando o modelo com estrutura de correlação ar1geeAR1 =geeglm(formula = outcome ~ treatment + visit, #indicar a variável resposta ~ indicar as variáveis explicativasid = patient, #variável que identifica os pacientesdata = base_unha, family =binomial(link ="logit"), #definição da variável resposta e função de ligaçãocorstr ="ar1") #definição da estrutura de correlaçãosummary(geeAR1)
Inicialemnte, vamos ajustar o modelo com interceptos aleatórios.
#Ativando pacotelibrary(lme4)#Ajuste do Modelo Misto com interceptos aleatóriosMML=glmer(formula = outcome ~ treatment + visit + (1| patient), #indicar a variável resposta ~ indicar as variáveis explicativas (1 | variável que identifica o paciente) é a forma de incluir o intercepto aleatóriofamily =binomial(link ="logit"), #definição da variável resposta e função de ligaçãodata = base_unha)summary(MML)
Generalized linear mixed model fit by maximum likelihood (Laplace
Approximation) [glmerMod]
Family: binomial ( logit )
Formula: outcome ~ treatment + visit + (1 | patient)
Data: base_unha
AIC BIC logLik deviance df.resid
1260 1283 -626 1252 1904
Scaled residuals:
Min 1Q Median 3Q Max
-4.951 -0.163 -0.049 -0.011 17.151
Random effects:
Groups Name Variance Std.Dev.
patient (Intercept) 22 4.69
Number of obs: 1908, groups: patient, 294
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.0518 0.7994 -1.32 0.19
treatmentTerbinafine -0.6969 0.6870 -1.01 0.31
visit -0.9115 0.0743 -12.26 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) trtmnT
trtmntTrbnf -0.345
visit 0.221 0.092
#Calculando OR e seus intervalos de confiançatidy(MML,conf.int=TRUE,exponentiate=TRUE,effects="fixed") |> dplyr::select(estimate, conf.low, conf.high)
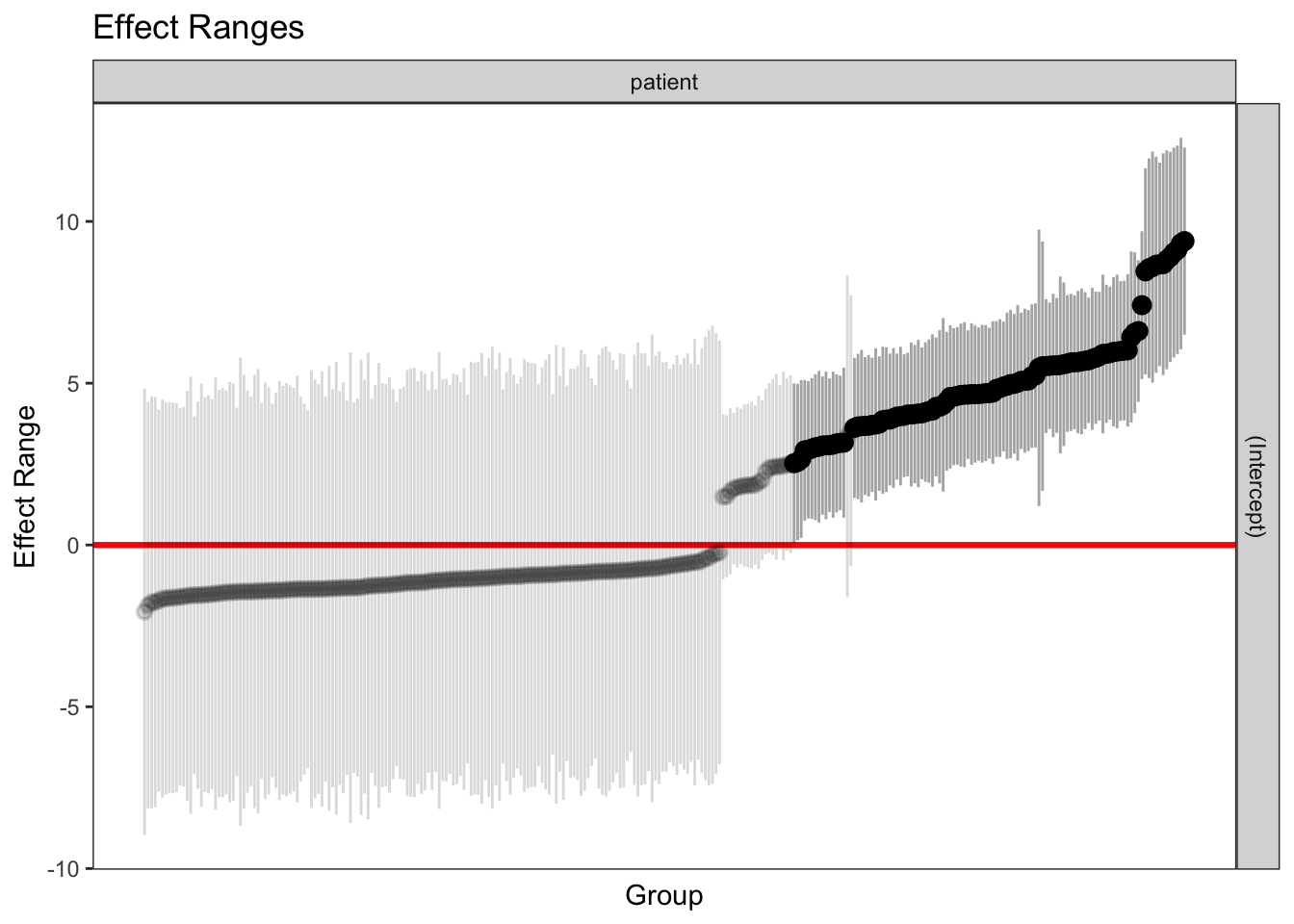
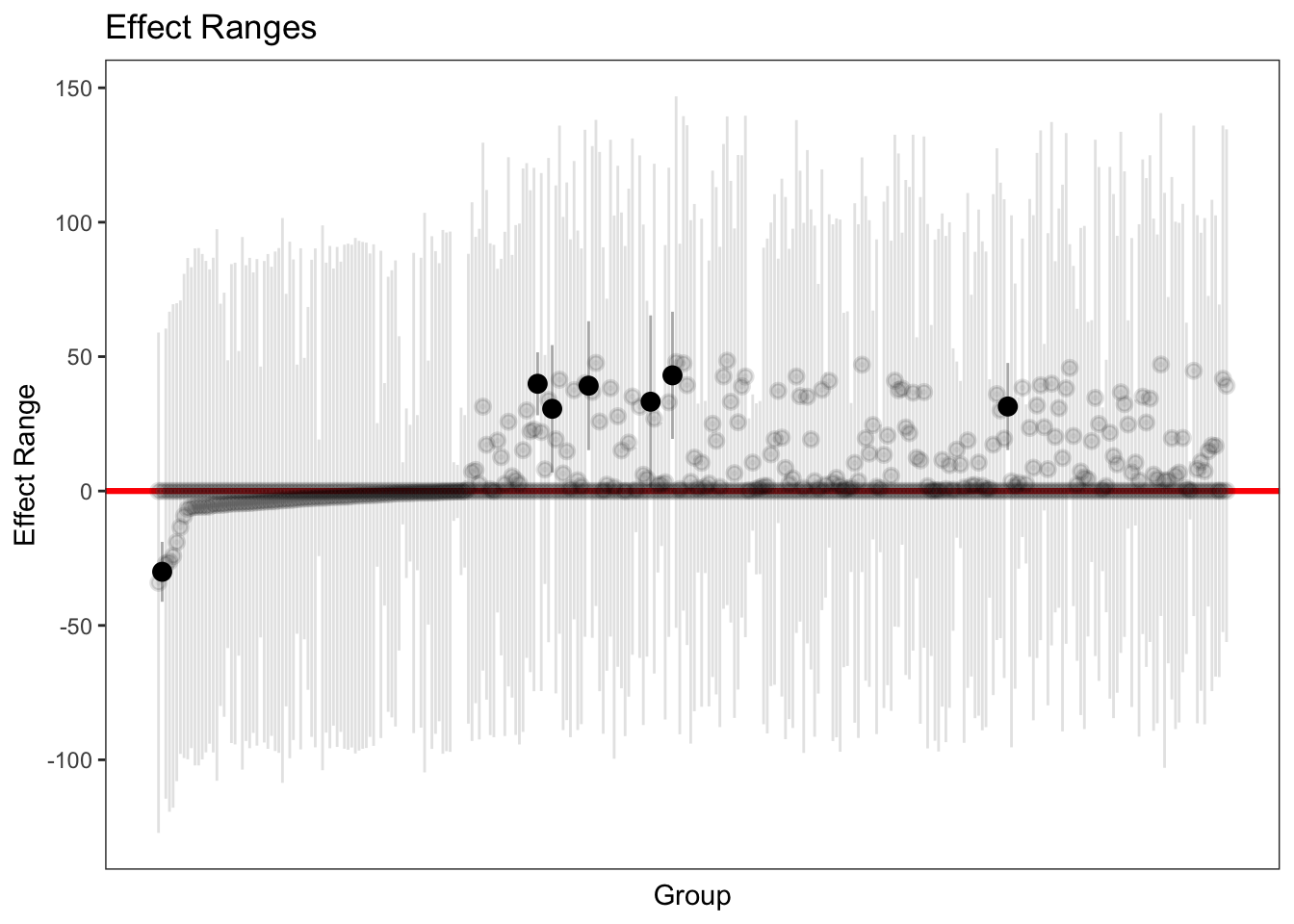
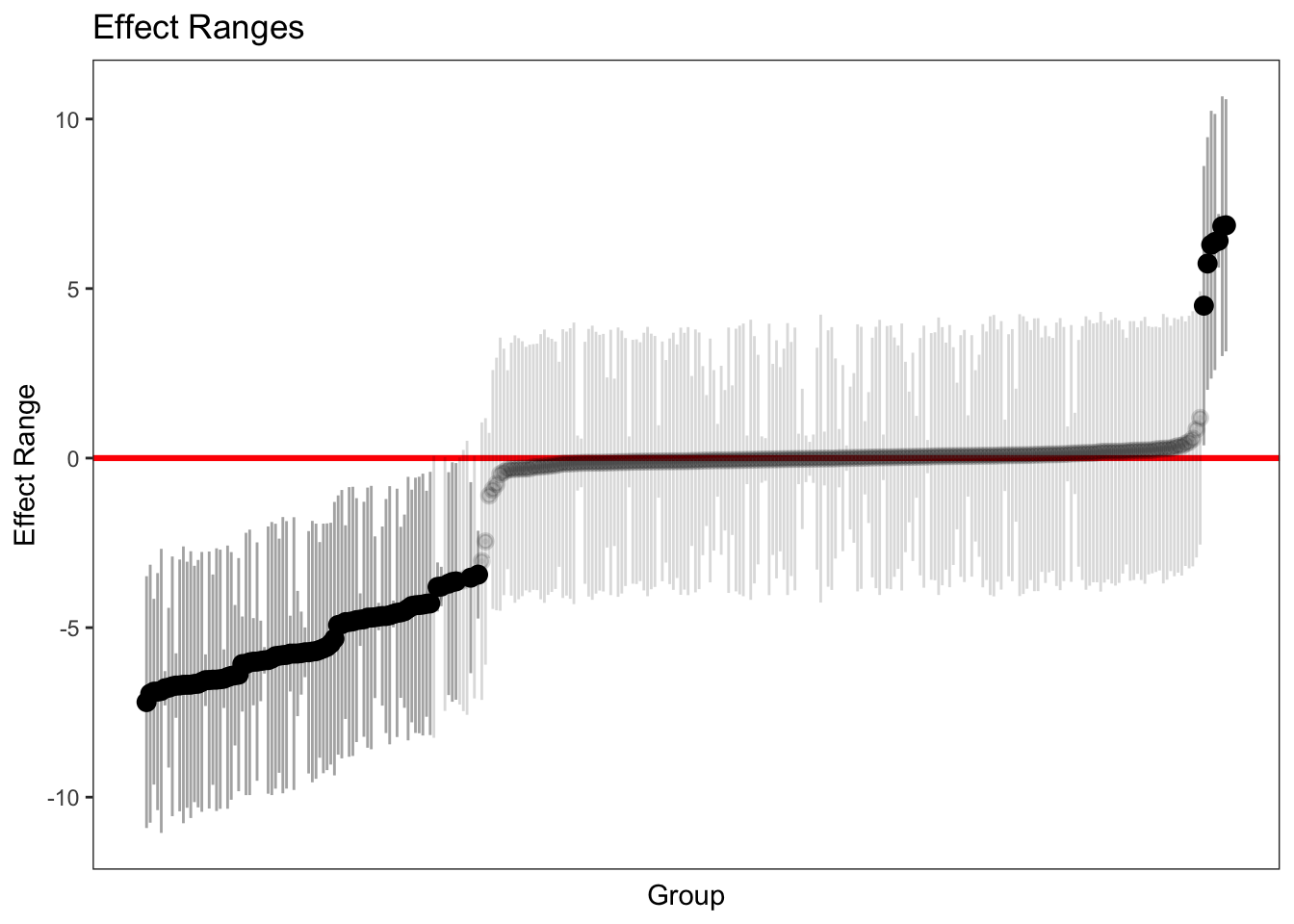
#Ativando pacotelibrary(merTools)#Plotando estimativa pontual e intervalar dos interceptos aleatóriosplotREsim(REsim(MML))
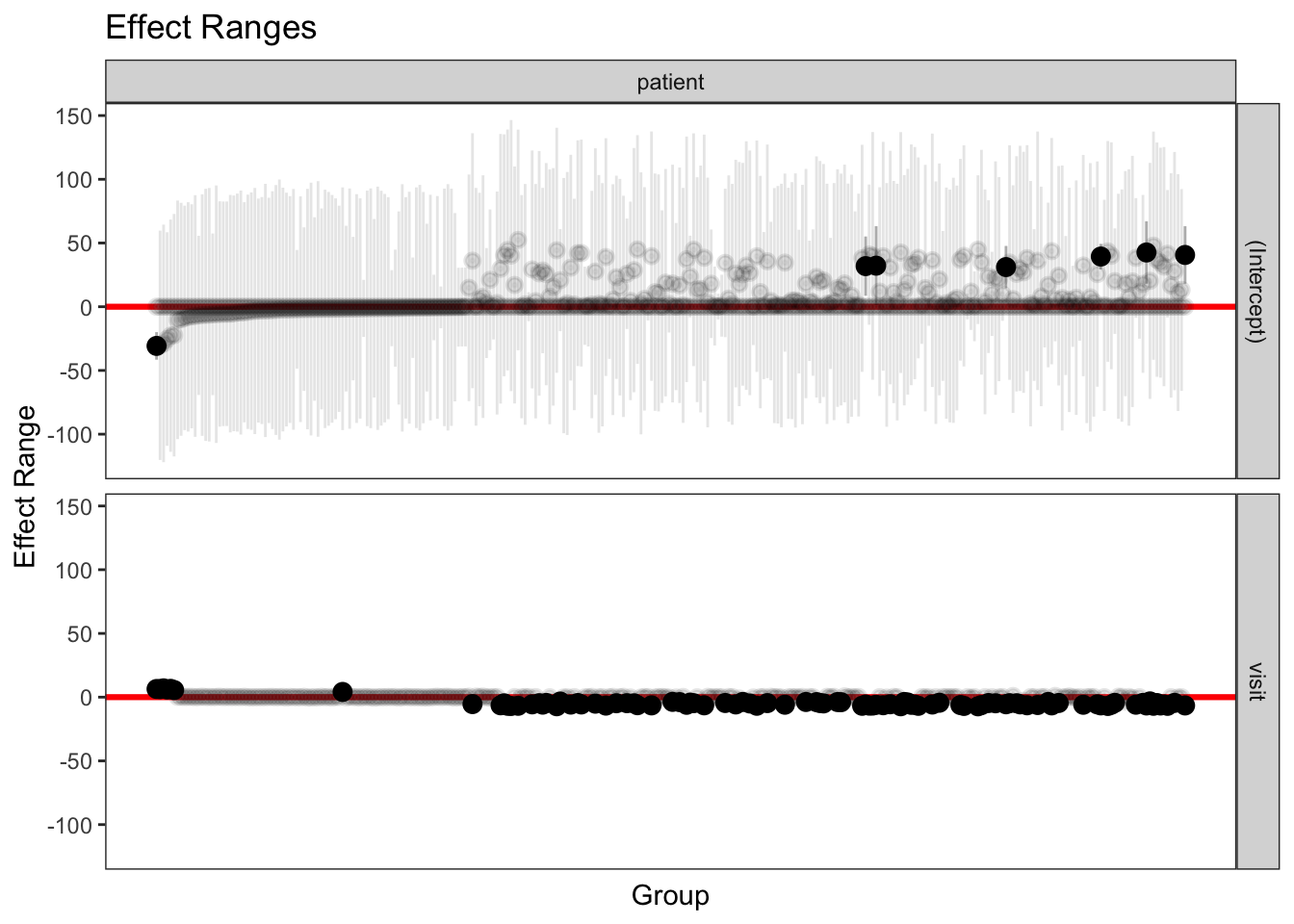
Agora vamos ajustar, o modelo com interceptos e coeficientes aleatórios.
#Ajuste do Modelo Misto com interceptos e coeficientes aleatóriosMML2=glmer(formula = outcome ~ treatment + visit + (1| patient) + (visit | patient),family =binomial(link ="logit"), data = base_unha)summary(MML2)
Generalized linear mixed model fit by maximum likelihood (Laplace
Approximation) [glmerMod]
Family: binomial ( logit )
Formula: outcome ~ treatment + visit + (1 | patient) + (visit | patient)
Data: base_unha
AIC BIC logLik deviance df.resid
977 1016 -482 963 1901
Scaled residuals:
Min 1Q Median 3Q Max
-1.7780 -0.0042 -0.0026 -0.0001 2.5874
Random effects:
Groups Name Variance Std.Dev. Corr
patient (Intercept) 4.76e-02 0.218
patient.1 (Intercept) 2.20e+03 46.902
visit 7.90e+01 8.887 -0.98
Number of obs: 1908, groups: patient, 294
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -10.254 1.025 -10.00 <2e-16 ***
treatmentTerbinafine -1.015 1.042 -0.97 0.33
visit -0.217 0.379 -0.57 0.57
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) trtmnT
trtmntTrbnf -0.281
visit -0.475 0.027
#Calculando OR e seus intervalos de confiançatidy(MML2,conf.int=TRUE,exponentiate=TRUE,effects="fixed") |> dplyr::select(estimate, conf.low, conf.high)