A seguir, abordaremos a execução de uma análise exploratória e modelagem para o conjunto de dados fosfato.dta disponível em Everitt and Hothorn (2003). Estes dados correspondem às medições de fosfato inorgânico no plasma, obtidas a partir de 20 pacientes obesos e 13 controles, em diversos momentos após a administração de glicose oral (com \(t = 0, 30, 60, 90, 120, 150\) minutos).
Respota longitudinal: fosfato inorgâncio.
Variável resposta é quantitativa;
número de pacientes: 33
número de medidas repetidas por paciente (6) - dadosbalanceados;
Total de observações: 198.
Grupos: controle e obesos.
1.1 Análise exploratória
Para iniciarmos, vamos importar a base de dados (que se encontra no formato wide e com extensão .dta). Para tal, crie um projeto no RStudio e depois inclua os dados e o script no projeto. Em seguida, podemos executar os comandos a seguir.
#Ativando pacoteslibrary(haven)library(dplyr)#Importando o banco fosfato.dtabase_fosfato =read_dta(file ="fosfato.dta") #informar o nome do arquivo#Transformando as variáveis qualitativas em fatoresbase_fosfato = base_fosfato |>mutate(grupo =factor(x = grupo, #nome da variávellevels =c(1,2), #valores observados para a variávellabels =c("Controle","Obeso")), #rótulos para os valores observadosid =factor(id))#Visualizando o objetobase_fosfato
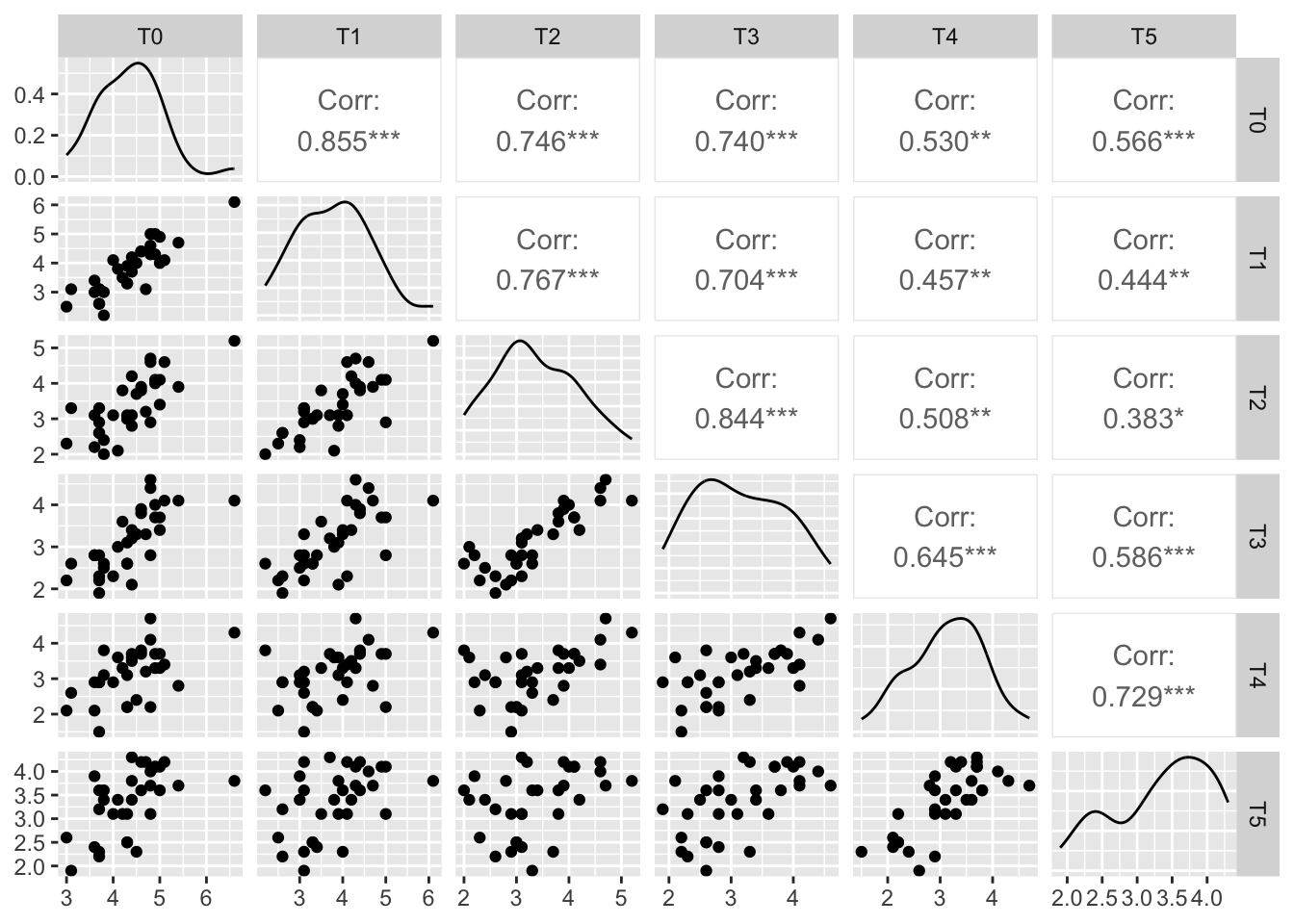
Vamos começar a análise, avaliando a existência de correlação entre a variável resposta medida nos diferentes momentos ao longo do tempo, tanto por meio de gráficos como por meio de medidas numéricas. Para isso, iremos selecionar somente as colunas referentes a variável resposta.
#Ativando pacotelibrary(GGally)#Criando uma base somente com as variáveis T0, T1, T2, T3, T4, T5base_var_resposta = base_fosfato |> dplyr::select(T0, T1, T2, T3, T4, T5) #indicar as variáveis respostas#Criando uma matriz gráfica com as correlaçõesggpairs(data = base_var_resposta)
#Calculando a matriz de correlaçãoM =cor(base_var_resposta)M
Para conduzir análises específicas, será necessário, muitas vezes, modificar o formato da base de dados. As vezes precisaremos dela no formato wide, como foi na análise acima, outras vezes, no formato long. Por isso, é essencial dominar a transição entre os formatos wide e long para executar tais análises com sucesso.
#Ativando pacotelibrary(tidyr)#Transformando uma base wide para long longbase_long = base_fosfato |>gather(key ="Tempo", #nome da variável que irá armazenar o tempovalue ="Fosfato", #nome da variável que irá armazenar a variável resposta3:8)#Visualizando o objetobase_long
#Passar do formato long para o widebase_wide = base_long |>spread(key = Tempo, #variável que dará nomes as colunasvalue = Fosfato) #variável que irá alimentar as colunas criadas#Visualizando o objetobase_wide
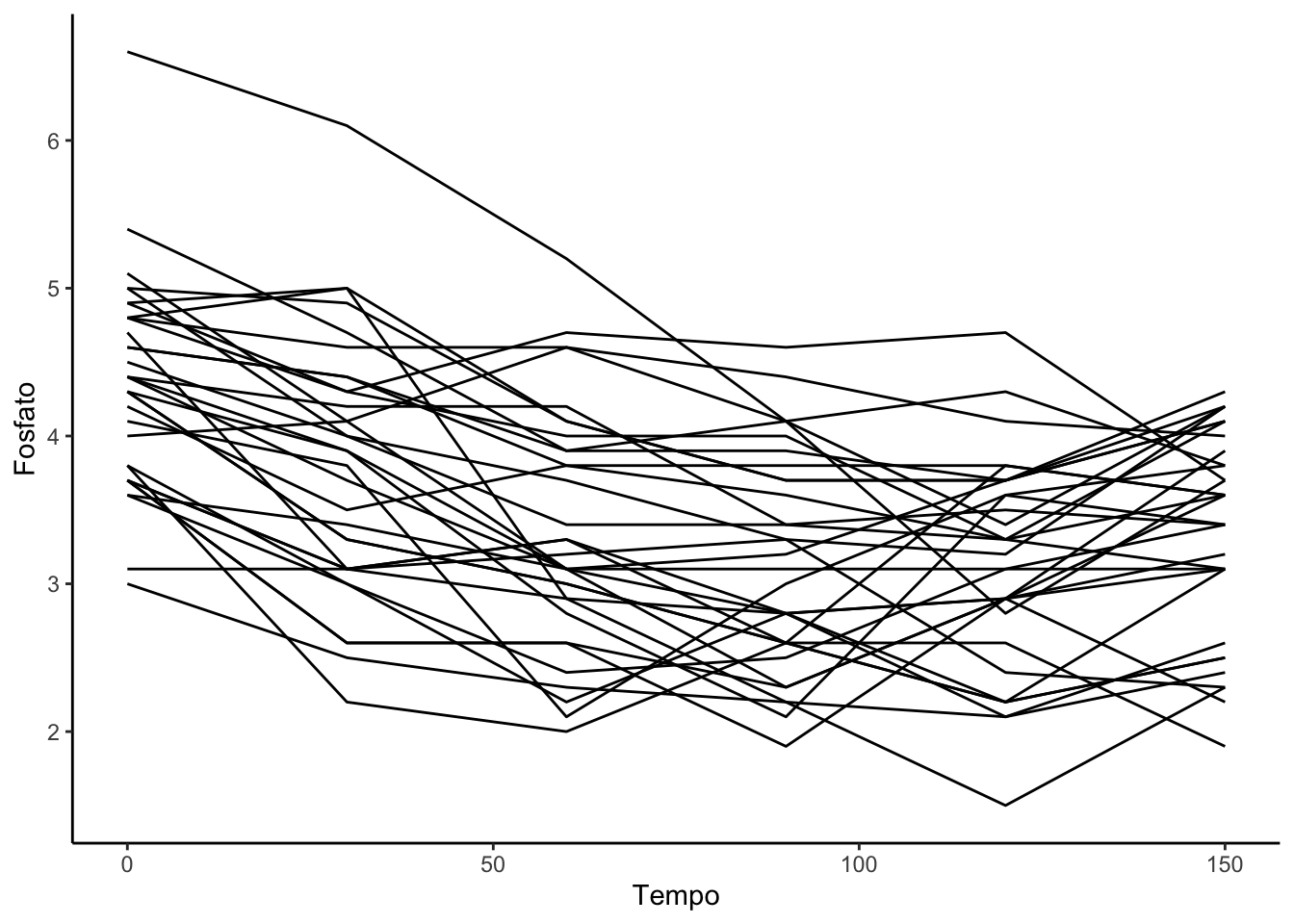
Para criarmos gráficos que descrevem as trajetórias de cada paciente, vamos incialmente incluir uma variável tempo (no formato numérico) na base no formato long.
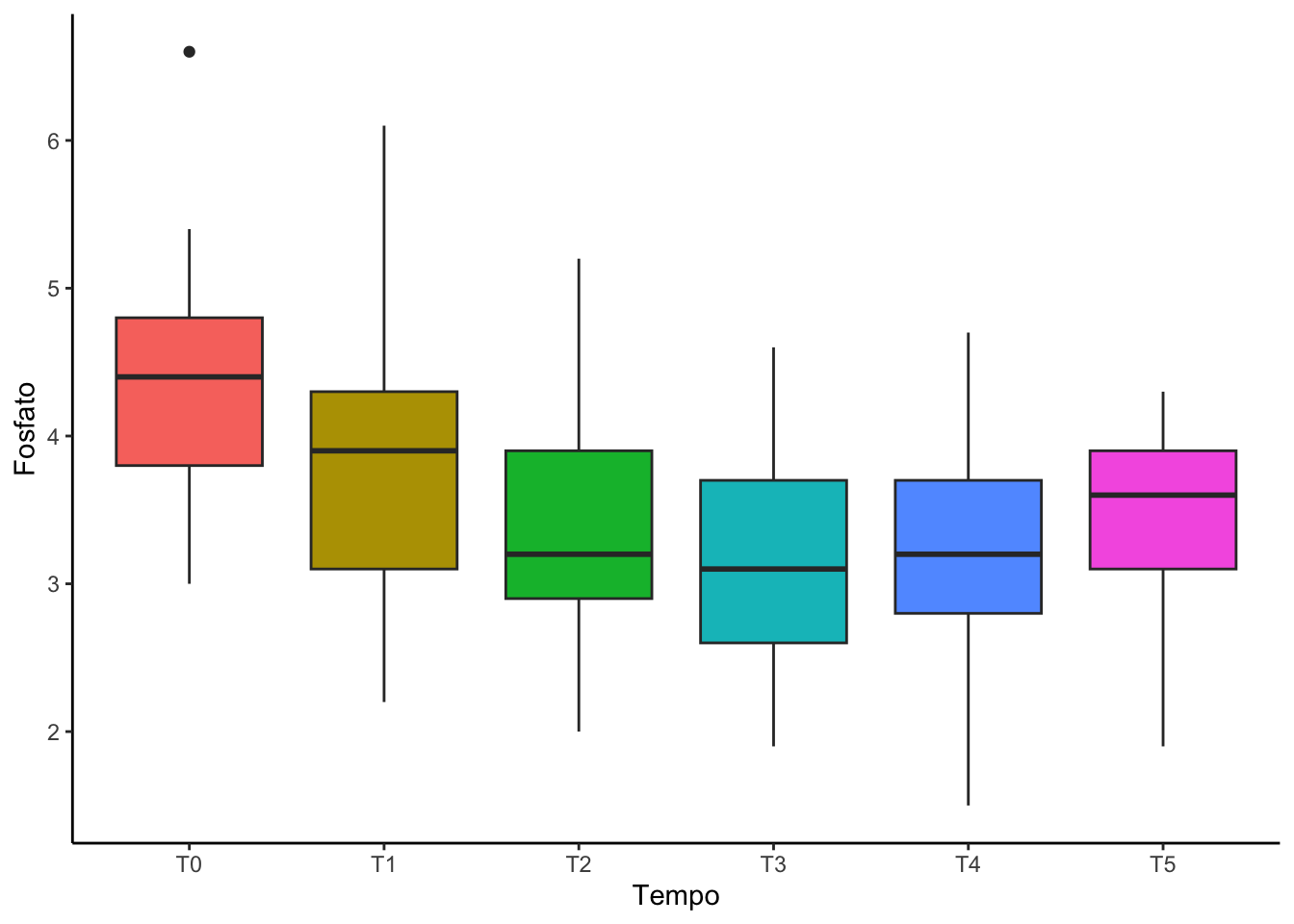
#Criando uma variável numérica para representar o tempobase_long = base_long |>mutate(Tempo_num =c(rep(0,33),rep(30,33),rep(60,33),rep(90,33),rep(120,33),rep(150,33)))#Spaghetti plot individualspaghetti =ggplot(data = base_long,mapping =aes(x = Tempo_num, #variável que indica o tempoy = Fosfato, #indicar variável respostagroup = id)) +#indicar variável que identifica o pacientegeom_line() +theme_classic() +labs(x ="Tempo")spaghetti
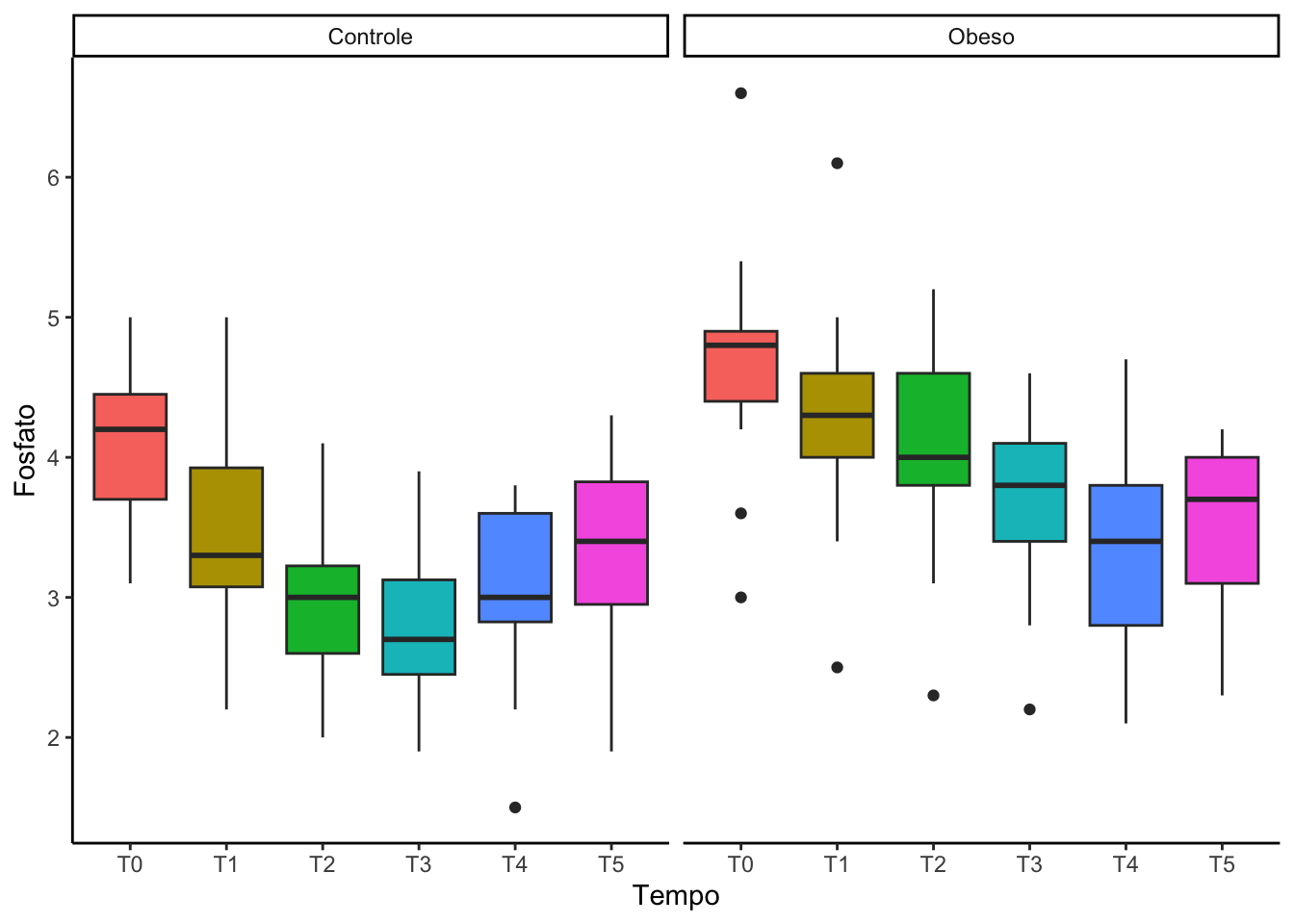
Vamos agora identificar a qual grupo cada trajetória pertence.
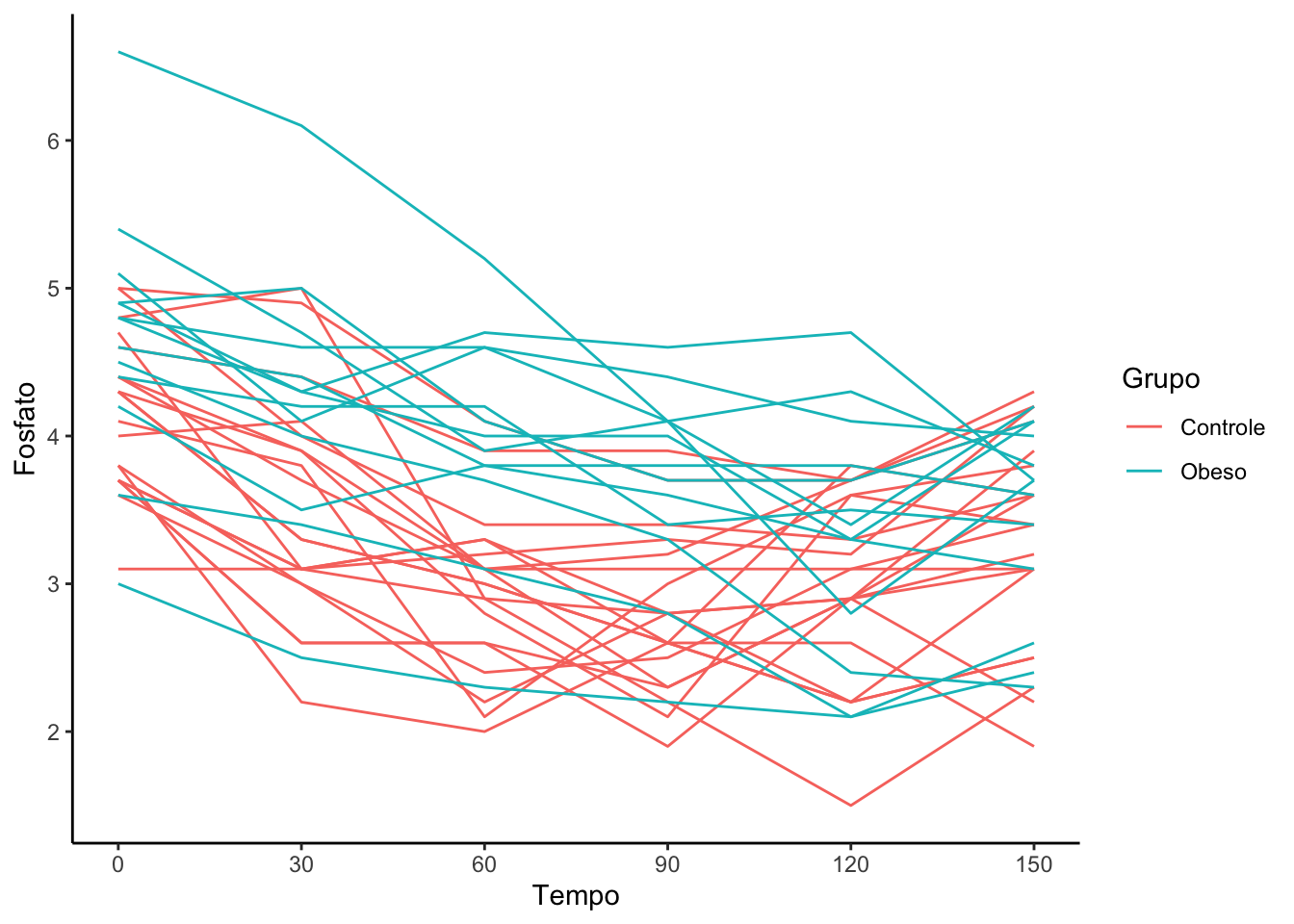
#Spaghetti plot por grupospaghetti_grupo =ggplot(data = base_long,mapping =aes(x = Tempo_num, #variável que indica o tempoy = Fosfato, #indicar variável respostagroup = id, #indicar variável que identifica o pacientecolor = grupo)) +#indicar variável grupogeom_line() +scale_x_continuous(breaks =seq(0,180,30)) +theme_classic() +labs(color ="Grupo",x ="Tempo")spaghetti_grupo
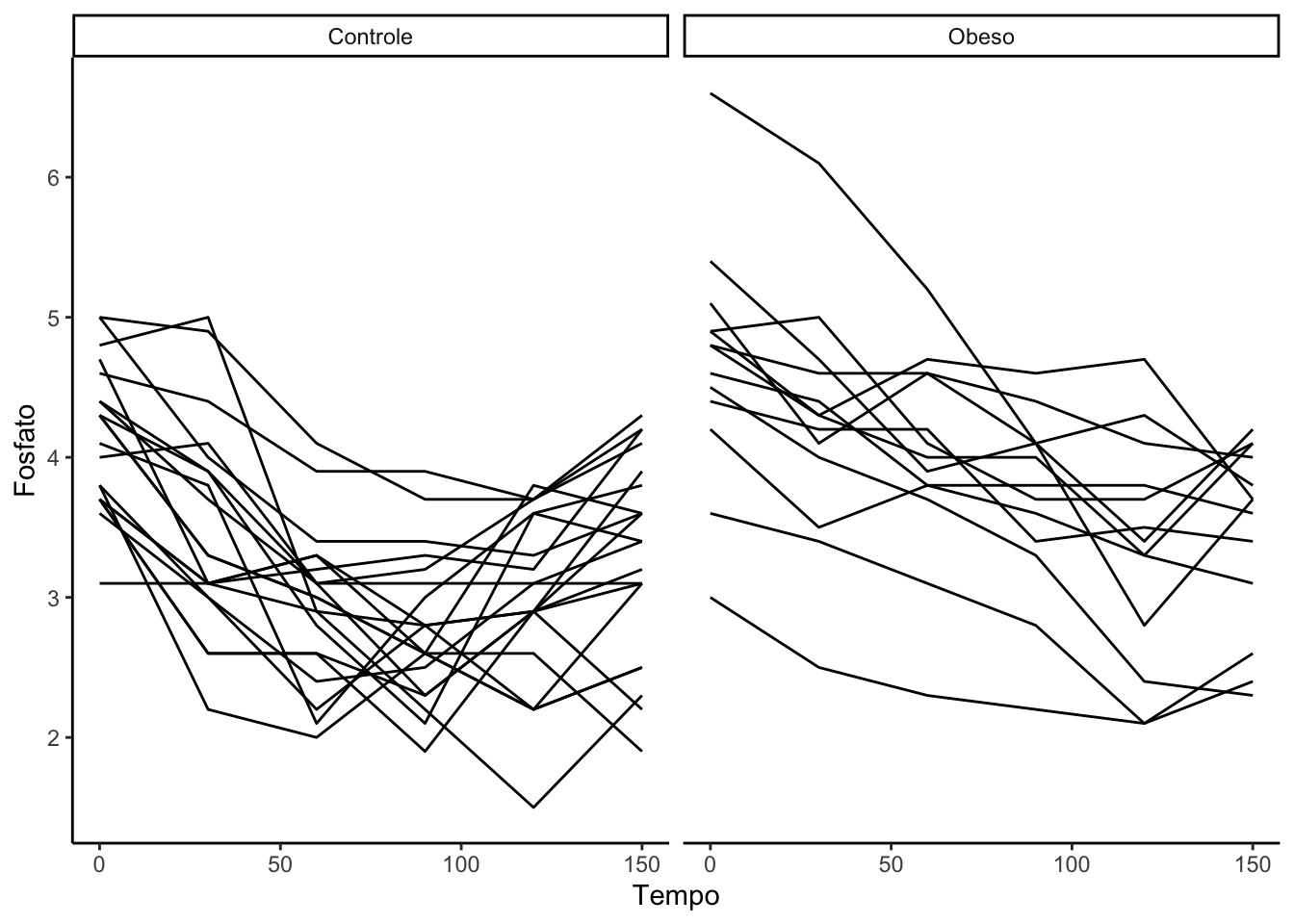
#outra forma de fazer o spaghetti por grupospaghetti +facet_wrap(~grupo)
Vamos criar uma trajetória que represente o comportamento médio de todos os pacientes.
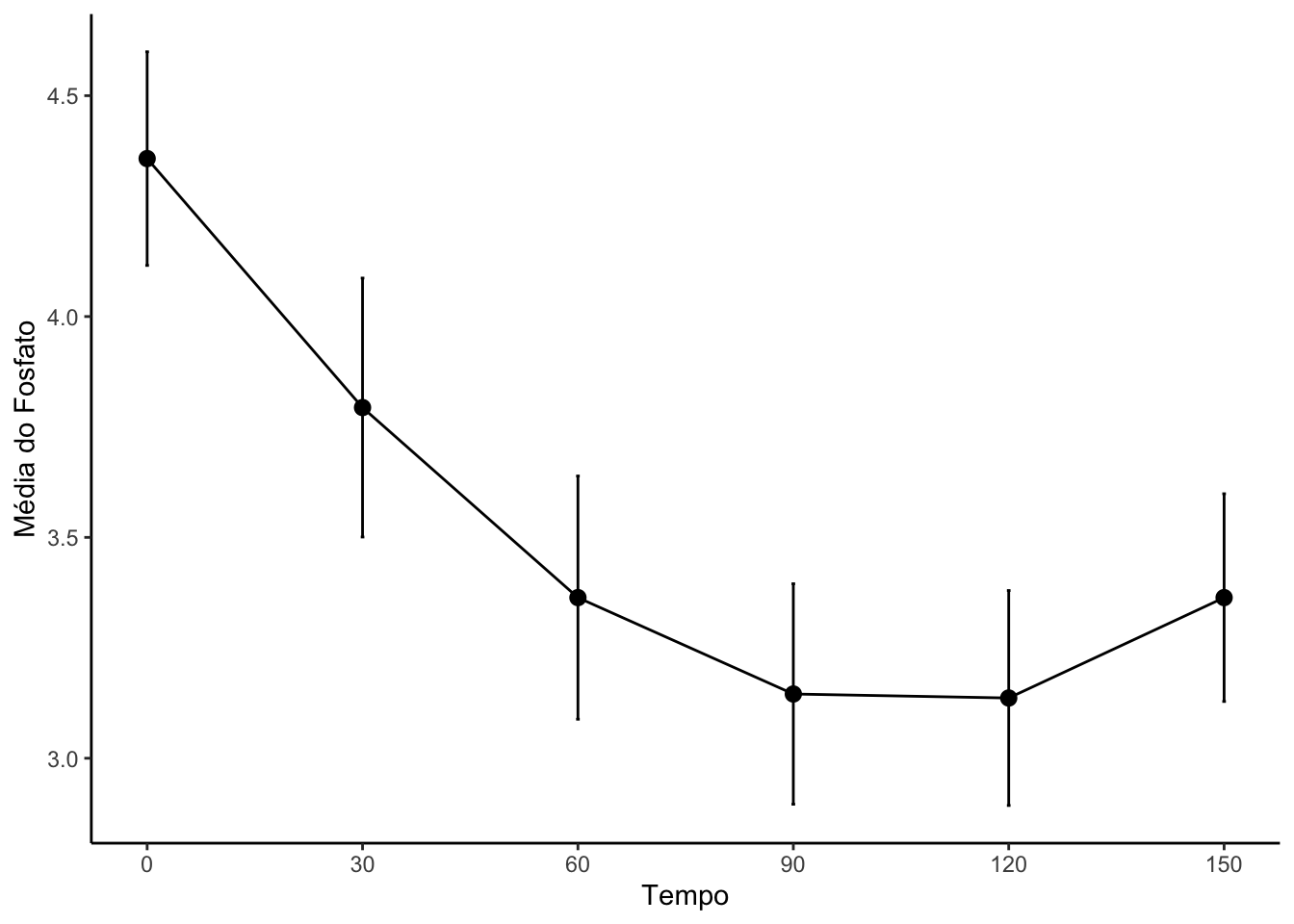
#Criando uma variável tempo (no formato numérico) no objeto resumoGeralresumoGeral = resumoGeral |>mutate(tempo_num =c(0,30,60,90,120,150))#Gráfico com os perfis de médias por tempoperfil_media =ggplot(data = resumoGeral, mapping =aes(x = tempo_num, y = media)) +geom_line() +geom_point(size =2.5) +labs(x ="Tempo", y ="Média do Fosfato") +geom_errorbar(mapping =aes(ymin = IC_LI, ymax = IC_LS), width =0.5) +scale_x_continuous(breaks =seq(0,150,30)) +theme_classic()perfil_media
Também podemos apresentar as trajetórias médias para cada grupo.
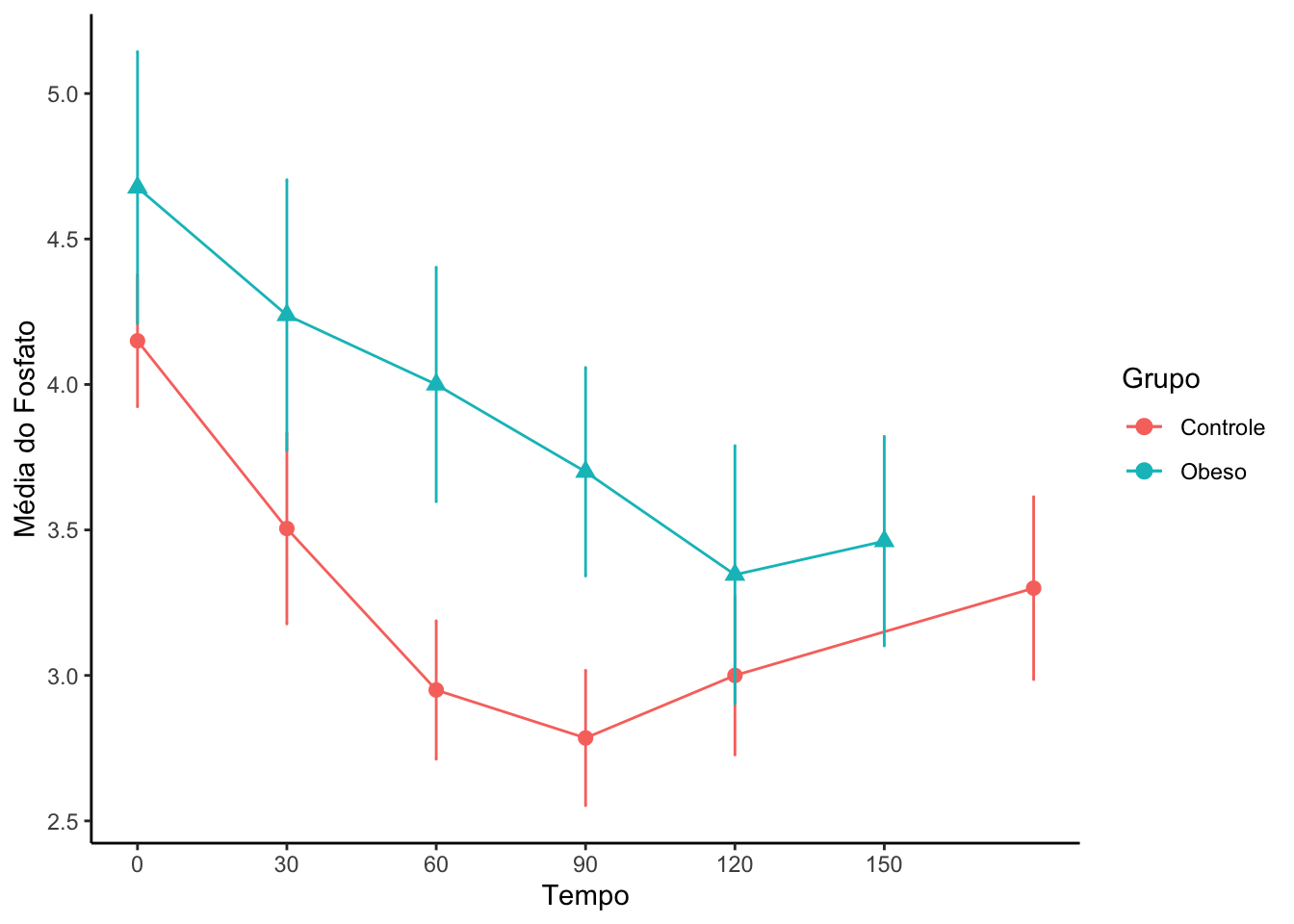
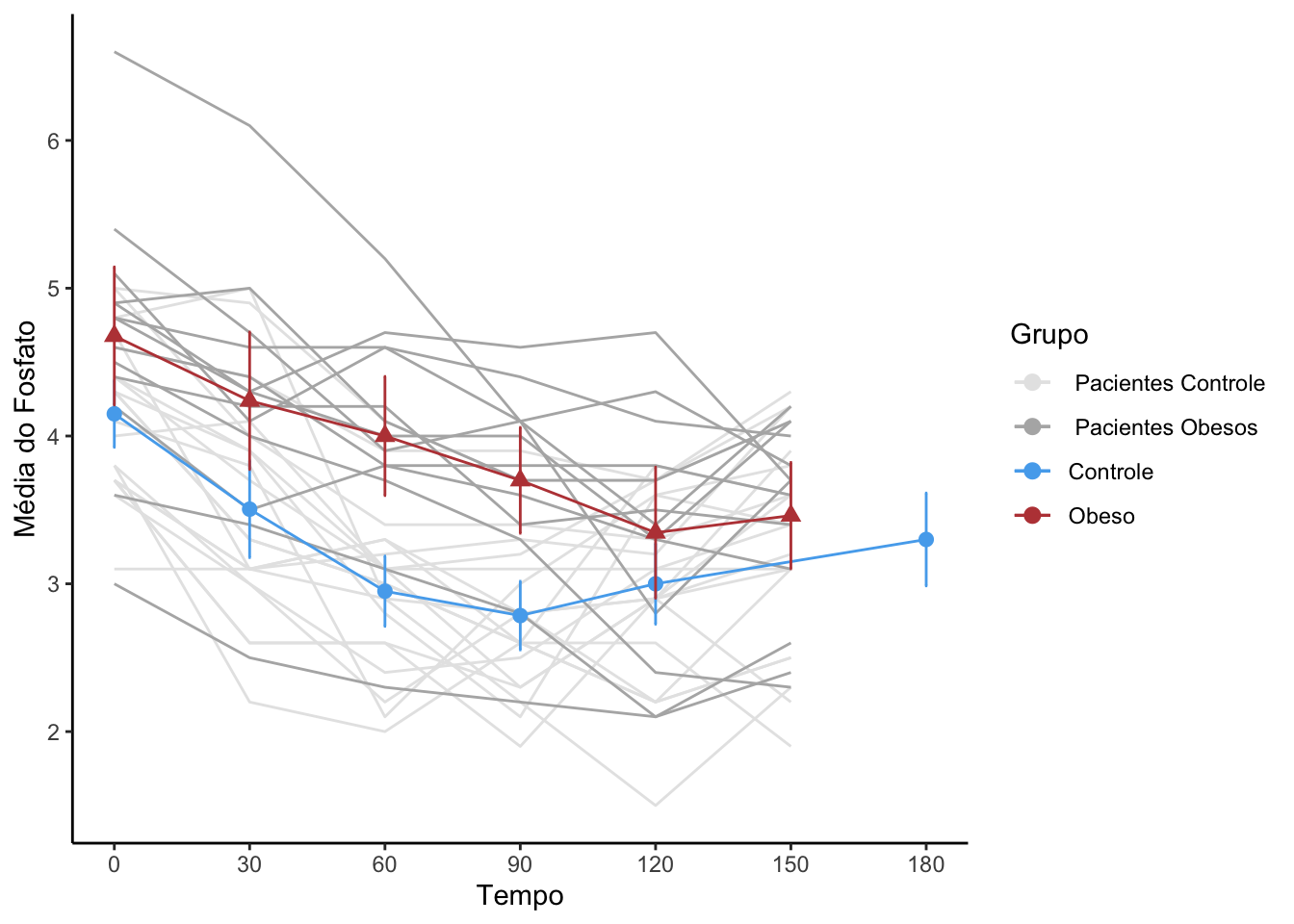
#Criando uma variável tempo (no formato numérico) no objeto resumoGruporesumoGrupo = resumoGrupo |>mutate(tempo_num =c(c(0,30,60,90,120,180),c(0,30,60,90,120,150)))#Gráfico com os perfis de médias por tempo e por grupoperfil_media_grupo =ggplot(data = resumoGrupo, mapping =aes(x = tempo_num, y = media,color = grupo,shape = grupo)) +geom_line() +geom_point(size =2.5) +labs(x ="Tempo", y ="Média do Fosfato",color ="Grupo") +geom_errorbar(mapping =aes(ymin = IC_LI, ymax = IC_LS), width =0.5) +scale_x_continuous(breaks =seq(0,150,30)) +guides(shape ="none") +theme_classic()perfil_media_grupo
É possível ainda incluir as trajetórias individuais e as médias em um mesmo gráfico.
#Gráfico com os perfis de médias por tempo e por grupo com o spaghettiperfil_media_grupo_spag =ggplot(data = resumoGrupo, mapping =aes(x = tempo_num,y = media,color = grupo,shape = grupo)) +geom_line(data = base_long |>filter(grupo =="Controle"),mapping =aes(x = Tempo_num, y = Fosfato, group = id, color=" Pacientes Controle")) +geom_line(data = base_long |>filter(grupo =="Obeso"),mapping =aes(x = Tempo_num, y = Fosfato, group = id, color=" Pacientes Obesos")) +geom_line() +geom_point(size =2.5) +labs(x ="Tempo", y ="Média do Fosfato",color ="Grupo") +geom_errorbar(mapping =aes(ymin = IC_LI, ymax = IC_LS), width =0.5) +scale_x_continuous(breaks =seq(0,180,30)) +scale_color_manual(values =c("grey90", "grey70", "#55acee", "#bb4444")) +guides(shape=FALSE) +theme_classic()perfil_media_grupo_spag
1.2 Modelagem
1.2.1 GEE
Vamos iniciar construindo um modelo marginal: Equações de Estimação Generalizada (GEE). Para especificar o modelo é preciso defirnir:
a distribuição de probabilidade da variável resposta (família).
a função de ligação.
a estrutura de correlação.
#Vamos inicialmente criar a variável tempo - média do tempo e esta medida ao quadradobase_long = base_long |>mutate(minC = Tempo_num -mean(Tempo_num, na.rm =TRUE),min2C = minC*minC)#Ativando pacotelibrary(geepack)#Ajustando o modelo com estrutura de correlação exchangeablegeeEXC =geeglm(formula = Fosfato ~ minC + min2C + grupo, #indicar a variável resposta ~ indicar as variáveis explicativasid = id, #variável que identifica os pacientesdata = base_long, family =gaussian(link ="identity"), #definição da variável resposta e função de ligaçãocorstr ="exchangeable") #definição da estrutura de correlaçãosummary(geeEXC)
#Ajustando o modelo com estrutura de correlação ar1geeAR1 =geeglm(formula = Fosfato ~ minC + min2C + grupo, #indicar a variável resposta ~ indicar as variáveis explicativasid = id, #variável que identifica os pacientesdata = base_long, #definição da variável resposta e função de ligaçãofamily =gaussian(link ="identity"), #definição da variável resposta e função de ligaçãocorstr ="ar1") #definição da estrutura de correlaçãosummary(geeAR1)
#Ativando pacotelibrary(lme4)MMG =lmer(formula = Fosfato ~ minC + min2C + grupo + (1| id), #indicar a variável resposta ~ indicar as variáveis explicativas (1 | variável que identifica o paciente) é a forma de incluir o intercepto aleatóriodata = base_long)summary(MMG)
Linear mixed model fit by REML ['lmerMod']
Formula: Fosfato ~ minC + min2C + grupo + (1 | id)
Data: base_long
REML criterion at convergence: 355
Scaled residuals:
Min 1Q Median 3Q Max
-2.3611 -0.5946 0.0425 0.5384 2.8970
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 0.274 0.523
Residual 0.206 0.454
Number of obs: 198, groups: id, 33
Fixed effects:
Estimate Std. Error t value
(Intercept) 2.99e+00 1.30e-01 23.03
minC -6.82e-03 6.29e-04 -10.84
min2C 1.12e-04 1.44e-05 7.79
grupoObeso 6.22e-01 1.98e-01 3.15
Correlation of Fixed Effects:
(Intr) minC min2C
minC 0.000
min2C -0.291 0.000
grupoObeso -0.601 0.000 0.000
fit warnings:
Some predictor variables are on very different scales: consider rescaling
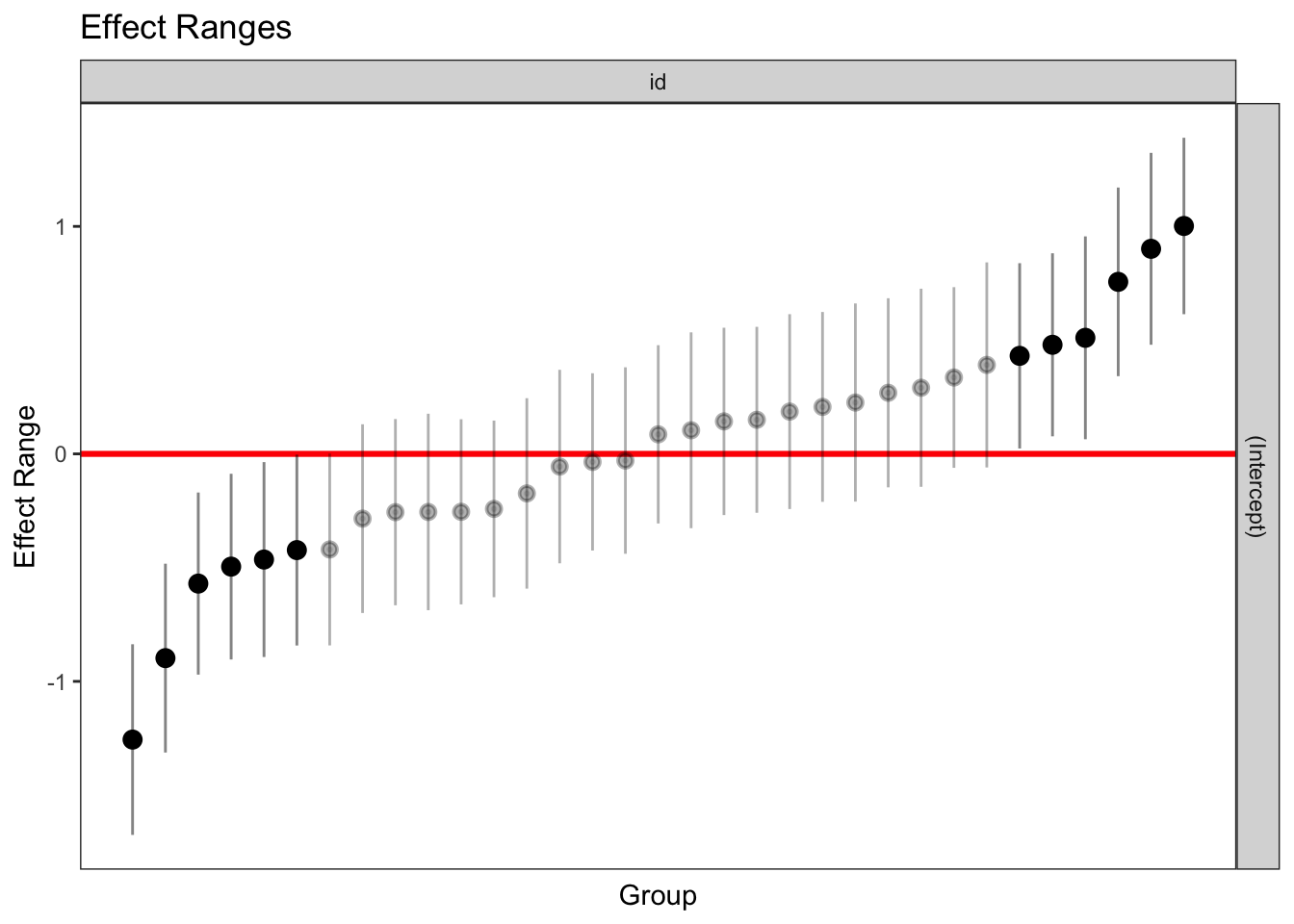
#Ativando pacotelibrary(merTools)#Plotando estimativa pontual e intervalar dos interceptos aleatóriosplotREsim(REsim(MMG)) # plot the interval estimates
Everitt, Brian S., and Torsten Hothorn. 2003. A Handbook of Statistical Analyses Using r.