A seguir, vamos discutir a implementação do modelo Poisson Condicional retirado do artigo Barrera-Gómez et al. (2023).
1.1 Problema
Entender o impacto da temperatura (controlando por outros confundidores) no número de acidentes de veículos (dados sintéticos similares aos dos autores usado no artigo).
Período: 15/05/2005 a 15/10/2011.
Base de dados:
Número de acidentes de veículos automotores em uma data específica.
Data.
Zona climática.
Temperatura máxima do dia em graus Celsius (exposição).
Indicador de feriados (0=não; 1=sim).
Indicador de o dia estar no início ou no fim de um período de feriado (0=não; 1=sim).
Indicador de precipitação nesse dia (0=não; 1=sim).
1.2 Estrutura dos Dados
Os dados estão aninhados em 3 níveis:
Nível 1: existem \(I=14\) regiões geográficas.
Nível 2: Para cada zona \(i\) existem \(J_i\) estratos temporais (combinação de ano, mês e dia da semana).
Nível 3: Para cada estrato de tempo \(j\) na zona \(i\) existem \(K_{ij}\) observações (dias).
Notação das variáveis
\(Y_{ijk}\) é o número de casos de casos de acidentes de veículos automotores, observado no dia \(k\), no estrato de tempo \(j\), na zona \(i\).
\(X_{lijk}\) é a \(l-\)ésima variável explicativa associada a \(Y_{.ijk}\).
1.3 Modelo Poisson Misto
O artigo de Barrera-Gómez et al. (2023) propõe um modelo de regressão de Poisson condicional com um coeficiente angular aleatório.
Para ajustar o modelo acima sob a abordagem Bayesiana, precisamos completar a especificação do modelo por meio das distribuições a priori para os parâmetros.
#Ativando pacoteslibrary(readxl)library(lubridate)library(stringr)library(bayesplot)library(ggplot2)library(R2jags)# -------------------------- ## Importando a base de dados ## -------------------------- ##Carregando os dados:load("crash.RData")# Visualizando os dadoshead(crash)
zone date n_accidents_human temp_max
Min. : 1.0 Min. :2000-05-15 Min. : 0.000 Min. : 5.50
1st Qu.: 4.0 1st Qu.:2003-03-23 1st Qu.: 0.000 1st Qu.:22.50
Median : 7.5 Median :2006-01-29 Median : 0.000 Median :26.00
Mean : 7.5 Mean :2006-01-29 Mean : 1.512 Mean :25.59
3rd Qu.:11.0 3rd Qu.:2008-12-07 3rd Qu.: 2.000 3rd Qu.:29.18
Max. :14.0 Max. :2011-10-15 Max. :31.000 Max. :39.88
NA's :770 NA's :770
holi event prec01
Min. :0.00000 Min. :0.00000 Min. :0.0000
1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.0000
Median :0.00000 Median :0.00000 Median :0.0000
Mean :0.03842 Mean :0.05682 Mean :0.4242
3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:1.0000
Max. :1.00000 Max. :1.00000 Max. :1.0000
NA's :81
Agora vamos incluir na base de dados a variável de estrato, que será denominada zone_ymd.
# ---------------- ## Criando estratos# ---------------- ## Criando a variavel ano a partir da datayear <-year(crash$date)# Criando a variavel mês a partir da data com dois digitosmonth <-str_pad(month(crash$date), 2, pad ="0")# Criando a variavel dia da semana a partir da datadow <-wday(crash$date, week_start =1)#Concatenando ano, mes e dia da semanaymd <-paste(year, month, dow, sep ="_")# Concatenando a zona em ymd (estrato)crash$zone_ymd <-as.factor(paste(str_pad(crash$zone, 2, pad ="0"), as.factor(ymd), sep ="_")) # Removendo os objetos que não serão utilizadosrm(year, month, dow, ymd)# Resumindo os dados summary(crash)
zone date n_accidents_human temp_max
Min. : 1.0 Min. :2000-05-15 Min. : 0.000 Min. : 5.50
1st Qu.: 4.0 1st Qu.:2003-03-23 1st Qu.: 0.000 1st Qu.:22.50
Median : 7.5 Median :2006-01-29 Median : 0.000 Median :26.00
Mean : 7.5 Mean :2006-01-29 Mean : 1.512 Mean :25.59
3rd Qu.:11.0 3rd Qu.:2008-12-07 3rd Qu.: 2.000 3rd Qu.:29.18
Max. :14.0 Max. :2011-10-15 Max. :31.000 Max. :39.88
NA's :770 NA's :770
holi event prec01 zone_ymd
Min. :0.00000 Min. :0.00000 Min. :0.0000 01_2000_06_4: 5
1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.0000 01_2000_06_5: 5
Median :0.00000 Median :0.00000 Median :0.0000 01_2000_07_1: 5
Mean :0.03842 Mean :0.05682 Mean :0.4242 01_2000_07_6: 5
3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:1.0000 01_2000_07_7: 5
Max. :1.00000 Max. :1.00000 Max. :1.0000 01_2000_08_2: 5
NA's :81 (Other) :25842
Próximo passo? É preciso organizar os dados em um formato específico para a realização do ajuste do modelo.
Os autores forneceram uma função chamada multinomdata que faz essa organização dos dados automaticamente. Para que a mesma funcione, é preciso deixar seus dados no mesmo formato dos autores: nível 1 é o espaço geográfico, o nível 2 é o tempo e o nível 3 é o dia dentro de cada estrato temporal em cada zona.
Os argumentos da função são:
data - o data.frame com os dados.
X - Vetor de caracteres com os nomes das variáveis explicativas. Assume-se que a primeira corresponde à exposição de interesse. Todas as variáveis devem ser numéricas.
Y - nome da variável desfecho entre aspas (como encontra-se em data).
i - variável que indica o nível 1 dos dados (neste caso a variável espacial - deve ser numérica).
ij - variável que indica o nível 2 dos dados (neste caso a variável deve ser um fator).
# -------------------------- ## Modelo Poisson Condicional# -------------------------- ## definindo as variáveis explicativas (a primeira é a exposição de interesse): Xnames <-c("temp_max", "holi", "event", "prec01")# Organizando os dados no formato apropriado para o modelo definido no BUGS:source("Multinomdata.R")ddmultinom <-multinomdata(data = crash, #a base de dadosX = Xnames,Y ="n_accidents_human",i ="zone",ij ="zone_ymd")
A saída da função multinomdata é uma lista contendo vários elementos.
A seguir vamos entender cada um dos componentes do objeto ddmultinom.
Ymat é uma matriz com tantas linhas quantas forem as distribuições multinomiais (ou seja, estratos de zona-tempo) e tantas colunas quanto o tamanho máximo das distribuições multinomiais.
Os números representam contagens de desfechos observados em cada categoria (ou seja, estrato de zona-tempo) da distribuição.
dim(ddmultinom$Ymat)
[1] 4671 5
head(ddmultinom$Ymat)
[,1] [,2] [,3] [,4] [,5]
[1,] 0 1 2 NA NA
[2,] 0 0 1 NA NA
[3,] 0 2 1 NA NA
[4,] 0 2 NA NA NA
[5,] 1 1 NA NA NA
[6,] 1 0 NA NA NA
Svector é um vetor numérico que inclui o tamanho de cada distribuição multinomial (ou seja, a soma das contagens de desfechos dentro de cada estrato):
X1mat, X2mat, ... : tantas matrizes quanto o número de variáveis passadas em X, respectivamente. Mesma dimensão e padrão de ausência estrutural que o de Ymat.
Os números em cada matriz representam os valores observados da variável correspondente em cada categoria da distribuição multinomial.
Inclui NA estrutural em coerência com Ymat:
dim(ddmultinom$X1mat)
[1] 4671 5
head(ddmultinom$X1mat)
[,1] [,2] [,3] [,4] [,5]
[1,] 26.78 22.59 27.47 NA NA
[2,] 26.87 25.81 29.97 NA NA
[3,] 23.95 27.35 31.24 NA NA
[4,] 24.63 26.96 NA NA NA
[5,] 22.55 27.56 NA NA NA
[6,] 21.30 22.39 NA NA NA
ivector é um vetor numérico indicando a zona a que cada distribuição multinomial pertence.
Kvector é um vetor numérico indicando o número de categorias em cada distribuição multinomial (ou seja, o número de observações dentro de cada estrato de zona-tempo).
Os valores são coerentes com o número de NA em cada linha de Ymat.
length(ddmultinom$Kvector)
[1] 4671
head(ddmultinom$Kvector)
[1] 3 3 3 2 2 2
table(ddmultinom$Kvector)
2 3 4 5
945 421 2100 1205
N é um número inteiro indicando o número de distribuições multinomiais (ou seja, o número de estratos de zona-tempo) utilizados para ajustar o modelo:
ddmultinom$N
[1] 4671
I é um número inteiro indicando o número de zonas:
ddmultinom$I
[1] 14
Em seguida, temos o código que especifica o modelo definido acima e que usará os componentes criados pela função multinomdata.
Após o ajuste do modelo, é preciso verificar se houve convergência das cadeias. Inicialmente iremos fazer uma inspeção visual das duas cadeias geradas.
# Extraindo as cadeias dos parâmetrossamples <-as.mcmc(modmultinomial)#Plotando as cadeias dos betas e sigma1trace_plot_beta <-mcmc_trace(x = samples,pars =c("beta1","beta2","beta3","beta4","sigma1"),facet_args =list(ncol =2))trace_plot_beta
#Plotando as cadeias de alguns u1trace_plot_u <-mcmc_trace(x = samples,pars =c("u1[1]","u1[5]","u1[9]","u1[12]"),facet_args =list(ncol =2))trace_plot_u
Outra característica importante é avaliar o comportamento das autocorrelações em uma cadeia. A seguir, criamos os gráficos usando somente a cadeia 1.
#Plotando o gráfico de autocorrelação dos betas e sigma1 acf_plot_beta <-mcmc_acf(x = samples[[1]],pars =c("beta1","beta2","beta3","beta4","sigma1"),facet_args =list(ncol =2))acf_plot_beta
#Plotando o gráfico de autocorrelação de alguns u1acf_plot_u <-mcmc_acf(x = samples[[1]],pars =c("u1[1]","u1[5]","u1[9]","u1[12]"),facet_args =list(ncol =2))acf_plot_u
Percebemos um problema de convergência, especialmente com o parâmetro \(\beta_1\). Vamos modificar as configuraçòes do ajuste do MCMC.
### Definições do ajuste (número de cadeias, interações, período de aquecimento e espaçamentopara o MCMC): Chain <-2Iter <-2000Burn <-1000Thin <-4
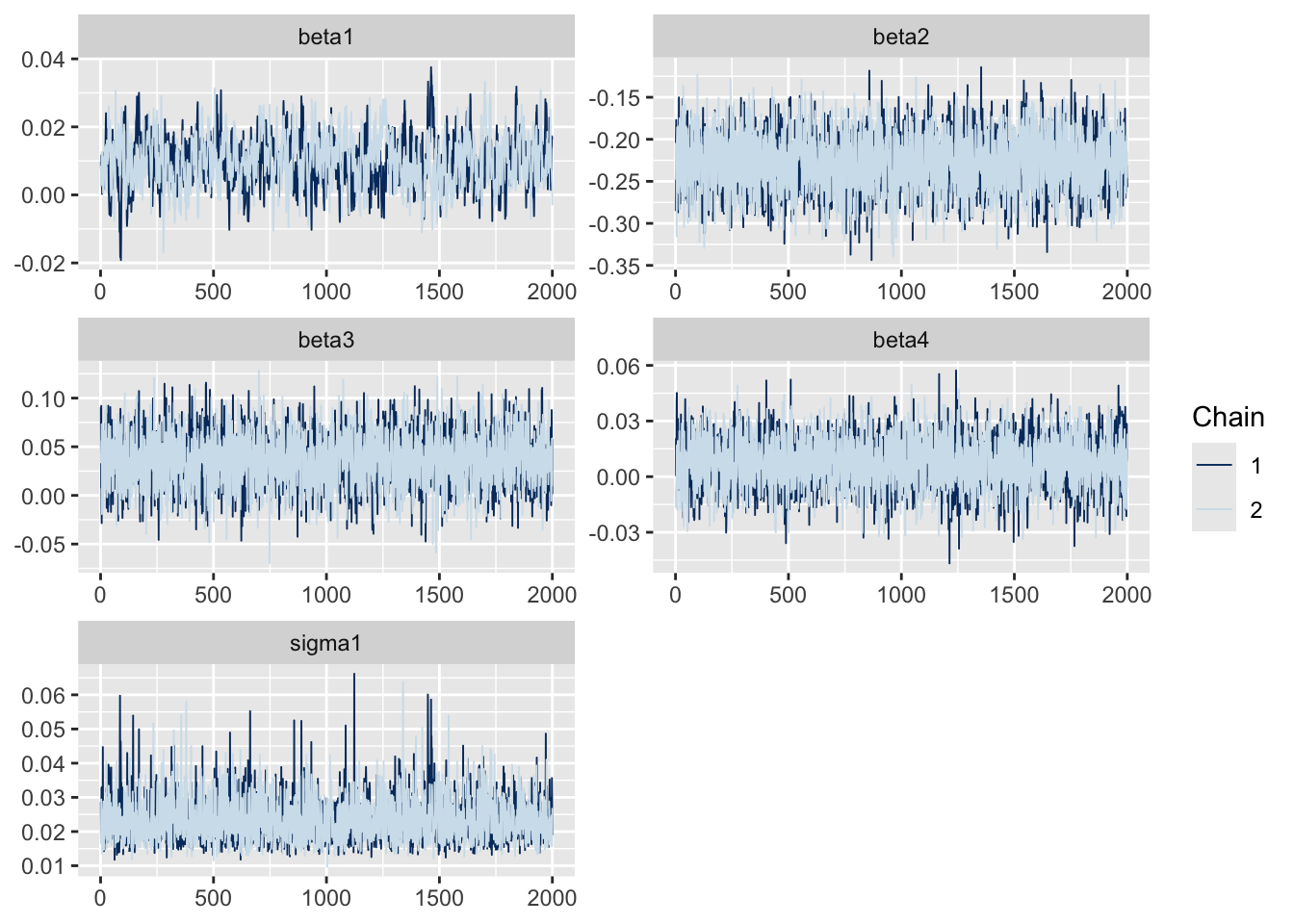
Ajustando novamente o MCMC com a nova configuração. Cuidado! Maior custo computacional.
# Extraindo as cadeias dos parâmetrossamples <-as.mcmc(modmultinomial)#Plotando as cadeias dos betas e sigma1trace_plot_beta <-mcmc_trace(x = samples,pars =c("beta1","beta2","beta3","beta4","sigma1"),facet_args =list(ncol =2))trace_plot_beta
#Plotando as cadeias de alguns u1trace_plot_u <-mcmc_trace(x = samples,pars =c("u1[1]","u1[5]","u1[9]","u1[12]"),facet_args =list(ncol =2))trace_plot_u
Outra forma de verificar convergência das cadeiais é usando a estatística Rhat.
### Todos os parâmteros possuem Rhat < 1.05?all(modmultinomial$BUGSoutput$summary[, "Rhat"] <1.05)
[1] TRUE
Vamos avaliar as autocorrelações com essa nova configuração do MCMC.
#Plotando o gráfico de autocorrelação dos betas e sigma1 acf_plot_beta <-mcmc_acf(x = samples[[1]],pars =c("beta1","beta2","beta3","beta4","sigma1"),facet_args =list(ncol =2))acf_plot_beta
#Plotando o gráfico de autocorrelação de alguns u1acf_plot_u <-mcmc_acf(x = samples[[1]],pars =c("u1[1]","u1[5]","u1[9]","u1[12]"),facet_args =list(ncol =2))acf_plot_u
Como as cadeias mostram convergência, podemos agora fazer inferência sobre os parâmetros. Como?
# Gráfico de histogramas das amostras dos betas e sigma1hist_plot_beta <-mcmc_hist(x = samples,pars =c("beta1","beta2","beta3","beta4","sigma1"),facet_args =list(ncol =2))hist_plot_beta
# Gráfico de histogramas de alguns u1hist_plot_u <-mcmc_hist(x = samples,pars =c("u1[1]","u1[5]","u1[9]","u1[12]"),facet_args =list(ncol =2))hist_plot_u
A seguir apresentamos estimativas pontual e intervalar para todos os parâmetros do modelo.
#Um resumo simples das distribuições a posteriori print(modmultinomial, digits =3)
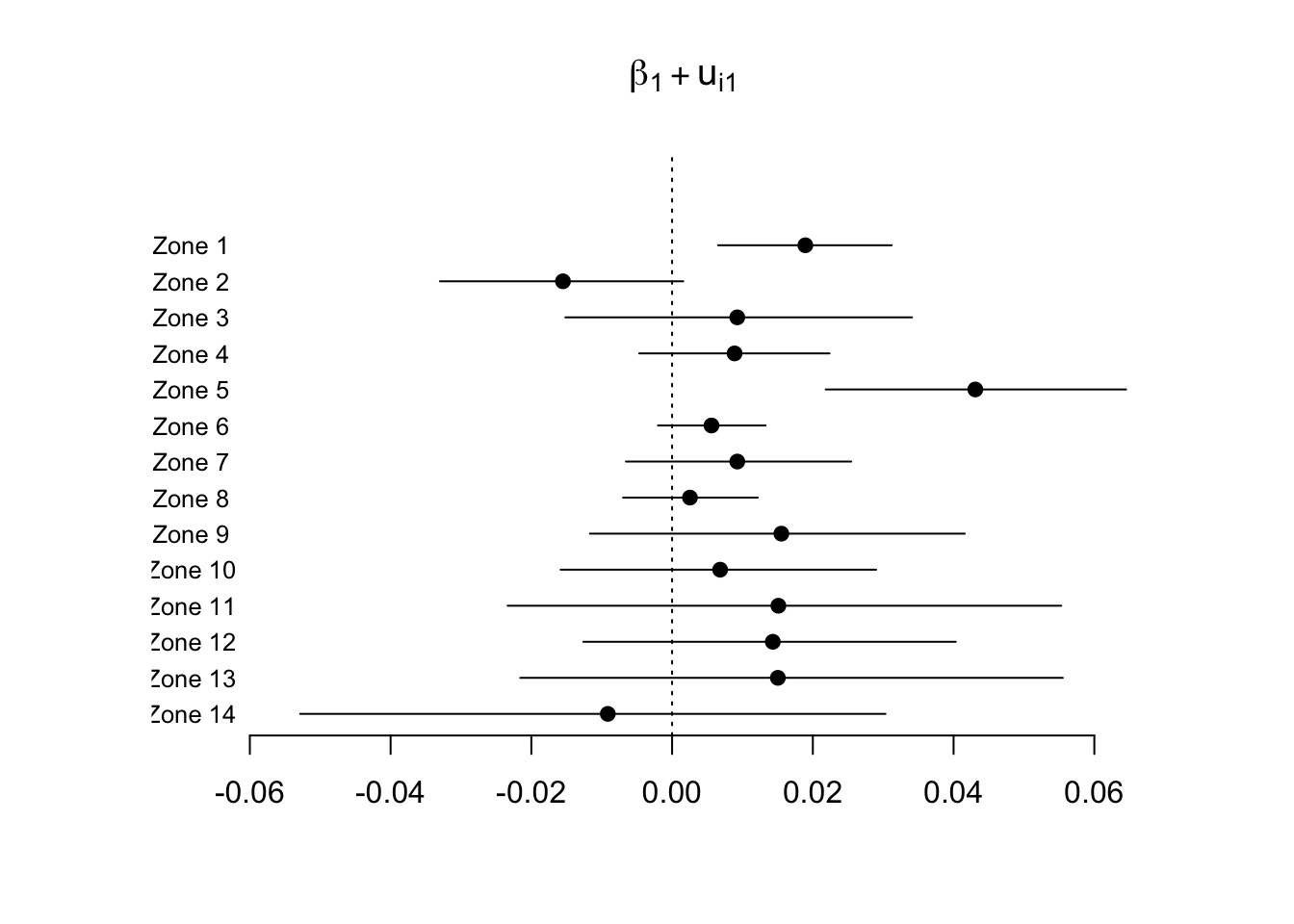
A seguir apresentamos como construir um gráfico com a estimativa pontual e intervalar para \(\beta_1 + u_1\).
# lista com as amostras das distribuições a posteriori simslist <- modmultinomial$BUGSoutput$sims.list# amostra de beta1 beta1sims <- simslist[["beta1"]]# amostra de u1 u1sims <- simslist[["u1"]]# número de zonasI <-dim(u1sims)[2]# amostra de (beta1 + u1):beta1isims <-apply(u1sims, 2, FUN =function(x) return(x + beta1sims))# Gráficoxlim1 <-min(apply(beta1isims, 2, FUN =function(x) quantile(x, prob =0.005))) xlim2 <-max(apply(beta1isims, 2, FUN =function(x) quantile(x, prob =0.995))) plot(c(xlim1, xlim2), c(0, I +1), type ="n", bty ="n", xlab ="", ylab ="",main =expression(beta[1] + u[i1]), yaxt ="n")abline(v =0, lty =3)# média e intervalo de credibilidade de 95%estbeta1i <-t(apply(beta1isims, 2,FUN =function(x) c(mean(x), quantile(x, probs =c(0.025, 0.975))))) # plota a média:points(estbeta1i[, 1], I -1:I, pch =19)# plota o intervalo de credibilidade:segments(estbeta1i[, 2], I -1:I, estbeta1i[, 3], I -1:I)# print labels:text(xlim1, I -1:I, paste("Zone", 1:I), cex =0.8)
Por fim, os autores forneceram uma função que retorna a média e o intervalo de credibilidade de 95% para \(\beta_1\) e RR geral e específico de cada zona. A funçao possui três argumentos, são eles:
model: o modelo ajustado com JAGS ou WinBUGS.
deltaE: o aumento no nível de exposição para o qual o RR deve ser calculado.
credible: percentual para os intervalos de credibilidade. O padrão é 95.
# RR associated to a "deltatemp" degrees increase in temperature:# increase in temperature to compute RR:deltatemp <-5source("getassoc.R")rr1stageind <-getassoc(model = modmultinomial,deltaE = deltatemp,credible =95)rr1stageind
Barrera-Gómez, J., X. Puig, J. Ginebra, and X. Basagañaa. 2023. “Conditional Poisson Regression with Random Effects for the Analysis of Multi-Site Time Series Studies.”Epidemiology 34 (5): 873–78.